 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDUGAE: Unified Geometry and Attribute Enhancement via Spatiotemporal Correlations for G-PCC Compressed Dynamic Point Clouds
Mar 27, 2026Existing post-decoding quality enhancement methods for point clouds are designed for static data and typically process each frame independently. As a result, they cannot effectively exploit the spatiotemporal correlations present in point cloud sequences.We propose a unified geometry and attribute enhancement framework (DUGAE) for G-PCC compressed dynamic point clouds that explicitly exploits inter-frame spatiotemporal correlations in both geometry and attributes. First, a dynamic geometry enhancement network (DGE-Net) based on sparse convolution (SPConv) and feature-domain geometry motion compensation (GMC) aligns and aggregates spatiotemporal information. Then, a detail-aware k-nearest neighbors (DA-KNN) recoloring module maps the original attributes onto the enhanced geometry at the encoder side, improving mapping completeness and preserving attribute details. Finally, a dynamic attribute enhancement network (DAE-Net) with dedicated temporal feature extraction and feature-domain attribute motion compensation (AMC) refines attributes by modeling complex spatiotemporal correlations. On seven dynamic point clouds from the 8iVFB v2, Owlii, and MVUB datasets, DUGAE significantly enhanced the performance of the latest G-PCC geometry-based solid content test model (GeS-TM v10). For geometry (D1), it achieved an average BD-PSNR gain of 11.03 dB and a 93.95% BD-bitrate reduction. For the luma component, it achieved a 4.23 dB BD-PSNR gain with a 66.61% BD-bitrate reduction. DUGAE also improved perceptual quality (as measured by PCQM) and outperformed V-PCC. Our source code will be released on GitHub at: https://github.com/yuanhui0325/DUGAE
Blind Quality Enhancement for G-PCC Compressed Dynamic Point Clouds
Mar 25, 2026Point cloud compression often introduces noticeable reconstruction artifacts, which makes quality enhancement necessary. Existing approaches typically assume prior knowledge of the distortion level and train multiple models with identical architectures, each designed for a specific distortion setting. This significantly limits their practical applicability in scenarios where the distortion level is unknown and computational resources are limited. To overcome these limitations, we propose the first blind quality enhancement (BQE) model for compressed dynamic point clouds. BQE enhances compressed point clouds under unknown distortion levels by exploiting temporal dependencies and jointly modeling feature similarity and differences across multiple distortion levels. It consists of a joint progressive feature extraction branch and an adaptive feature fusion branch. In the joint progressive feature extraction branch, consecutive reconstructed frames are first fed into a recoloring-based motion compensation module to generate temporally aligned virtual reference frames. These frames are then fused by a temporal correlation-guided cross-attention module and processed by a progressive feature extraction module to obtain hierarchical features at different distortion levels. In the adaptive feature fusion branch, the current reconstructed frame is input to a quality estimation module to predict a weighting distribution that guides the adaptive weighted fusion of these hierarchical features. When applied to the latest geometry-based point cloud compression (G-PCC) reference software, i.e., test model category13 version 28, BQE achieved average PSNR improvements of 0.535 dB, 0.403 dB, and 0.453 dB, with BD-rates of -17.4%, -20.5%, and -20.1% for the Luma, Cb, and Cr components, respectively.
RSONet: Region-guided Selective Optimization Network for RGB-T Salient Object Detection
Mar 13, 2026This paper focuses on the inconsistency in salient regions between RGB and thermal images. To address this issue, we propose the Region-guided Selective Optimization Network for RGB-T Salient Object Detection, which consists of the region guidance stage and saliency generation stage. In the region guidance stage, three parallel branches with same encoder-decoder structure equipped with the context interaction (CI) module and spatial-aware fusion (SF) module are designed to generate the guidance maps which are leveraged to calculate similarity scores. Then, in the saliency generation stage, the selective optimization (SO) module fuses RGB and thermal features based on the previously obtained similarity values to mitigate the impact of inconsistent distribution of salient targets between the two modalities. After that, to generate high-quality detection result, the dense detail enhancement (DDE) module which adopts the multiple dense connections and visual state space blocks is applied to low-level features for optimizing the detail information. In addition, the mutual interaction semantic (MIS) module is placed in the high-level features to dig the location cues by the mutual fusion strategy. We conduct extensive experiments on the RGB-T dataset, and the results demonstrate that the proposed RSONet achieves competitive performance against 27 state-of-the-art SOD methods.
Bin~Wan,G2HFNet: GeoGran-Aware Hierarchical Feature Fusion Network for Salient Object Detection in Optical Remote Sensing Images
Mar 13, 2026Remote sensing images captured from aerial perspectives often exhibit significant scale variations and complex backgrounds, posing challenges for salient object detection (SOD). Existing methods typically extract multi-level features at a single scale using uniform attention mechanisms, leading to suboptimal representations and incomplete detection results. To address these issues, we propose a GeoGran-Aware Hierarchical Feature Fusion Network (G2HFNet) that fully exploits geometric and granular cues in optical remote sensing images. Specifically, G2HFNet adopts Swin Transformer as the backbone to extract multi-level features and integrates three key modules: the multi-scale detail enhancement (MDE) module to handle object scale variations and enrich fine details, the dual-branch geo-gran complementary (DGC) module to jointly capture fine-grained details and positional information in mid-level features, and the deep semantic perception (DSP) module to refine high-level positional cues via self-attention. Additionally, a local-global guidance fusion (LGF) module is introduced to replace traditional convolutions for effective multi-level feature integration. Extensive experiments demonstrate that G2HFNet achieves high-quality saliency maps and significantly improves detection performance in challenging remote sensing scenarios.
RDNet: Region Proportion-Aware Dynamic Adaptive Salient Object Detection Network in Optical Remote Sensing Images
Mar 12, 2026Salient object detection (SOD) in remote sensing images faces significant challenges due to large variations in object sizes, the computational cost of self-attention mechanisms, and the limitations of CNN-based extractors in capturing global context and long-range dependencies. Existing methods that rely on fixed convolution kernels often struggle to adapt to diverse object scales, leading to detail loss or irrelevant feature aggregation. To address these issues, this work aims to enhance robustness to scale variations and achieve precise object localization. We propose the Region Proportion-Aware Dynamic Adaptive Salient Object Detection Network (RDNet), which replaces the CNN backbone with the SwinTransformer for global context modeling and introduces three key modules: (1) the Dynamic Adaptive Detail-aware (DAD) module, which applies varied convolution kernels guided by object region proportions; (2) the Frequency-matching Context Enhancement (FCE) module, which enriches contextual information through wavelet interactions and attention; and (3) the Region Proportion-aware Localization (RPL) module, which employs cross-attention to highlight semantic details and integrates a Proportion Guidance (PG) block to assist the DAD module. By combining these modules, RDNet achieves robustness against scale variations and accurate localization, delivering superior detection performance compared with state-of-the-art methods.
Point Cloud Feature Coding for Object Detection over an Error-Prone Cloud-Edge Collaborative System
Mar 04, 2026Cloud-edge collaboration enhances machine perception by combining the strengths of edge and cloud computing. Edge devices capture raw data (e.g., 3D point clouds) and extract salient features, which are sent to the cloud for deeper analysis and data fusion. However, efficiently and reliably transmitting features between cloud and edge devices remains a challenging problem. We focus on point cloud-based object detection and propose a task-driven point cloud compression and reliable transmission framework based on source and channel coding. To meet the low-latency and low-power requirements of edge devices, we design a lightweight yet effective feature compaction module that compresses the deepest feature among multi-scale representations by removing task-irrelevant regions and applying channel-wise dimensionality reduction to task-relevant areas. Then, a signal-to-noise ratio (SNR)-adaptive channel encoder dynamically encodes the attribute information of the compacted features, while a Low-Density Parity-Check (LDPC) encoder ensures reliable transmission of geometric information. At the cloud side, an SNR-adaptive channel decoder guides the decoding of attribute information, and the LDPC decoder corrects geometry errors. Finally, a feature decompaction module restores the channel-wise dimensionality, and a diffusion-based feature upsampling module reconstructs shallow-layer features, enabling multi-scale feature reconstruction. On the KITTI dataset, our method achieved a 172-fold reduction in feature size with 3D average precision scores of 93.17%, 86.96%, and 77.25% for easy, moderate, and hard objects, respectively, over a 0 dB SNR wireless channel. Our source code will be released on GitHub at: https://github.com/yuanhui0325/T-PCFC.
Joint Semantic and Rendering Enhancements in 3D Gaussian Modeling with Anisotropic Local Encoding
Jan 05, 2026Recent works propose extending 3DGS with semantic feature vectors for simultaneous semantic segmentation and image rendering. However, these methods often treat the semantic and rendering branches separately, relying solely on 2D supervision while ignoring the 3D Gaussian geometry. Moreover, current adaptive strategies adapt the Gaussian set depending solely on rendering gradients, which can be insufficient in subtle or textureless regions. In this work, we propose a joint enhancement framework for 3D semantic Gaussian modeling that synergizes both semantic and rendering branches. Firstly, unlike conventional point cloud shape encoding, we introduce an anisotropic 3D Gaussian Chebyshev descriptor using the Laplace-Beltrami operator to capture fine-grained 3D shape details, thereby distinguishing objects with similar appearances and reducing reliance on potentially noisy 2D guidance. In addition, without relying solely on rendering gradient, we adaptively adjust Gaussian allocation and spherical harmonics with local semantic and shape signals, enhancing rendering efficiency through selective resource allocation. Finally, we employ a cross-scene knowledge transfer module to continuously update learned shape patterns, enabling faster convergence and robust representations without relearning shape information from scratch for each new scene. Experiments on multiple datasets demonstrate improvements in segmentation accuracy and rendering quality while maintaining high rendering frame rates.
Towards Ancient Plant Seed Classification: A Benchmark Dataset and Baseline Model
Dec 20, 2025Understanding the dietary preferences of ancient societies and their evolution across periods and regions is crucial for revealing human-environment interactions. Seeds, as important archaeological artifacts, represent a fundamental subject of archaeobotanical research. However, traditional studies rely heavily on expert knowledge, which is often time-consuming and inefficient. Intelligent analysis methods have made progress in various fields of archaeology, but there remains a research gap in data and methods in archaeobotany, especially in the classification task of ancient plant seeds. To address this, we construct the first Ancient Plant Seed Image Classification (APS) dataset. It contains 8,340 images from 17 genus- or species-level seed categories excavated from 18 archaeological sites across China. In addition, we design a framework specifically for the ancient plant seed classification task (APSNet), which introduces the scale feature (size) of seeds based on learning fine-grained information to guide the network in discovering key "evidence" for sufficient classification. Specifically, we design a Size Perception and Embedding (SPE) module in the encoder part to explicitly extract size information for the purpose of complementing fine-grained information. We propose an Asynchronous Decoupled Decoding (ADD) architecture based on traditional progressive learning to decode features from both channel and spatial perspectives, enabling efficient learning of discriminative features. In both quantitative and qualitative analyses, our approach surpasses existing state-of-the-art image classification methods, achieving an accuracy of 90.5%. This demonstrates that our work provides an effective tool for large-scale, systematic archaeological research.
WaterFlow: Explicit Physics-Prior Rectified Flow for Underwater Saliency Mask Generation
Oct 14, 2025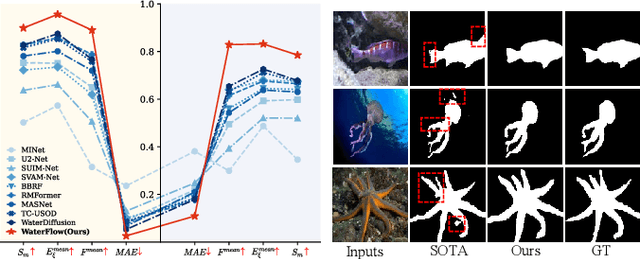
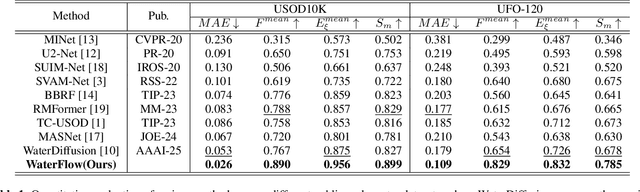
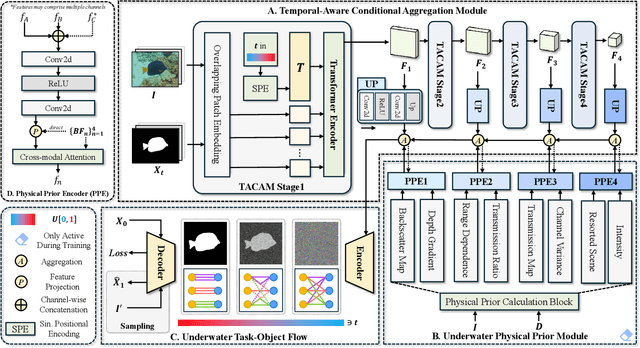

Underwater Salient Object Detection (USOD) faces significant challenges, including underwater image quality degradation and domain gaps. Existing methods tend to ignore the physical principles of underwater imaging or simply treat degradation phenomena in underwater images as interference factors that must be eliminated, failing to fully exploit the valuable information they contain. We propose WaterFlow, a rectified flow-based framework for underwater salient object detection that innovatively incorporates underwater physical imaging information as explicit priors directly into the network training process and introduces temporal dimension modeling, significantly enhancing the model's capability for salient object identification. On the USOD10K dataset, WaterFlow achieves a 0.072 gain in S_m, demonstrating the effectiveness and superiority of our method. The code will be published after the acceptance.
STQE: Spatial-Temporal Quality Enhancement for G-PCC Compressed Dynamic Point Clouds
Jul 23, 2025Very few studies have addressed quality enhancement for compressed dynamic point clouds. In particular, the effective exploitation of spatial-temporal correlations between point cloud frames remains largely unexplored. Addressing this gap, we propose a spatial-temporal attribute quality enhancement (STQE) network that exploits both spatial and temporal correlations to improve the visual quality of G-PCC compressed dynamic point clouds. Our contributions include a recoloring-based motion compensation module that remaps reference attribute information to the current frame geometry to achieve precise inter-frame geometric alignment, a channel-aware temporal attention module that dynamically highlights relevant regions across bidirectional reference frames, a Gaussian-guided neighborhood feature aggregation module that efficiently captures spatial dependencies between geometry and color attributes, and a joint loss function based on the Pearson correlation coefficient, designed to alleviate over-smoothing effects typical of point-wise mean squared error optimization. When applied to the latest G-PCC test model, STQE achieved improvements of 0.855 dB, 0.682 dB, and 0.828 dB in delta PSNR, with Bj{\o}ntegaard Delta rate (BD-rate) reductions of -25.2%, -31.6%, and -32.5% for the Luma, Cb, and Cr components, respectively.