 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEntropyPrune: Matrix Entropy Guided Visual Token Pruning for Multimodal Large Language Models
Feb 19, 2026Multimodal large language models (MLLMs) incur substantial inference cost due to the processing of hundreds of visual tokens per image. Although token pruning has proven effective for accelerating inference, determining when and where to prune remains largely heuristic. Existing approaches typically rely on static, empirically selected layers, which limit interpretability and transferability across models. In this work, we introduce a matrix-entropy perspective and identify an "Entropy Collapse Layer" (ECL), where the information content of visual representations exhibits a sharp and consistent drop, which provides a principled criterion for selecting the pruning stage. Building on this observation, we propose EntropyPrune, a novel matrix-entropy-guided token pruning framework that quantifies the information value of individual visual tokens and prunes redundant ones without relying on attention maps. Moreover, to enable efficient computation, we exploit the spectral equivalence of dual Gram matrices, reducing the complexity of entropy computation and yielding up to a 64x theoretical speedup. Extensive experiments on diverse multimodal benchmarks demonstrate that EntropyPrune consistently outperforms state-of-the-art pruning methods in both accuracy and efficiency. On LLaVA-1.5-7B, our method achieves a 68.2% reduction in FLOPs while preserving 96.0% of the original performance. Furthermore, EntropyPrune generalizes effectively to high-resolution and video-based models, highlighting the strong robustness and scalability in practical MLLM acceleration. The code will be publicly available at https://github.com/YahongWang1/EntropyPrune.
Wavelet-Domain Masked Image Modeling for Color-Consistent HDR Video Reconstruction
Feb 07, 2026High Dynamic Range (HDR) video reconstruction aims to recover fine brightness, color, and details from Low Dynamic Range (LDR) videos. However, existing methods often suffer from color inaccuracies and temporal inconsistencies. To address these challenges, we propose WMNet, a novel HDR video reconstruction network that leverages Wavelet domain Masked Image Modeling (W-MIM). WMNet adopts a two-phase training strategy: In Phase I, W-MIM performs self-reconstruction pre-training by selectively masking color and detail information in the wavelet domain, enabling the network to develop robust color restoration capabilities. A curriculum learning scheme further refines the reconstruction process. Phase II fine-tunes the model using the pre-trained weights to improve the final reconstruction quality. To improve temporal consistency, we introduce the Temporal Mixture of Experts (T-MoE) module and the Dynamic Memory Module (DMM). T-MoE adaptively fuses adjacent frames to reduce flickering artifacts, while DMM captures long-range dependencies, ensuring smooth motion and preservation of fine details. Additionally, since existing HDR video datasets lack scene-based segmentation, we reorganize HDRTV4K into HDRTV4K-Scene, establishing a new benchmark for HDR video reconstruction. Extensive experiments demonstrate that WMNet achieves state-of-the-art performance across multiple evaluation metrics, significantly improving color fidelity, temporal coherence, and perceptual quality. The code is available at: https://github.com/eezkni/WMNet
FlowBypass: Rectified Flow Trajectory Bypass for Training-Free Image Editing
Feb 02, 2026Training-free image editing has attracted increasing attention for its efficiency and independence from training data. However, existing approaches predominantly rely on inversion-reconstruction trajectories, which impose an inherent trade-off: longer trajectories accumulate errors and compromise fidelity, while shorter ones fail to ensure sufficient alignment with the edit prompt. Previous attempts to address this issue typically employ backbone-specific feature manipulations, limiting general applicability. To address these challenges, we propose FlowBypass, a novel and analytical framework grounded in Rectified Flow that constructs a bypass directly connecting inversion and reconstruction trajectories, thereby mitigating error accumulation without relying on feature manipulations. We provide a formal derivation of two trajectories, from which we obtain an approximate bypass formulation and its numerical solution, enabling seamless trajectory transitions. Extensive experiments demonstrate that FlowBypass consistently outperforms state-of-the-art image editing methods, achieving stronger prompt alignment while preserving high-fidelity details in irrelevant regions.
All You Need Are Random Visual Tokens? Demystifying Token Pruning in VLLMs
Dec 08, 2025Vision Large Language Models (VLLMs) incur high computational costs due to their reliance on hundreds of visual tokens to represent images. While token pruning offers a promising solution for accelerating inference, this paper, however, identifies a key observation: in deeper layers (e.g., beyond the 20th), existing training-free pruning methods perform no better than random pruning. We hypothesize that this degradation is caused by "vanishing token information", where visual tokens progressively lose their salience with increasing network depth. To validate this hypothesis, we quantify a token's information content by measuring the change in the model output probabilities upon its removal. Using this proposed metric, our analysis of the information of visual tokens across layers reveals three key findings: (1) As layers deepen, the information of visual tokens gradually becomes uniform and eventually vanishes at an intermediate layer, which we term as "information horizon", beyond which the visual tokens become redundant; (2) The position of this horizon is not static; it extends deeper for visually intensive tasks, such as Optical Character Recognition (OCR), compared to more general tasks like Visual Question Answering (VQA); (3) This horizon is also strongly correlated with model capacity, as stronger VLLMs (e.g., Qwen2.5-VL) employ deeper visual tokens than weaker models (e.g., LLaVA-1.5). Based on our findings, we show that simple random pruning in deep layers efficiently balances performance and efficiency. Moreover, integrating random pruning consistently enhances existing methods. Using DivPrune with random pruning achieves state-of-the-art results, maintaining 96.9% of Qwen-2.5-VL-7B performance while pruning 50% of visual tokens. The code will be publicly available at https://github.com/YahongWang1/Information-Horizon.
Perceptual-GS: Scene-adaptive Perceptual Densification for Gaussian Splatting
Jun 14, 20253D Gaussian Splatting (3DGS) has emerged as a powerful technique for novel view synthesis. However, existing methods struggle to adaptively optimize the distribution of Gaussian primitives based on scene characteristics, making it challenging to balance reconstruction quality and efficiency. Inspired by human perception, we propose scene-adaptive perceptual densification for Gaussian Splatting (Perceptual-GS), a novel framework that integrates perceptual sensitivity into the 3DGS training process to address this challenge. We first introduce a perception-aware representation that models human visual sensitivity while constraining the number of Gaussian primitives. Building on this foundation, we develop a \cameraready{perceptual sensitivity-adaptive distribution} to allocate finer Gaussian granularity to visually critical regions, enhancing reconstruction quality and robustness. Extensive evaluations on multiple datasets, including BungeeNeRF for large-scale scenes, demonstrate that Perceptual-GS achieves state-of-the-art performance in reconstruction quality, efficiency, and robustness. The code is publicly available at: https://github.com/eezkni/Perceptual-GS
Structural Similarity-Inspired Unfolding for Lightweight Image Super-Resolution
Jun 13, 2025Major efforts in data-driven image super-resolution (SR) primarily focus on expanding the receptive field of the model to better capture contextual information. However, these methods are typically implemented by stacking deeper networks or leveraging transformer-based attention mechanisms, which consequently increases model complexity. In contrast, model-driven methods based on the unfolding paradigm show promise in improving performance while effectively maintaining model compactness through sophisticated module design. Based on these insights, we propose a Structural Similarity-Inspired Unfolding (SSIU) method for efficient image SR. This method is designed through unfolding an SR optimization function constrained by structural similarity, aiming to combine the strengths of both data-driven and model-driven approaches. Our model operates progressively following the unfolding paradigm. Each iteration consists of multiple Mixed-Scale Gating Modules (MSGM) and an Efficient Sparse Attention Module (ESAM). The former implements comprehensive constraints on features, including a structural similarity constraint, while the latter aims to achieve sparse activation. In addition, we design a Mixture-of-Experts-based Feature Selector (MoE-FS) that fully utilizes multi-level feature information by combining features from different steps. Extensive experiments validate the efficacy and efficiency of our unfolding-inspired network. Our model outperforms current state-of-the-art models, boasting lower parameter counts and reduced memory consumption. Our code will be available at: https://github.com/eezkni/SSIU
Unrolled Decomposed Unpaired Learning for Controllable Low-Light Video Enhancement
Aug 22, 2024



Obtaining pairs of low/normal-light videos, with motions, is more challenging than still images, which raises technical issues and poses the technical route of unpaired learning as a critical role. This paper makes endeavors in the direction of learning for low-light video enhancement without using paired ground truth. Compared to low-light image enhancement, enhancing low-light videos is more difficult due to the intertwined effects of noise, exposure, and contrast in the spatial domain, jointly with the need for temporal coherence. To address the above challenge, we propose the Unrolled Decomposed Unpaired Network (UDU-Net) for enhancing low-light videos by unrolling the optimization functions into a deep network to decompose the signal into spatial and temporal-related factors, which are updated iteratively. Firstly, we formulate low-light video enhancement as a Maximum A Posteriori estimation (MAP) problem with carefully designed spatial and temporal visual regularization. Then, via unrolling the problem, the optimization of the spatial and temporal constraints can be decomposed into different steps and updated in a stage-wise manner. From the spatial perspective, the designed Intra subnet leverages unpair prior information from expert photography retouched skills to adjust the statistical distribution. Additionally, we introduce a novel mechanism that integrates human perception feedback to guide network optimization, suppressing over/under-exposure conditions. Meanwhile, to address the issue from the temporal perspective, the designed Inter subnet fully exploits temporal cues in progressive optimization, which helps achieve improved temporal consistency in enhancement results. Consequently, the proposed method achieves superior performance to state-of-the-art methods in video illumination, noise suppression, and temporal consistency across outdoor and indoor scenes.
DDR: Exploiting Deep Degradation Response as Flexible Image Descriptor
Jun 12, 2024


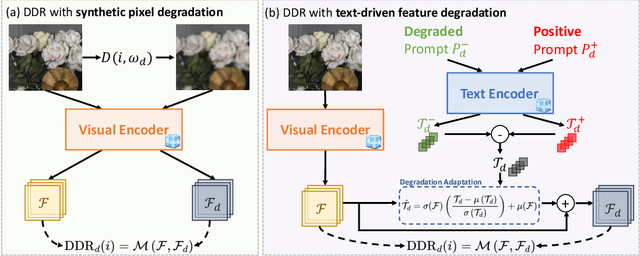
Image deep features extracted by pre-trained networks are known to contain rich and informative representations. In this paper, we present Deep Degradation Response (DDR), a method to quantify changes in image deep features under varying degradation conditions. Specifically, our approach facilitates flexible and adaptive degradation, enabling the controlled synthesis of image degradation through text-driven prompts. Extensive evaluations demonstrate the versatility of DDR as an image descriptor, with strong correlations observed with key image attributes such as complexity, colorfulness, sharpness, and overall quality. Moreover, we demonstrate the efficacy of DDR across a spectrum of applications. It excels as a blind image quality assessment metric, outperforming existing methodologies across multiple datasets. Additionally, DDR serves as an effective unsupervised learning objective in image restoration tasks, yielding notable advancements in image deblurring and single-image super-resolution. Our code will be made available.
Opinion-Unaware Blind Image Quality Assessment using Multi-Scale Deep Feature Statistics
May 29, 2024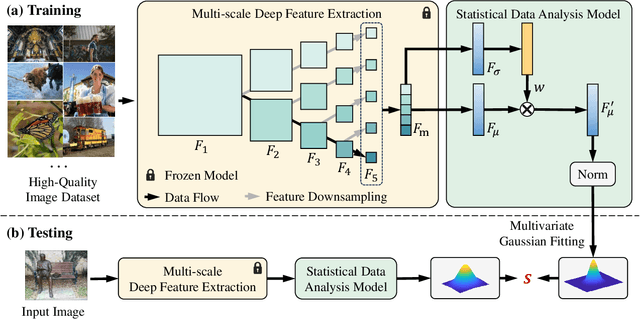
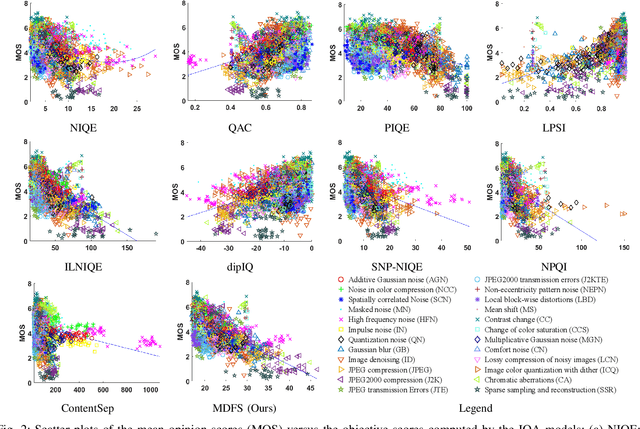
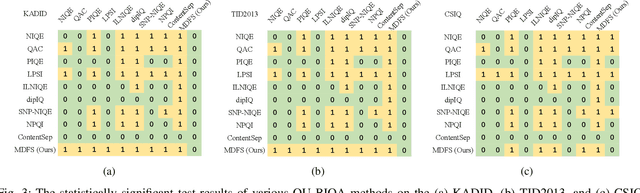

Deep learning-based methods have significantly influenced the blind image quality assessment (BIQA) field, however, these methods often require training using large amounts of human rating data. In contrast, traditional knowledge-based methods are cost-effective for training but face challenges in effectively extracting features aligned with human visual perception. To bridge these gaps, we propose integrating deep features from pre-trained visual models with a statistical analysis model into a Multi-scale Deep Feature Statistics (MDFS) model for achieving opinion-unaware BIQA (OU-BIQA), thereby eliminating the reliance on human rating data and significantly improving training efficiency. Specifically, we extract patch-wise multi-scale features from pre-trained vision models, which are subsequently fitted into a multivariate Gaussian (MVG) model. The final quality score is determined by quantifying the distance between the MVG model derived from the test image and the benchmark MVG model derived from the high-quality image set. A comprehensive series of experiments conducted on various datasets show that our proposed model exhibits superior consistency with human visual perception compared to state-of-the-art BIQA models. Furthermore, it shows improved generalizability across diverse target-specific BIQA tasks. Our code is available at: https://github.com/eezkni/MDFS
Octree-GS: Towards Consistent Real-time Rendering with LOD-Structured 3D Gaussians
Mar 26, 2024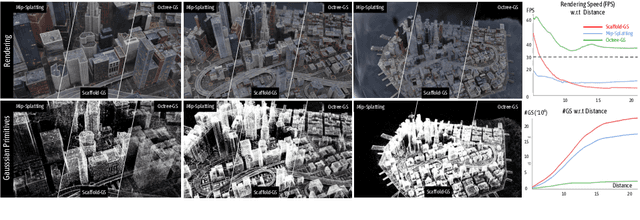



The recent 3D Gaussian splatting (3D-GS) has shown remarkable rendering fidelity and efficiency compared to NeRF-based neural scene representations. While demonstrating the potential for real-time rendering, 3D-GS encounters rendering bottlenecks in large scenes with complex details due to an excessive number of Gaussian primitives located within the viewing frustum. This limitation is particularly noticeable in zoom-out views and can lead to inconsistent rendering speeds in scenes with varying details. Moreover, it often struggles to capture the corresponding level of details at different scales with its heuristic density control operation. Inspired by the Level-of-Detail (LOD) techniques, we introduce Octree-GS, featuring an LOD-structured 3D Gaussian approach supporting level-of-detail decomposition for scene representation that contributes to the final rendering results. Our model dynamically selects the appropriate level from the set of multi-resolution anchor points, ensuring consistent rendering performance with adaptive LOD adjustments while maintaining high-fidelity rendering results.