 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Hierarchical Color Guidance for Depth Map Super-Resolution
Mar 12, 2024Color information is the most commonly used prior knowledge for depth map super-resolution (DSR), which can provide high-frequency boundary guidance for detail restoration. However, its role and functionality in DSR have not been fully developed. In this paper, we rethink the utilization of color information and propose a hierarchical color guidance network to achieve DSR. On the one hand, the low-level detail embedding module is designed to supplement high-frequency color information of depth features in a residual mask manner at the low-level stages. On the other hand, the high-level abstract guidance module is proposed to maintain semantic consistency in the reconstruction process by using a semantic mask that encodes the global guidance information. The color information of these two dimensions plays a role in the front and back ends of the attention-based feature projection (AFP) module in a more comprehensive form. Simultaneously, the AFP module integrates the multi-scale content enhancement block and adaptive attention projection block to make full use of multi-scale information and adaptively project critical restoration information in an attention manner for DSR. Compared with the state-of-the-art methods on four benchmark datasets, our method achieves more competitive performance both qualitatively and quantitatively.
BridgeNet: A Joint Learning Network of Depth Map Super-Resolution and Monocular Depth Estimation
Jul 27, 2021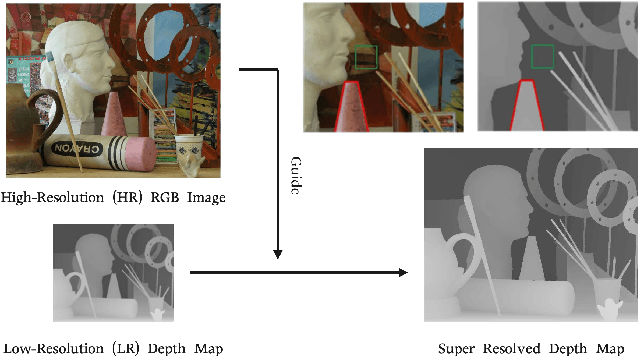
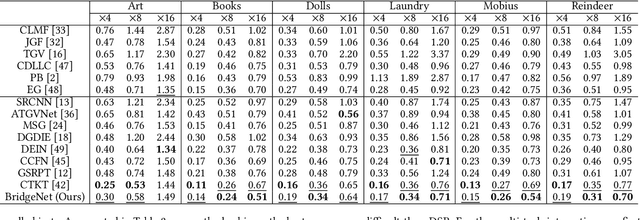
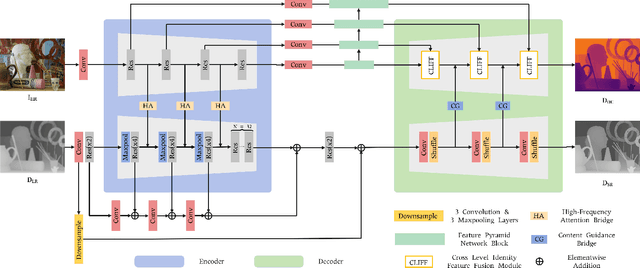

Depth map super-resolution is a task with high practical application requirements in the industry. Existing color-guided depth map super-resolution methods usually necessitate an extra branch to extract high-frequency detail information from RGB image to guide the low-resolution depth map reconstruction. However, because there are still some differences between the two modalities, direct information transmission in the feature dimension or edge map dimension cannot achieve satisfactory result, and may even trigger texture copying in areas where the structures of the RGB-D pair are inconsistent. Inspired by the multi-task learning, we propose a joint learning network of depth map super-resolution (DSR) and monocular depth estimation (MDE) without introducing additional supervision labels. For the interaction of two subnetworks, we adopt a differentiated guidance strategy and design two bridges correspondingly. One is the high-frequency attention bridge (HABdg) designed for the feature encoding process, which learns the high-frequency information of the MDE task to guide the DSR task. The other is the content guidance bridge (CGBdg) designed for the depth map reconstruction process, which provides the content guidance learned from DSR task for MDE task. The entire network architecture is highly portable and can provide a paradigm for associating the DSR and MDE tasks. Extensive experiments on benchmark datasets demonstrate that our method achieves competitive performance. Our code and models are available at https://rmcong.github.io/proj_BridgeNet.html.