 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQwen-Image-Flash: Beyond Objective Design
Jun 03, 2026Few-step distillation has become an effective strategy for accelerating advanced visual generative models, yet prior work has largely focused on distillation objectives. In this work, we revisit few-step distillation from a complementary perspective, focusing on the training recipe that critically shapes student performance. Using Qwen-Image-2.0 as a representative case, we systematically investigate three factors in unified text-to-image generation and instruction-guided image editing distillation: data composition, teacher guidance, and task mixture. Our empirical analysis reveals several non-obvious behaviors, which motivate the development of Qwen-Image-Flash. Overall, our results suggest that effective few-step distillation requires not only carefully designed objectives, but also principled organization of the broader training pipeline.
Qwen-Image-Bench: From Generation to Creation in Text-to-Image Evaluation
May 27, 2026Text-to-Image generation has evolved from basic image synthesis into a frequently used core capability in professional creative workflows, where simple text-image alignment can no longer satisfy users' pressing demands for faithful real-world reconstruction and genuine creative expression. Existing benchmarks, however, remain anchored in these foundational criteria and do not yet capture the nuanced capabilities that matter in authentic artistic practice, making it difficult to reliably distinguish state-of-the-art T2I models. To address the gap, we introduce Qwen-Image-Bench, a creator-centric benchmark co-designed with professional artists and grounded in real-world creation scenarios. Qwen-Image-Bench enriches conventional evaluation with two application-driven dimensions: Real-world Fidelity and Creative Generation. Drawing on the staged reasoning inherent in professional artistic workflows, we organize these five pillars into a top-down hierarchical taxonomy that further decomposes into 23 second-level sub-capabilities and 56 third-level verifiable rubrics. To ensure broad coverage, we curate 1000 stratified prompts with each prompt jointly exercising more than four fine-grained facets across multiple pillars. We train a unified judge model Q-Judger based on Qwen3.6-27B, supervised by 80 professional annotators from global art academies under blind labeling and triple-review protocols, that scores every image across all 56 verifiable facets, producing fine-grained, rubric-grounded, and fully attributable diagnostics rather than a single opaque score. Empirically, Qwen-Image-Bench reliably distinguishes leading T2I models, achieving the greatest separation on the two application-driven dimensions of Real-world Fidelity and Creative Generation where existing benchmarks provide little insight, while also providing a trustworthy optimization signal for production-level T2I development.
Qwen-Image-VAE-2.0 Technical Report
May 13, 2026We present Qwen-Image-VAE-2.0, a suite of high-compression Variational Autoencoders (VAEs) that achieve significant advances in both reconstruction fidelity and diffusability. To address the reconstruction bottlenecks of high compression, we adopt an improved architecture featuring Global Skip Connections (GSC) and expanded latent channels. Moreover, we scale training to billions of images and incorporate a synthetic rendering engine to improve performance in text-rich scenarios. To tackle the convergence challenges of high-dimensional latent space, we implement an enhanced semantic alignment strategy to make the latent space highly amenable to diffusion modeling. To optimize computational efficiency, we leverage an asymmetric and attention-free encoder-decoder backbone to minimize encoding overhead. We present a comprehensive evaluation of Qwen-Image-VAE-2.0 on public reconstruction benchmarks. To evaluate performance in text-rich scenarios, we propose OmniDoc-TokenBench, a new benchmark comprising a diverse collection of real-world documents coupled with specialized OCR-based evaluation metrics. Qwen-Image-VAE-2.0 achieves state-of-the-art reconstruction performance, demonstrating exceptional capabilities in both general domains and text-rich scenarios at high compression ratio. Furthermore, downstream DiT experiments reveal our models possess superior diffusability, significantly accelerating convergence compared to existing high-compression baselines. These establish Qwen-Image-VAE-2.0 as a leading model with high compression, superior reconstruction, and exceptional diffusability.
Qwen-Image-2.0 Technical Report
May 11, 2026We present Qwen-Image-2.0, an omni-capable image generation foundation model that unifies high-fidelity generation and precise image editing within a single framework. Despite recent progress, existing models still struggle with ultra-long text rendering, multilingual typography, high-resolution photorealism, robust instruction following, and efficient deployment, especially in text-rich and compositionally complex scenarios. Qwen-Image-2.0 addresses these challenges by coupling Qwen3-VL as the condition encoder with a Multimodal Diffusion Transformer for joint condition-target modeling, supported by large-scale data curation and a customized multi-stage training pipeline. This enables strong multimodal understanding while preserving flexible generation and editing capabilities. The model supports instructions of up to 1K tokens for generating text-rich content such as slides, posters, infographics, and comics, while significantly improving multilingual text fidelity and typography. It also enhances photorealistic generation with richer details, more realistic textures, and coherent lighting, and follows complex prompts more reliably across diverse styles. Extensive human evaluations show that Qwen-Image-2.0 substantially outperforms previous Qwen-Image models in both generation and editing, marking a step toward more general, reliable, and practical image generation foundation models.
AnySplat: Feed-forward 3D Gaussian Splatting from Unconstrained Views
May 29, 2025We introduce AnySplat, a feed forward network for novel view synthesis from uncalibrated image collections. In contrast to traditional neural rendering pipelines that demand known camera poses and per scene optimization, or recent feed forward methods that buckle under the computational weight of dense views, our model predicts everything in one shot. A single forward pass yields a set of 3D Gaussian primitives encoding both scene geometry and appearance, and the corresponding camera intrinsics and extrinsics for each input image. This unified design scales effortlessly to casually captured, multi view datasets without any pose annotations. In extensive zero shot evaluations, AnySplat matches the quality of pose aware baselines in both sparse and dense view scenarios while surpassing existing pose free approaches. Moreover, it greatly reduce rendering latency compared to optimization based neural fields, bringing real time novel view synthesis within reach for unconstrained capture settings.Project page: https://city-super.github.io/anysplat/
MV-CoLight: Efficient Object Compositing with Consistent Lighting and Shadow Generation
May 27, 2025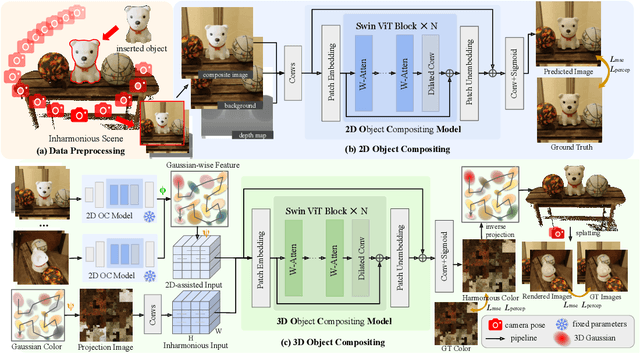
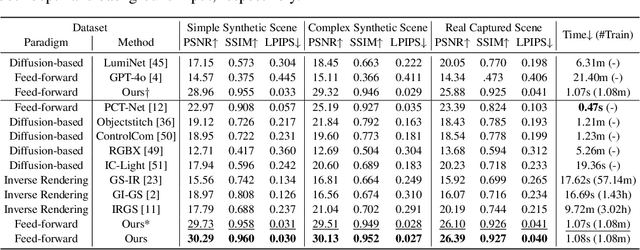
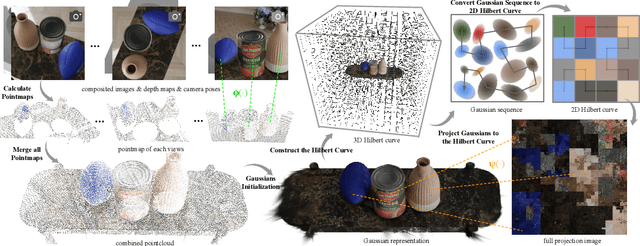
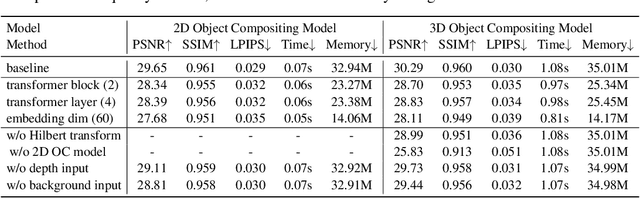
Object compositing offers significant promise for augmented reality (AR) and embodied intelligence applications. Existing approaches predominantly focus on single-image scenarios or intrinsic decomposition techniques, facing challenges with multi-view consistency, complex scenes, and diverse lighting conditions. Recent inverse rendering advancements, such as 3D Gaussian and diffusion-based methods, have enhanced consistency but are limited by scalability, heavy data requirements, or prolonged reconstruction time per scene. To broaden its applicability, we introduce MV-CoLight, a two-stage framework for illumination-consistent object compositing in both 2D images and 3D scenes. Our novel feed-forward architecture models lighting and shadows directly, avoiding the iterative biases of diffusion-based methods. We employ a Hilbert curve-based mapping to align 2D image inputs with 3D Gaussian scene representations seamlessly. To facilitate training and evaluation, we further introduce a large-scale 3D compositing dataset. Experiments demonstrate state-of-the-art harmonized results across standard benchmarks and our dataset, as well as casually captured real-world scenes demonstrate the framework's robustness and wide generalization.
Scene4U: Hierarchical Layered 3D Scene Reconstruction from Single Panoramic Image for Your Immerse Exploration
Apr 01, 2025The reconstruction of immersive and realistic 3D scenes holds significant practical importance in various fields of computer vision and computer graphics. Typically, immersive and realistic scenes should be free from obstructions by dynamic objects, maintain global texture consistency, and allow for unrestricted exploration. The current mainstream methods for image-driven scene construction involves iteratively refining the initial image using a moving virtual camera to generate the scene. However, previous methods struggle with visual discontinuities due to global texture inconsistencies under varying camera poses, and they frequently exhibit scene voids caused by foreground-background occlusions. To this end, we propose a novel layered 3D scene reconstruction framework from panoramic image, named Scene4U. Specifically, Scene4U integrates an open-vocabulary segmentation model with a large language model to decompose a real panorama into multiple layers. Then, we employs a layered repair module based on diffusion model to restore occluded regions using visual cues and depth information, generating a hierarchical representation of the scene. The multi-layer panorama is then initialized as a 3D Gaussian Splatting representation, followed by layered optimization, which ultimately produces an immersive 3D scene with semantic and structural consistency that supports free exploration. Scene4U outperforms state-of-the-art method, improving by 24.24% in LPIPS and 24.40% in BRISQUE, while also achieving the fastest training speed. Additionally, to demonstrate the robustness of Scene4U and allow users to experience immersive scenes from various landmarks, we build WorldVista3D dataset for 3D scene reconstruction, which contains panoramic images of globally renowned sites. The implementation code and dataset will be released at https://github.com/LongHZ140516/Scene4U .
Horizon-GS: Unified 3D Gaussian Splatting for Large-Scale Aerial-to-Ground Scenes
Dec 02, 2024



Seamless integration of both aerial and street view images remains a significant challenge in neural scene reconstruction and rendering. Existing methods predominantly focus on single domain, limiting their applications in immersive environments, which demand extensive free view exploration with large view changes both horizontally and vertically. We introduce Horizon-GS, a novel approach built upon Gaussian Splatting techniques, tackles the unified reconstruction and rendering for aerial and street views. Our method addresses the key challenges of combining these perspectives with a new training strategy, overcoming viewpoint discrepancies to generate high-fidelity scenes. We also curate a high-quality aerial-to-ground views dataset encompassing both synthetic and real-world scene to advance further research. Experiments across diverse urban scene datasets confirm the effectiveness of our method.
Octree-GS: Towards Consistent Real-time Rendering with LOD-Structured 3D Gaussians
Mar 26, 2024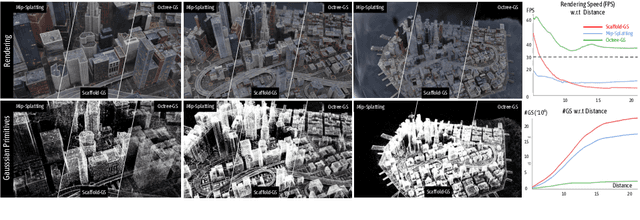



The recent 3D Gaussian splatting (3D-GS) has shown remarkable rendering fidelity and efficiency compared to NeRF-based neural scene representations. While demonstrating the potential for real-time rendering, 3D-GS encounters rendering bottlenecks in large scenes with complex details due to an excessive number of Gaussian primitives located within the viewing frustum. This limitation is particularly noticeable in zoom-out views and can lead to inconsistent rendering speeds in scenes with varying details. Moreover, it often struggles to capture the corresponding level of details at different scales with its heuristic density control operation. Inspired by the Level-of-Detail (LOD) techniques, we introduce Octree-GS, featuring an LOD-structured 3D Gaussian approach supporting level-of-detail decomposition for scene representation that contributes to the final rendering results. Our model dynamically selects the appropriate level from the set of multi-resolution anchor points, ensuring consistent rendering performance with adaptive LOD adjustments while maintaining high-fidelity rendering results.
GSDF: 3DGS Meets SDF for Improved Rendering and Reconstruction
Mar 25, 2024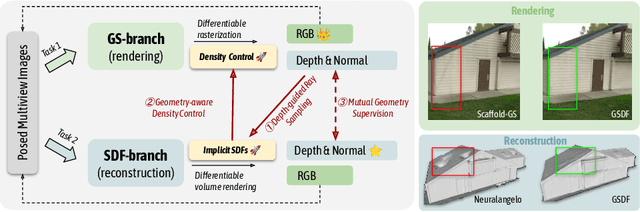
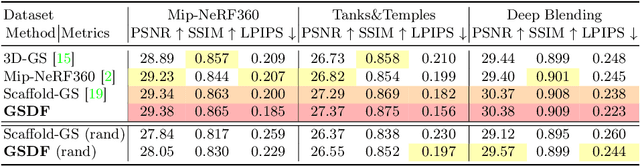
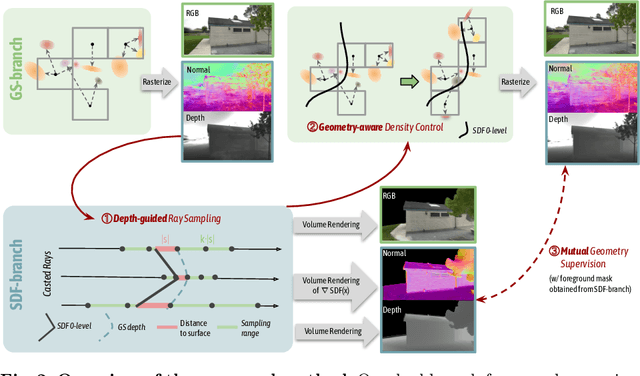

Presenting a 3D scene from multiview images remains a core and long-standing challenge in computer vision and computer graphics. Two main requirements lie in rendering and reconstruction. Notably, SOTA rendering quality is usually achieved with neural volumetric rendering techniques, which rely on aggregated point/primitive-wise color and neglect the underlying scene geometry. Learning of neural implicit surfaces is sparked from the success of neural rendering. Current works either constrain the distribution of density fields or the shape of primitives, resulting in degraded rendering quality and flaws on the learned scene surfaces. The efficacy of such methods is limited by the inherent constraints of the chosen neural representation, which struggles to capture fine surface details, especially for larger, more intricate scenes. To address these issues, we introduce GSDF, a novel dual-branch architecture that combines the benefits of a flexible and efficient 3D Gaussian Splatting (3DGS) representation with neural Signed Distance Fields (SDF). The core idea is to leverage and enhance the strengths of each branch while alleviating their limitation through mutual guidance and joint supervision. We show on diverse scenes that our design unlocks the potential for more accurate and detailed surface reconstructions, and at the meantime benefits 3DGS rendering with structures that are more aligned with the underlying geometry.