 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatioTemporal Focus for Skeleton-based Action Recognition
Mar 31, 2022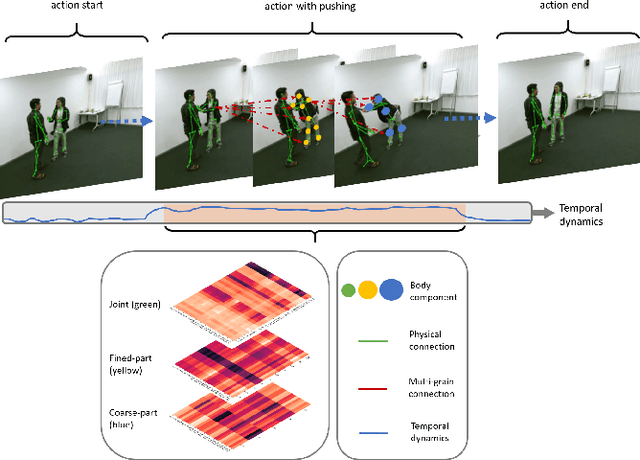
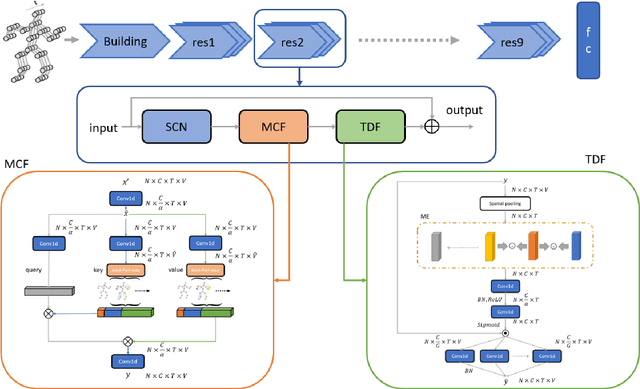
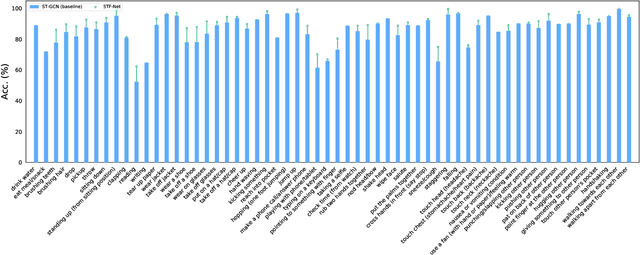
Graph convolutional networks (GCNs) are widely adopted in skeleton-based action recognition due to their powerful ability to model data topology. We argue that the performance of recent proposed skeleton-based action recognition methods is limited by the following factors. First, the predefined graph structures are shared throughout the network, lacking the flexibility and capacity to model the multi-grain semantic information. Second, the relations among the global joints are not fully exploited by the graph local convolution, which may lose the implicit joint relevance. For instance, actions such as running and waving are performed by the co-movement of body parts and joints, e.g., legs and arms, however, they are located far away in physical connection. Inspired by the recent attention mechanism, we propose a multi-grain contextual focus module, termed MCF, to capture the action associated relation information from the body joints and parts. As a result, more explainable representations for different skeleton action sequences can be obtained by MCF. In this study, we follow the common practice that the dense sample strategy of the input skeleton sequences is adopted and this brings much redundancy since number of instances has nothing to do with actions. To reduce the redundancy, a temporal discrimination focus module, termed TDF, is developed to capture the local sensitive points of the temporal dynamics. MCF and TDF are integrated into the standard GCN network to form a unified architecture, named STF-Net. It is noted that STF-Net provides the capability to capture robust movement patterns from these skeleton topology structures, based on multi-grain context aggregation and temporal dependency. Extensive experimental results show that our STF-Net significantly achieves state-of-the-art results on three challenging benchmarks NTU RGB+D 60, NTU RGB+D 120, and Kinetics-skeleton.
Overview of Tencent Multi-modal Ads Video Understanding Challenge
Sep 16, 2021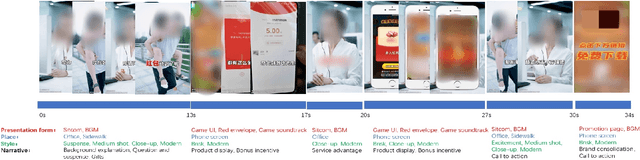
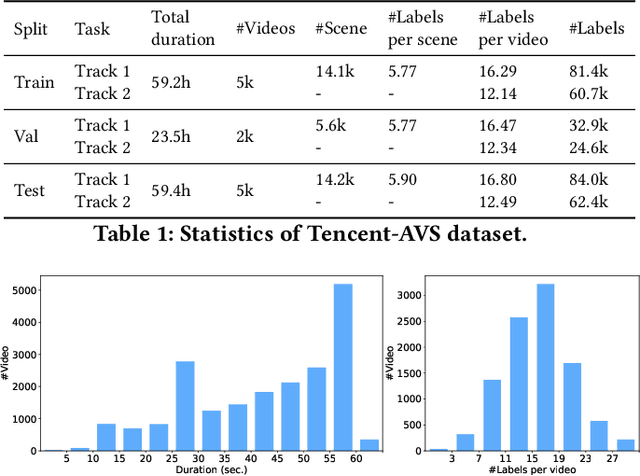
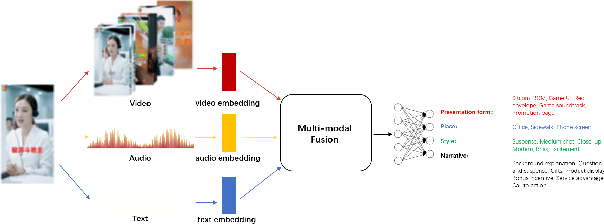
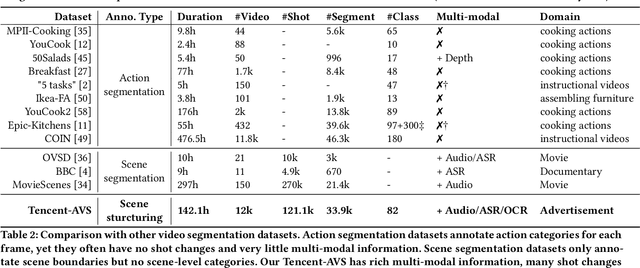
Multi-modal Ads Video Understanding Challenge is the first grand challenge aiming to comprehensively understand ads videos. Our challenge includes two tasks: video structuring in the temporal dimension and multi-modal video classification. It asks the participants to accurately predict both the scene boundaries and the multi-label categories of each scene based on a fine-grained and ads-related category hierarchy. Therefore, our task has four distinguishing features from previous ones: ads domain, multi-modal information, temporal segmentation, and multi-label classification. It will advance the foundation of ads video understanding and have a significant impact on many ads applications like video recommendation. This paper presents an overview of our challenge, including the background of ads videos, an elaborate description of task and dataset, evaluation protocol, and our proposed baseline. By ablating the key components of our baseline, we would like to reveal the main challenges of this task and provide useful guidance for future research of this area. In this paper, we give an extended version of our challenge overview. The dataset will be publicly available at https://algo.qq.com/.
Long-Short Temporal Modeling for Efficient Action Recognition
Jun 30, 2021



Efficient long-short temporal modeling is key for enhancing the performance of action recognition task. In this paper, we propose a new two-stream action recognition network, termed as MENet, consisting of a Motion Enhancement (ME) module and a Video-level Aggregation (VLA) module to achieve long-short temporal modeling. Specifically, motion representations have been proved effective in capturing short-term and high-frequency action. However, current motion representations are calculated from adjacent frames, which may have poor interpretation and bring useless information (noisy or blank). Thus, for short-term motions, we design an efficient ME module to enhance the short-term motions by mingling the motion saliency among neighboring segments. As for long-term aggregations, VLA is adopted at the top of the appearance branch to integrate the long-term dependencies across all segments. The two components of MENet are complementary in temporal modeling. Extensive experiments are conducted on UCF101 and HMDB51 benchmarks, which verify the effectiveness and efficiency of our proposed MENet.