 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridgeNet: A Joint Learning Network of Depth Map Super-Resolution and Monocular Depth Estimation
Jul 27, 2021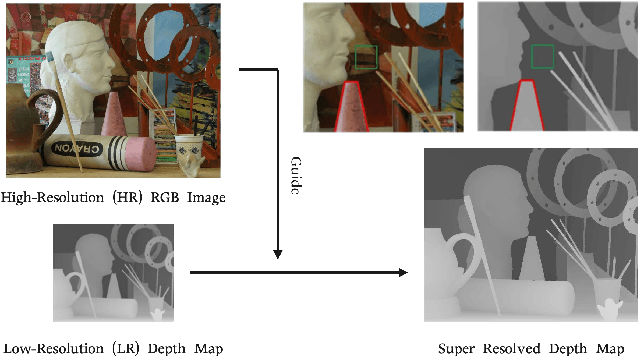
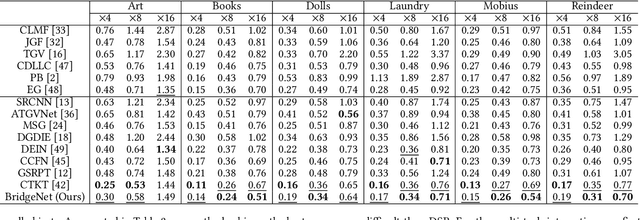
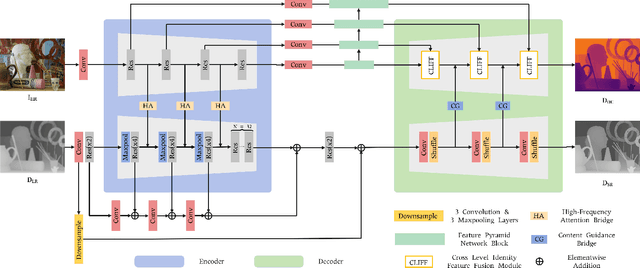

Depth map super-resolution is a task with high practical application requirements in the industry. Existing color-guided depth map super-resolution methods usually necessitate an extra branch to extract high-frequency detail information from RGB image to guide the low-resolution depth map reconstruction. However, because there are still some differences between the two modalities, direct information transmission in the feature dimension or edge map dimension cannot achieve satisfactory result, and may even trigger texture copying in areas where the structures of the RGB-D pair are inconsistent. Inspired by the multi-task learning, we propose a joint learning network of depth map super-resolution (DSR) and monocular depth estimation (MDE) without introducing additional supervision labels. For the interaction of two subnetworks, we adopt a differentiated guidance strategy and design two bridges correspondingly. One is the high-frequency attention bridge (HABdg) designed for the feature encoding process, which learns the high-frequency information of the MDE task to guide the DSR task. The other is the content guidance bridge (CGBdg) designed for the depth map reconstruction process, which provides the content guidance learned from DSR task for MDE task. The entire network architecture is highly portable and can provide a paradigm for associating the DSR and MDE tasks. Extensive experiments on benchmark datasets demonstrate that our method achieves competitive performance. Our code and models are available at https://rmcong.github.io/proj_BridgeNet.html.
Towards Fast and Accurate Real-World Depth Super-Resolution: Benchmark Dataset and Baseline
Apr 13, 2021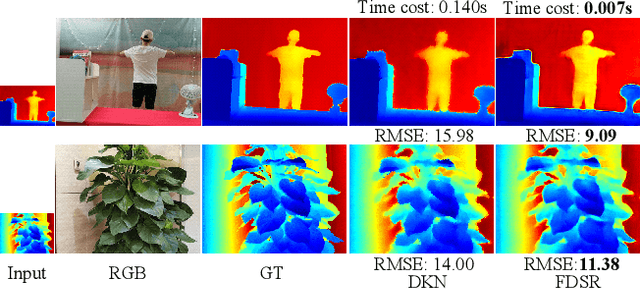

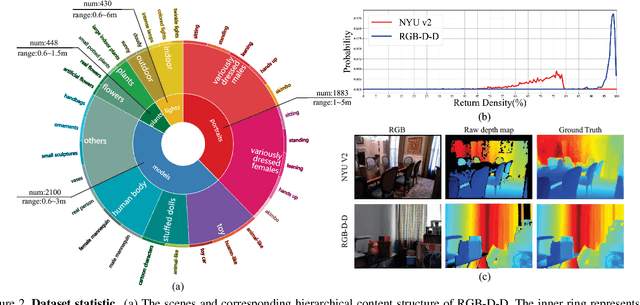

Depth maps obtained by commercial depth sensors are always in low-resolution, making it difficult to be used in various computer vision tasks. Thus, depth map super-resolution (SR) is a practical and valuable task, which upscales the depth map into high-resolution (HR) space. However, limited by the lack of real-world paired low-resolution (LR) and HR depth maps, most existing methods use downsampling to obtain paired training samples. To this end, we first construct a large-scale dataset named "RGB-D-D", which can greatly promote the study of depth map SR and even more depth-related real-world tasks. The "D-D" in our dataset represents the paired LR and HR depth maps captured from mobile phone and Lucid Helios respectively ranging from indoor scenes to challenging outdoor scenes. Besides, we provide a fast depth map super-resolution (FDSR) baseline, in which the high-frequency component adaptively decomposed from RGB image to guide the depth map SR. Extensive experiments on existing public datasets demonstrate the effectiveness and efficiency of our network compared with the state-of-the-art methods. Moreover, for the real-world LR depth maps, our algorithm can produce more accurate HR depth maps with clearer boundaries and to some extent correct the depth value errors.