 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideo Detective: Seek Critical Clues Recurrently to Answer Question from Long Videos
Dec 19, 2025Long Video Question-Answering (LVQA) presents a significant challenge for Multi-modal Large Language Models (MLLMs) due to immense context and overloaded information, which could also lead to prohibitive memory consumption. While existing methods attempt to address these issues by reducing visual tokens or extending model's context length, they may miss useful information or take considerable computation. In fact, when answering given questions, only a small amount of crucial information is required. Therefore, we propose an efficient question-aware memory mechanism, enabling MLLMs to recurrently seek these critical clues. Our approach, named VideoDetective, simplifies this task by iteratively processing video sub-segments. For each sub-segment, a question-aware compression strategy is employed by introducing a few special memory tokens to achieve purposefully compression. This allows models to effectively seek critical clues while reducing visual tokens. Then, due to history context could have a significant impact, we recurrently aggregate and store these memory tokens to update history context, which would be reused for subsequent sub-segments. Furthermore, to more effectively measure model's long video understanding ability, we introduce GLVC (Grounding Long Video Clues), a long video question-answering dataset, which features grounding critical and concrete clues scattered throughout entire videos. Experimental results demonstrate our method enables MLLMs with limited context length of 32K to efficiently process 100K tokens (3600 frames, an hour-long video sampled at 1fps), requiring only 2 minutes and 37GB GPU memory usage. Evaluation results across multiple long video benchmarks illustrate our method can more effectively seek critical clues from massive information.
When Deepfakes Look Real: Detecting AI-Generated Faces with Unlabeled Data due to Annotation Challenges
Aug 12, 2025Existing deepfake detection methods heavily depend on labeled training data. However, as AI-generated content becomes increasingly realistic, even \textbf{human annotators struggle to distinguish} between deepfakes and authentic images. This makes the labeling process both time-consuming and less reliable. Specifically, there is a growing demand for approaches that can effectively utilize large-scale unlabeled data from online social networks. Unlike typical unsupervised learning tasks, where categories are distinct, AI-generated faces closely mimic real image distributions and share strong similarities, causing performance drop in conventional strategies. In this paper, we introduce the Dual-Path Guidance Network (DPGNet), to tackle two key challenges: (1) bridging the domain gap between faces from different generation models, and (2) utilizing unlabeled image samples. The method features two core modules: text-guided cross-domain alignment, which uses learnable prompts to unify visual and textual embeddings into a domain-invariant feature space, and curriculum-driven pseudo label generation, which dynamically exploit more informative unlabeled samples. To prevent catastrophic forgetting, we also facilitate bridging between domains via cross-domain knowledge distillation. Extensive experiments on \textbf{11 popular datasets}, show that DPGNet outperforms SoTA approaches by \textbf{6.3\%}, highlighting its effectiveness in leveraging unlabeled data to address the annotation challenges posed by the increasing realism of deepfakes.
Crab: A Unified Audio-Visual Scene Understanding Model with Explicit Cooperation
Mar 17, 2025In recent years, numerous tasks have been proposed to encourage model to develop specified capability in understanding audio-visual scene, primarily categorized into temporal localization, spatial localization, spatio-temporal reasoning, and pixel-level understanding. Instead, human possesses a unified understanding ability for diversified tasks. Therefore, designing an audio-visual model with general capability to unify these tasks is of great value. However, simply joint training for all tasks can lead to interference due to the heterogeneity of audiovisual data and complex relationship among tasks. We argue that this problem can be solved through explicit cooperation among tasks. To achieve this goal, we propose a unified learning method which achieves explicit inter-task cooperation from both the perspectives of data and model thoroughly. Specifically, considering the labels of existing datasets are simple words, we carefully refine these datasets and construct an Audio-Visual Unified Instruction-tuning dataset with Explicit reasoning process (AV-UIE), which clarifies the cooperative relationship among tasks. Subsequently, to facilitate concrete cooperation in learning stage, an interaction-aware LoRA structure with multiple LoRA heads is designed to learn different aspects of audiovisual data interaction. By unifying the explicit cooperation across the data and model aspect, our method not only surpasses existing unified audio-visual model on multiple tasks, but also outperforms most specialized models for certain tasks. Furthermore, we also visualize the process of explicit cooperation and surprisingly find that each LoRA head has certain audio-visual understanding ability. Code and dataset: https://github.com/GeWu-Lab/Crab
PSVMA+: Exploring Multi-granularity Semantic-visual Adaption for Generalized Zero-shot Learning
Oct 15, 2024



Generalized zero-shot learning (GZSL) endeavors to identify the unseen categories using knowledge from the seen domain, necessitating the intrinsic interactions between the visual features and attribute semantic features. However, GZSL suffers from insufficient visual-semantic correspondences due to the attribute diversity and instance diversity. Attribute diversity refers to varying semantic granularity in attribute descriptions, ranging from low-level (specific, directly observable) to high-level (abstract, highly generic) characteristics. This diversity challenges the collection of adequate visual cues for attributes under a uni-granularity. Additionally, diverse visual instances corresponding to the same sharing attributes introduce semantic ambiguity, leading to vague visual patterns. To tackle these problems, we propose a multi-granularity progressive semantic-visual mutual adaption (PSVMA+) network, where sufficient visual elements across granularity levels can be gathered to remedy the granularity inconsistency. PSVMA+ explores semantic-visual interactions at different granularity levels, enabling awareness of multi-granularity in both visual and semantic elements. At each granularity level, the dual semantic-visual transformer module (DSVTM) recasts the sharing attributes into instance-centric attributes and aggregates the semantic-related visual regions, thereby learning unambiguous visual features to accommodate various instances. Given the diverse contributions of different granularities, PSVMA+ employs selective cross-granularity learning to leverage knowledge from reliable granularities and adaptively fuses multi-granularity features for comprehensive representations. Experimental results demonstrate that PSVMA+ consistently outperforms state-of-the-art methods.
Instructing Prompt-to-Prompt Generation for Zero-Shot Learning
Jun 05, 2024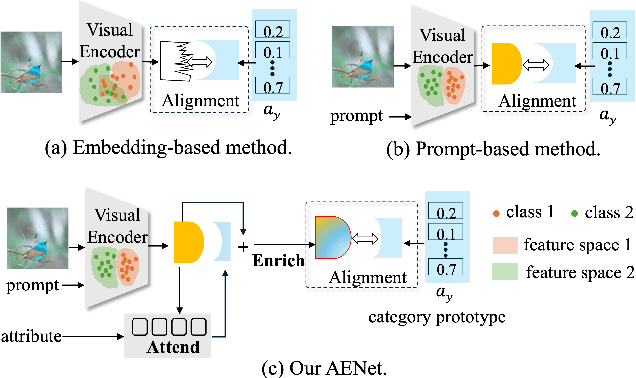
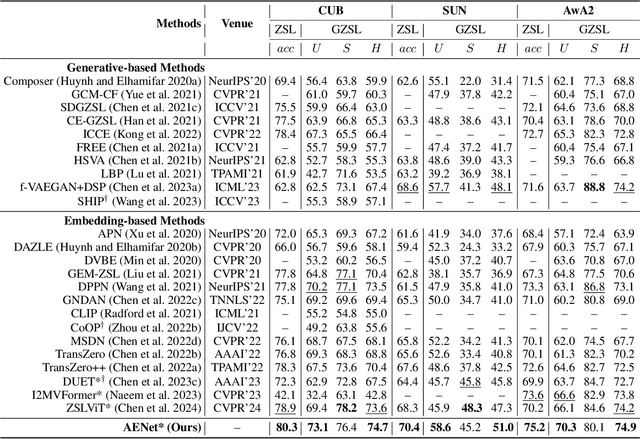
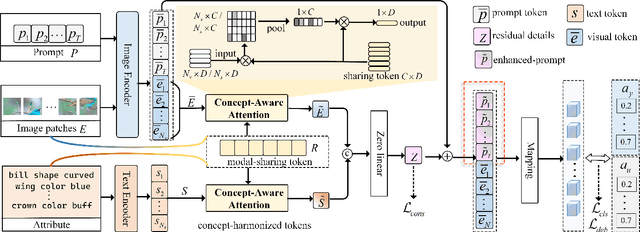

Zero-shot learning (ZSL) aims to explore the semantic-visual interactions to discover comprehensive knowledge transferred from seen categories to classify unseen categories. Recently, prompt engineering has emerged in ZSL, demonstrating impressive potential as it enables the zero-shot transfer of diverse visual concepts to downstream tasks. However, these methods are still not well generalized to broad unseen domains. A key reason is that the fixed adaption of learnable prompts on seen domains makes it tend to over-emphasize the primary visual features observed during training. In this work, we propose a \textbf{P}rompt-to-\textbf{P}rompt generation methodology (\textbf{P2P}), which addresses this issue by further embracing the instruction-following technique to distill instructive visual prompts for comprehensive transferable knowledge discovery. The core of P2P is to mine semantic-related instruction from prompt-conditioned visual features and text instruction on modal-sharing semantic concepts and then inversely rectify the visual representations with the guidance of the learned instruction prompts. This enforces the compensation for missing visual details to primary contexts and further eliminates the cross-modal disparity, endowing unseen domain generalization. Through extensive experimental results, we demonstrate the efficacy of P2P in achieving superior performance over state-of-the-art methods.
Textual Prompt Guided Image Restoration
Dec 11, 2023

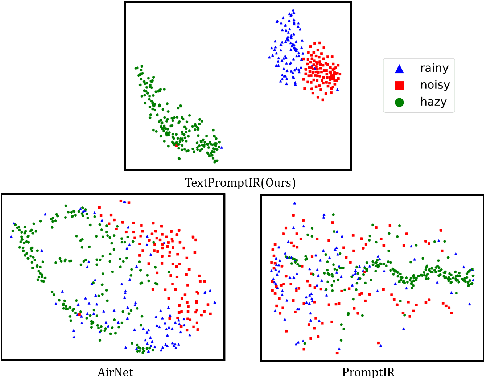

Image restoration has always been a cutting-edge topic in the academic and industrial fields of computer vision. Since degradation signals are often random and diverse, "all-in-one" models that can do blind image restoration have been concerned in recent years. Early works require training specialized headers and tails to handle each degradation of concern, which are manually cumbersome. Recent works focus on learning visual prompts from data distribution to identify degradation type. However, the prompts employed in most of models are non-text, lacking sufficient emphasis on the importance of human-in-the-loop. In this paper, an effective textual prompt guided image restoration model has been proposed. In this model, task-specific BERT is fine-tuned to accurately understand user's instructions and generating textual prompt guidance. Depth-wise multi-head transposed attentions and gated convolution modules are designed to bridge the gap between textual prompts and visual features. The proposed model has innovatively introduced semantic prompts into low-level visual domain. It highlights the potential to provide a natural, precise, and controllable way to perform image restoration tasks. Extensive experiments have been done on public denoising, dehazing and deraining datasets. The experiment results demonstrate that, compared with popular state-of-the-art methods, the proposed model can obtain much more superior performance, achieving accurate recognition and removal of degradation without increasing model's complexity. Related source codes and data will be publicly available on github site https://github.com/MoTong-AI-studio/TextPromptIR.
CTP: Towards Vision-Language Continual Pretraining via Compatible Momentum Contrast and Topology Preservation
Aug 14, 2023



Vision-Language Pretraining (VLP) has shown impressive results on diverse downstream tasks by offline training on large-scale datasets. Regarding the growing nature of real-world data, such an offline training paradigm on ever-expanding data is unsustainable, because models lack the continual learning ability to accumulate knowledge constantly. However, most continual learning studies are limited to uni-modal classification and existing multi-modal datasets cannot simulate continual non-stationary data stream scenarios. To support the study of Vision-Language Continual Pretraining (VLCP), we first contribute a comprehensive and unified benchmark dataset P9D which contains over one million product image-text pairs from 9 industries. The data from each industry as an independent task supports continual learning and conforms to the real-world long-tail nature to simulate pretraining on web data. We comprehensively study the characteristics and challenges of VLCP, and propose a new algorithm: Compatible momentum contrast with Topology Preservation, dubbed CTP. The compatible momentum model absorbs the knowledge of the current and previous-task models to flexibly update the modal feature. Moreover, Topology Preservation transfers the knowledge of embedding across tasks while preserving the flexibility of feature adjustment. The experimental results demonstrate our method not only achieves superior performance compared with other baselines but also does not bring an expensive training burden. Dataset and codes are available at https://github.com/KevinLight831/CTP.
You Can Mask More For Extremely Low-Bitrate Image Compression
Jun 27, 2023



Learned image compression (LIC) methods have experienced significant progress during recent years. However, these methods are primarily dedicated to optimizing the rate-distortion (R-D) performance at medium and high bitrates (> 0.1 bits per pixel (bpp)), while research on extremely low bitrates is limited. Besides, existing methods fail to explicitly explore the image structure and texture components crucial for image compression, treating them equally alongside uninformative components in networks. This can cause severe perceptual quality degradation, especially under low-bitrate scenarios. In this work, inspired by the success of pre-trained masked autoencoders (MAE) in many downstream tasks, we propose to rethink its mask sampling strategy from structure and texture perspectives for high redundancy reduction and discriminative feature representation, further unleashing the potential of LIC methods. Therefore, we present a dual-adaptive masking approach (DA-Mask) that samples visible patches based on the structure and texture distributions of original images. We combine DA-Mask and pre-trained MAE in masked image modeling (MIM) as an initial compressor that abstracts informative semantic context and texture representations. Such a pipeline can well cooperate with LIC networks to achieve further secondary compression while preserving promising reconstruction quality. Consequently, we propose a simple yet effective masked compression model (MCM), the first framework that unifies MIM and LIC end-to-end for extremely low-bitrate image compression. Extensive experiments have demonstrated that our approach outperforms recent state-of-the-art methods in R-D performance, visual quality, and downstream applications, at very low bitrates. Our code is available at https://github.com/lianqi1008/MCM.git.
Progressive Semantic-Visual Mutual Adaption for Generalized Zero-Shot Learning
Mar 27, 2023Generalized Zero-Shot Learning (GZSL) identifies unseen categories by knowledge transferred from the seen domain, relying on the intrinsic interactions between visual and semantic information. Prior works mainly localize regions corresponding to the sharing attributes. When various visual appearances correspond to the same attribute, the sharing attributes inevitably introduce semantic ambiguity, hampering the exploration of accurate semantic-visual interactions. In this paper, we deploy the dual semantic-visual transformer module (DSVTM) to progressively model the correspondences between attribute prototypes and visual features, constituting a progressive semantic-visual mutual adaption (PSVMA) network for semantic disambiguation and knowledge transferability improvement. Specifically, DSVTM devises an instance-motivated semantic encoder that learns instance-centric prototypes to adapt to different images, enabling the recast of the unmatched semantic-visual pair into the matched one. Then, a semantic-motivated instance decoder strengthens accurate cross-domain interactions between the matched pair for semantic-related instance adaption, encouraging the generation of unambiguous visual representations. Moreover, to mitigate the bias towards seen classes in GZSL, a debiasing loss is proposed to pursue response consistency between seen and unseen predictions. The PSVMA consistently yields superior performances against other state-of-the-art methods. Code will be available at: https://github.com/ManLiuCoder/PSVMA.
Causality-based CTR Prediction using Graph Neural Networks
Jan 30, 2023As a prevalent problem in online advertising, CTR prediction has attracted plentiful attention from both academia and industry. Recent studies have been reported to establish CTR prediction models in the graph neural networks (GNNs) framework. However, most of GNNs-based models handle feature interactions in a complete graph, while ignoring causal relationships among features, which results in a huge drop in the performance on out-of-distribution data. This paper is dedicated to developing a causality-based CTR prediction model in the GNNs framework (Causal-GNN) integrating representations of feature graph, user graph and ad graph in the context of online advertising. In our model, a structured representation learning method (GraphFwFM) is designed to capture high-order representations on feature graph based on causal discovery among field features in gated graph neural networks (GGNNs), and GraphSAGE is employed to obtain graph representations of users and ads. Experiments conducted on three public datasets demonstrate the superiority of Causal-GNN in AUC and Logloss and the effectiveness of GraphFwFM in capturing high-order representations on causal feature graph.
* 40 pages, 6 figures, 5 tables