 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePSVMA+: Exploring Multi-granularity Semantic-visual Adaption for Generalized Zero-shot Learning
Oct 15, 2024



Generalized zero-shot learning (GZSL) endeavors to identify the unseen categories using knowledge from the seen domain, necessitating the intrinsic interactions between the visual features and attribute semantic features. However, GZSL suffers from insufficient visual-semantic correspondences due to the attribute diversity and instance diversity. Attribute diversity refers to varying semantic granularity in attribute descriptions, ranging from low-level (specific, directly observable) to high-level (abstract, highly generic) characteristics. This diversity challenges the collection of adequate visual cues for attributes under a uni-granularity. Additionally, diverse visual instances corresponding to the same sharing attributes introduce semantic ambiguity, leading to vague visual patterns. To tackle these problems, we propose a multi-granularity progressive semantic-visual mutual adaption (PSVMA+) network, where sufficient visual elements across granularity levels can be gathered to remedy the granularity inconsistency. PSVMA+ explores semantic-visual interactions at different granularity levels, enabling awareness of multi-granularity in both visual and semantic elements. At each granularity level, the dual semantic-visual transformer module (DSVTM) recasts the sharing attributes into instance-centric attributes and aggregates the semantic-related visual regions, thereby learning unambiguous visual features to accommodate various instances. Given the diverse contributions of different granularities, PSVMA+ employs selective cross-granularity learning to leverage knowledge from reliable granularities and adaptively fuses multi-granularity features for comprehensive representations. Experimental results demonstrate that PSVMA+ consistently outperforms state-of-the-art methods.
Instructing Prompt-to-Prompt Generation for Zero-Shot Learning
Jun 05, 2024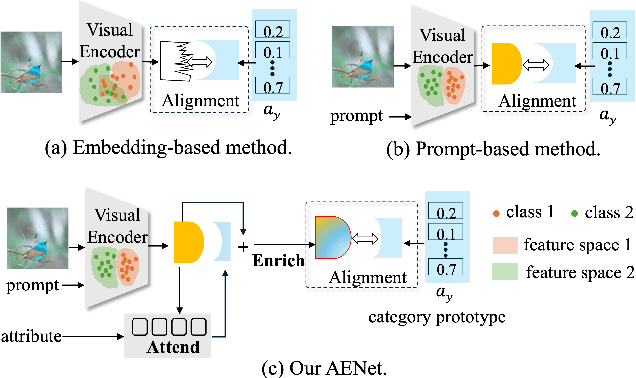
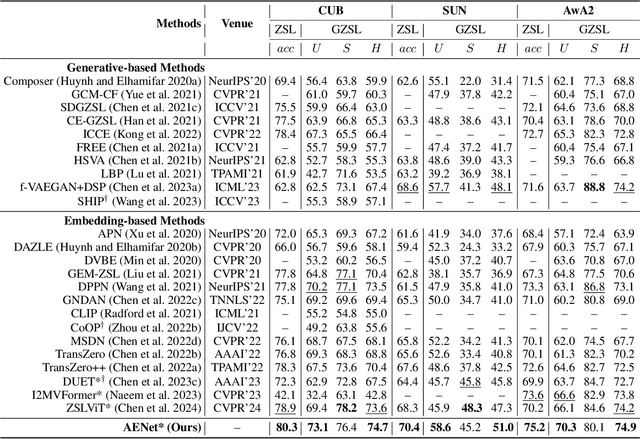
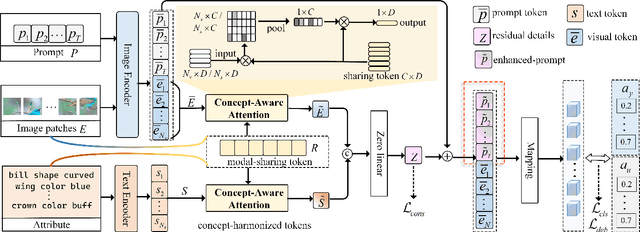

Zero-shot learning (ZSL) aims to explore the semantic-visual interactions to discover comprehensive knowledge transferred from seen categories to classify unseen categories. Recently, prompt engineering has emerged in ZSL, demonstrating impressive potential as it enables the zero-shot transfer of diverse visual concepts to downstream tasks. However, these methods are still not well generalized to broad unseen domains. A key reason is that the fixed adaption of learnable prompts on seen domains makes it tend to over-emphasize the primary visual features observed during training. In this work, we propose a \textbf{P}rompt-to-\textbf{P}rompt generation methodology (\textbf{P2P}), which addresses this issue by further embracing the instruction-following technique to distill instructive visual prompts for comprehensive transferable knowledge discovery. The core of P2P is to mine semantic-related instruction from prompt-conditioned visual features and text instruction on modal-sharing semantic concepts and then inversely rectify the visual representations with the guidance of the learned instruction prompts. This enforces the compensation for missing visual details to primary contexts and further eliminates the cross-modal disparity, endowing unseen domain generalization. Through extensive experimental results, we demonstrate the efficacy of P2P in achieving superior performance over state-of-the-art methods.
Exploring Resolution Fields for Scalable Image Compression with Uncertainty Guidance
Jun 15, 2023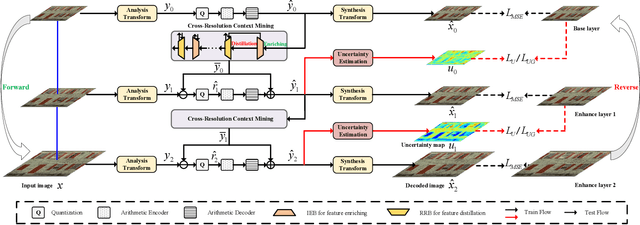

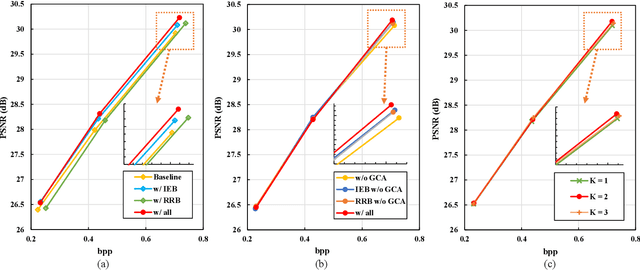

Recently, there are significant advancements in learning-based image compression methods surpassing traditional coding standards. Most of them prioritize achieving the best rate-distortion performance for a particular compression rate, which limits their flexibility and adaptability in various applications with complex and varying constraints. In this work, we explore the potential of resolution fields in scalable image compression and propose the reciprocal pyramid network (RPN) that fulfills the need for more adaptable and versatile compression. Specifically, RPN first builds a compression pyramid and generates the resolution fields at different levels in a top-down manner. The key design lies in the cross-resolution context mining module between adjacent levels, which performs feature enriching and distillation to mine meaningful contextualized information and remove unnecessary redundancy, producing informative resolution fields as residual priors. The scalability is achieved by progressive bitstream reusing and resolution field incorporation varying at different levels. Furthermore, between adjacent compression levels, we explicitly quantify the aleatoric uncertainty from the bottom decoded representations and develop an uncertainty-guided loss to update the upper-level compression parameters, forming a reverse pyramid process that enforces the network to focus on the textured pixels with high variance for more reliable and accurate reconstruction. Combining resolution field exploration and uncertainty guidance in a pyramid manner, RPN can effectively achieve spatial and quality scalable image compression. Experiments show the superiority of RPN against existing classical and deep learning-based scalable codecs. Code will be available at https://github.com/JGIroro/RPNSIC.
Progressive Semantic-Visual Mutual Adaption for Generalized Zero-Shot Learning
Mar 27, 2023Generalized Zero-Shot Learning (GZSL) identifies unseen categories by knowledge transferred from the seen domain, relying on the intrinsic interactions between visual and semantic information. Prior works mainly localize regions corresponding to the sharing attributes. When various visual appearances correspond to the same attribute, the sharing attributes inevitably introduce semantic ambiguity, hampering the exploration of accurate semantic-visual interactions. In this paper, we deploy the dual semantic-visual transformer module (DSVTM) to progressively model the correspondences between attribute prototypes and visual features, constituting a progressive semantic-visual mutual adaption (PSVMA) network for semantic disambiguation and knowledge transferability improvement. Specifically, DSVTM devises an instance-motivated semantic encoder that learns instance-centric prototypes to adapt to different images, enabling the recast of the unmatched semantic-visual pair into the matched one. Then, a semantic-motivated instance decoder strengthens accurate cross-domain interactions between the matched pair for semantic-related instance adaption, encouraging the generation of unambiguous visual representations. Moreover, to mitigate the bias towards seen classes in GZSL, a debiasing loss is proposed to pursue response consistency between seen and unseen predictions. The PSVMA consistently yields superior performances against other state-of-the-art methods. Code will be available at: https://github.com/ManLiuCoder/PSVMA.