 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTalkVerse: Democratizing Minute-Long Audio-Driven Video Generation
Dec 16, 2025We introduce TalkVerse, a large-scale, open corpus for single-person, audio-driven talking video generation designed to enable fair, reproducible comparison across methods. While current state-of-the-art systems rely on closed data or compute-heavy models, TalkVerse offers 2.3 million high-resolution (720p/1080p) audio-video synchronized clips totaling 6.3k hours. These are curated from over 60k hours of video via a transparent pipeline that includes scene-cut detection, aesthetic assessment, strict audio-visual synchronization checks, and comprehensive annotations including 2D skeletons and structured visual/audio-style captions. Leveraging TalkVerse, we present a reproducible 5B DiT baseline built on Wan2.2-5B. By utilizing a video VAE with a high downsampling ratio and a sliding window mechanism with motion-frame context, our model achieves minute-long generation with low drift. It delivers comparable lip-sync and visual quality to the 14B Wan-S2V model but with 10$\times$ lower inference cost. To enhance storytelling in long videos, we integrate an MLLM director to rewrite prompts based on audio and visual cues. Furthermore, our model supports zero-shot video dubbing via controlled latent noise injection. We open-source the dataset, training recipes, and 5B checkpoints to lower barriers for research in audio-driven human video generation. Project Page: https://zhenzhiwang.github.io/talkverse/
InterActHuman: Multi-Concept Human Animation with Layout-Aligned Audio Conditions
Jun 11, 2025



End-to-end human animation with rich multi-modal conditions, e.g., text, image and audio has achieved remarkable advancements in recent years. However, most existing methods could only animate a single subject and inject conditions in a global manner, ignoring scenarios that multiple concepts could appears in the same video with rich human-human interactions and human-object interactions. Such global assumption prevents precise and per-identity control of multiple concepts including humans and objects, therefore hinders applications. In this work, we discard the single-entity assumption and introduce a novel framework that enforces strong, region-specific binding of conditions from modalities to each identity's spatiotemporal footprint. Given reference images of multiple concepts, our method could automatically infer layout information by leveraging a mask predictor to match appearance cues between the denoised video and each reference appearance. Furthermore, we inject local audio condition into its corresponding region to ensure layout-aligned modality matching in a iterative manner. This design enables the high-quality generation of controllable multi-concept human-centric videos. Empirical results and ablation studies validate the effectiveness of our explicit layout control for multi-modal conditions compared to implicit counterparts and other existing methods.
Multi-identity Human Image Animation with Structural Video Diffusion
Apr 05, 2025Generating human videos from a single image while ensuring high visual quality and precise control is a challenging task, especially in complex scenarios involving multiple individuals and interactions with objects. Existing methods, while effective for single-human cases, often fail to handle the intricacies of multi-identity interactions because they struggle to associate the correct pairs of human appearance and pose condition and model the distribution of 3D-aware dynamics. To address these limitations, we present Structural Video Diffusion, a novel framework designed for generating realistic multi-human videos. Our approach introduces two core innovations: identity-specific embeddings to maintain consistent appearances across individuals and a structural learning mechanism that incorporates depth and surface-normal cues to model human-object interactions. Additionally, we expand existing human video dataset with 25K new videos featuring diverse multi-human and object interaction scenarios, providing a robust foundation for training. Experimental results demonstrate that Structural Video Diffusion achieves superior performance in generating lifelike, coherent videos for multiple subjects with dynamic and rich interactions, advancing the state of human-centric video generation.
Proc-GS: Procedural Building Generation for City Assembly with 3D Gaussians
Dec 10, 2024



Buildings are primary components of cities, often featuring repeated elements such as windows and doors. Traditional 3D building asset creation is labor-intensive and requires specialized skills to develop design rules. Recent generative models for building creation often overlook these patterns, leading to low visual fidelity and limited scalability. Drawing inspiration from procedural modeling techniques used in the gaming and visual effects industry, our method, Proc-GS, integrates procedural code into the 3D Gaussian Splatting (3D-GS) framework, leveraging their advantages in high-fidelity rendering and efficient asset management from both worlds. By manipulating procedural code, we can streamline this process and generate an infinite variety of buildings. This integration significantly reduces model size by utilizing shared foundational assets, enabling scalable generation with precise control over building assembly. We showcase the potential for expansive cityscape generation while maintaining high rendering fidelity and precise control on both real and synthetic cases.
HumanVid: Demystifying Training Data for Camera-controllable Human Image Animation
Jul 28, 2024

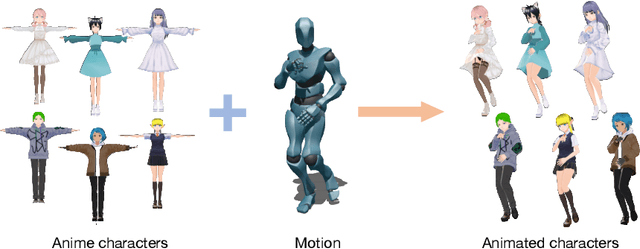
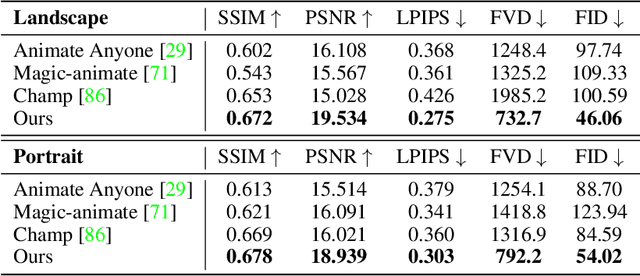
Human image animation involves generating videos from a character photo, allowing user control and unlocking potential for video and movie production. While recent approaches yield impressive results using high-quality training data, the inaccessibility of these datasets hampers fair and transparent benchmarking. Moreover, these approaches prioritize 2D human motion and overlook the significance of camera motions in videos, leading to limited control and unstable video generation. To demystify the training data, we present HumanVid, the first large-scale high-quality dataset tailored for human image animation, which combines crafted real-world and synthetic data. For the real-world data, we compile a vast collection of copyright-free real-world videos from the internet. Through a carefully designed rule-based filtering strategy, we ensure the inclusion of high-quality videos, resulting in a collection of 20K human-centric videos in 1080P resolution. Human and camera motion annotation is accomplished using a 2D pose estimator and a SLAM-based method. For the synthetic data, we gather 2,300 copyright-free 3D avatar assets to augment existing available 3D assets. Notably, we introduce a rule-based camera trajectory generation method, enabling the synthetic pipeline to incorporate diverse and precise camera motion annotation, which can rarely be found in real-world data. To verify the effectiveness of HumanVid, we establish a baseline model named CamAnimate, short for Camera-controllable Human Animation, that considers both human and camera motions as conditions. Through extensive experimentation, we demonstrate that such simple baseline training on our HumanVid achieves state-of-the-art performance in controlling both human pose and camera motions, setting a new benchmark. Code and data will be publicly available at https://github.com/zhenzhiwang/HumanVid/.
InterControl: Generate Human Motion Interactions by Controlling Every Joint
Nov 27, 2023



Text-conditioned human motion generation model has achieved great progress by introducing diffusion models and corresponding control signals. However, the interaction between humans are still under explored. To model interactions of arbitrary number of humans, we define interactions as human joint pairs that are either in contact or separated, and leverage {\em Large Language Model (LLM) Planner} to translate interaction descriptions into contact plans. Based on the contact plans, interaction generation could be achieved by spatially controllable motion generation methods by taking joint contacts as spatial conditions. We present a novel approach named InterControl for flexible spatial control of every joint in every person at any time by leveraging motion diffusion model only trained on single-person data. We incorporate a motion controlnet to generate coherent and realistic motions given sparse spatial control signals and a loss guidance module to precisely align any joint to the desired position in a classifier guidance manner via Inverse Kinematics (IK). Extensive experiments on HumanML3D and KIT-ML dataset demonstrate its effectiveness in versatile joint control. We also collect data of joint contact pairs by LLMs to show InterControl's ability in human interaction generation.
MatrixCity: A Large-scale City Dataset for City-scale Neural Rendering and Beyond
Sep 28, 2023



Neural radiance fields (NeRF) and its subsequent variants have led to remarkable progress in neural rendering. While most of recent neural rendering works focus on objects and small-scale scenes, developing neural rendering methods for city-scale scenes is of great potential in many real-world applications. However, this line of research is impeded by the absence of a comprehensive and high-quality dataset, yet collecting such a dataset over real city-scale scenes is costly, sensitive, and technically difficult. To this end, we build a large-scale, comprehensive, and high-quality synthetic dataset for city-scale neural rendering researches. Leveraging the Unreal Engine 5 City Sample project, we develop a pipeline to easily collect aerial and street city views, accompanied by ground-truth camera poses and a range of additional data modalities. Flexible controls over environmental factors like light, weather, human and car crowd are also available in our pipeline, supporting the need of various tasks covering city-scale neural rendering and beyond. The resulting pilot dataset, MatrixCity, contains 67k aerial images and 452k street images from two city maps of total size $28km^2$. On top of MatrixCity, a thorough benchmark is also conducted, which not only reveals unique challenges of the task of city-scale neural rendering, but also highlights potential improvements for future works. The dataset and code will be publicly available at our project page: https://city-super.github.io/matrixcity/.
Overview of Tencent Multi-modal Ads Video Understanding Challenge
Sep 16, 2021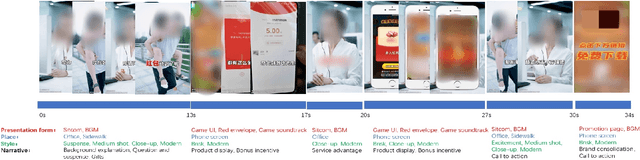
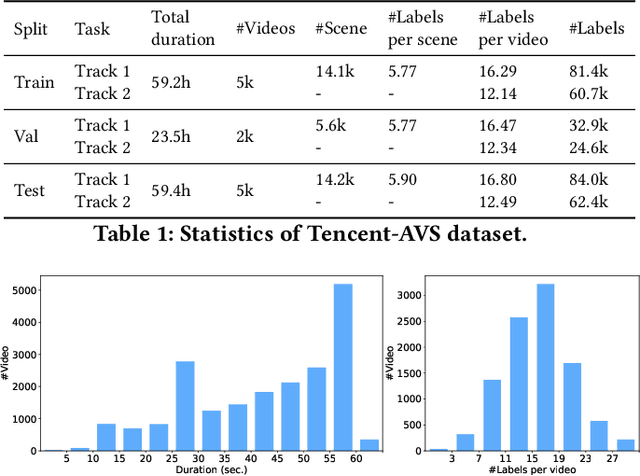
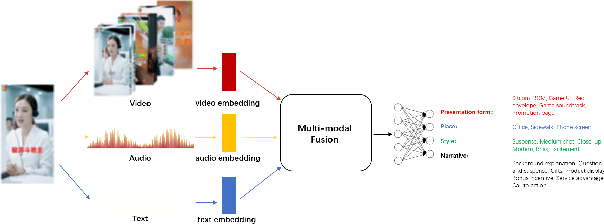
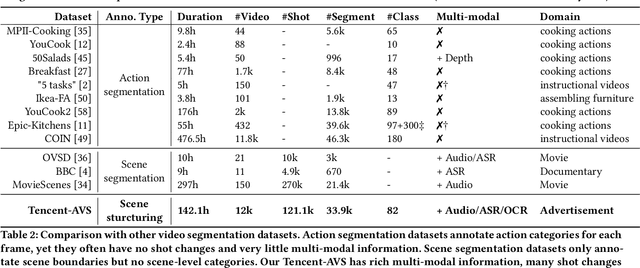
Multi-modal Ads Video Understanding Challenge is the first grand challenge aiming to comprehensively understand ads videos. Our challenge includes two tasks: video structuring in the temporal dimension and multi-modal video classification. It asks the participants to accurately predict both the scene boundaries and the multi-label categories of each scene based on a fine-grained and ads-related category hierarchy. Therefore, our task has four distinguishing features from previous ones: ads domain, multi-modal information, temporal segmentation, and multi-label classification. It will advance the foundation of ads video understanding and have a significant impact on many ads applications like video recommendation. This paper presents an overview of our challenge, including the background of ads videos, an elaborate description of task and dataset, evaluation protocol, and our proposed baseline. By ablating the key components of our baseline, we would like to reveal the main challenges of this task and provide useful guidance for future research of this area. In this paper, we give an extended version of our challenge overview. The dataset will be publicly available at https://algo.qq.com/.
Negative Sample Matters: A Renaissance of Metric Learning for Temporal Grounding
Sep 10, 2021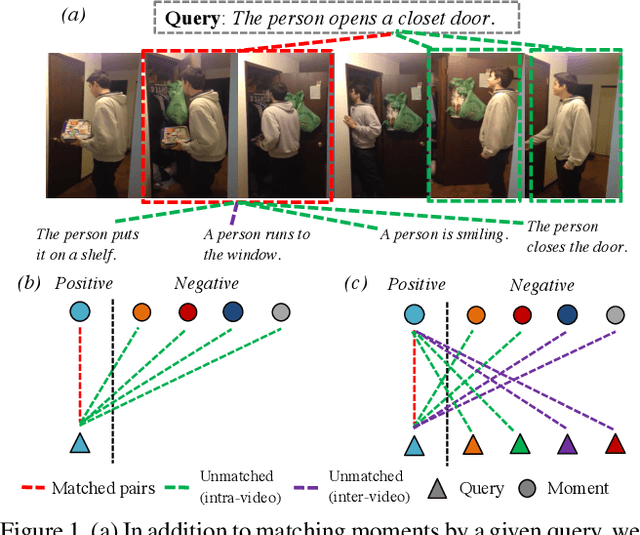

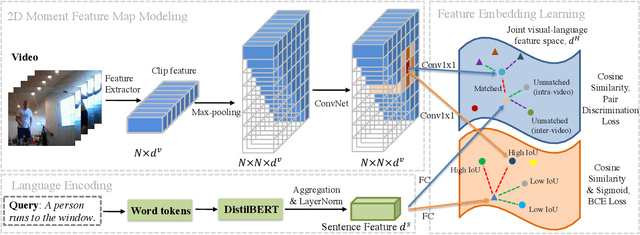
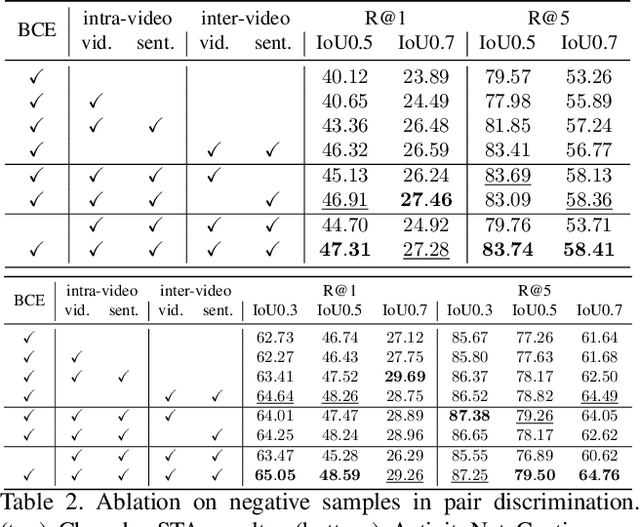
Temporal grounding aims to temporally localize a video moment in the video whose semantics are related to a given natural language query. Existing methods typically apply a detection or regression pipeline on the fused representation with a focus on designing complicated heads and fusion strategies. Instead, from a perspective on temporal grounding as a metric-learning problem, we present a Dual Matching Network (DMN), to directly model the relations between language queries and video moments in a joint embedding space. This new metric-learning framework enables fully exploiting negative samples from two new aspects: constructing negative cross-modal pairs from a dual matching scheme and mining negative pairs across different videos. These new negative samples could enhance the joint representation learning of two modalities via cross-modal pair discrimination to maximize their mutual information. Experiments show that DMN achieves highly competitive performance compared with state-of-the-art methods on four video grounding benchmarks. Based on DMN, we present a winner solution for STVG challenge of the 3rd PIC workshop. This suggests that metric-learning is still a promising method for temporal grounding via capturing the essential cross-modal correlation in a joint embedding space.
MultiSports: A Multi-Person Video Dataset of Spatio-Temporally Localized Sports Actions
May 16, 2021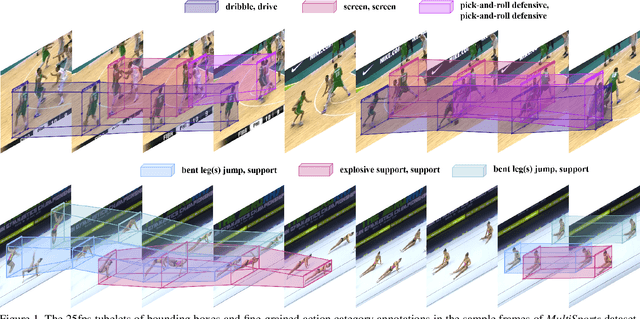
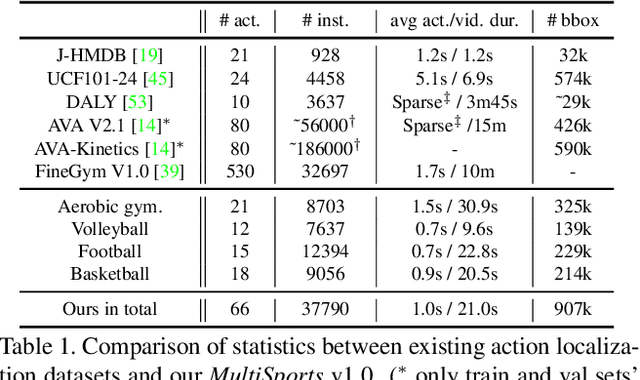
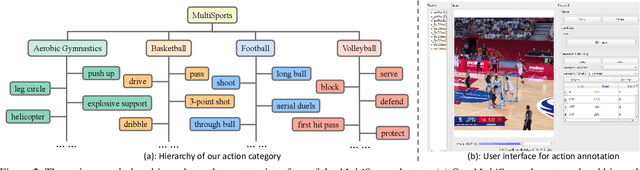

Spatio-temporal action detection is an important and challenging problem in video understanding. The existing action detection benchmarks are limited in aspects of small numbers of instances in a trimmed video or relatively low-level atomic actions. This paper aims to present a new multi-person dataset of spatio-temporal localized sports actions, coined as MultiSports. We first analyze the important ingredients of constructing a realistic and challenging dataset for spatio-temporal action detection by proposing three criteria: (1) motion dependent identification, (2) with well-defined boundaries, (3) relatively high-level classes. Based on these guidelines, we build the dataset of Multi-Sports v1.0 by selecting 4 sports classes, collecting around 3200 video clips, and annotating around 37790 action instances with 907k bounding boxes. Our datasets are characterized with important properties of strong diversity, detailed annotation, and high quality. Our MultiSports, with its realistic setting and dense annotations, exposes the intrinsic challenge of action localization. To benchmark this, we adapt several representative methods to our dataset and give an in-depth analysis on the difficulty of action localization in our dataset. We hope our MultiSports can serve as a standard benchmark for spatio-temporal action detection in the future. Our dataset website is at https://deeperaction.github.io/multisports/.