 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatioTemporal Focus for Skeleton-based Action Recognition
Paper and Code
Mar 31, 2022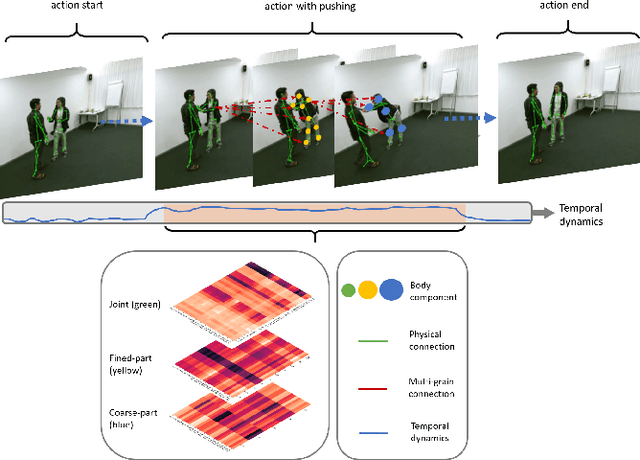
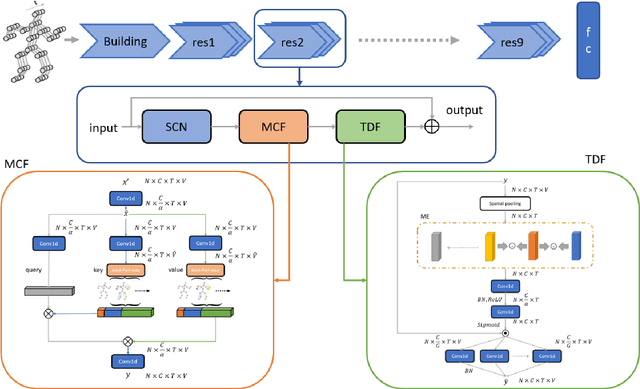
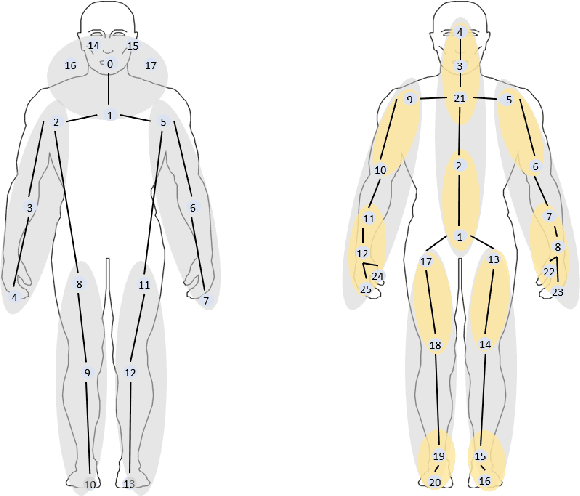
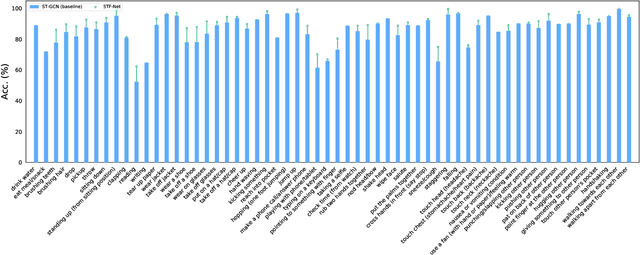
Graph convolutional networks (GCNs) are widely adopted in skeleton-based action recognition due to their powerful ability to model data topology. We argue that the performance of recent proposed skeleton-based action recognition methods is limited by the following factors. First, the predefined graph structures are shared throughout the network, lacking the flexibility and capacity to model the multi-grain semantic information. Second, the relations among the global joints are not fully exploited by the graph local convolution, which may lose the implicit joint relevance. For instance, actions such as running and waving are performed by the co-movement of body parts and joints, e.g., legs and arms, however, they are located far away in physical connection. Inspired by the recent attention mechanism, we propose a multi-grain contextual focus module, termed MCF, to capture the action associated relation information from the body joints and parts. As a result, more explainable representations for different skeleton action sequences can be obtained by MCF. In this study, we follow the common practice that the dense sample strategy of the input skeleton sequences is adopted and this brings much redundancy since number of instances has nothing to do with actions. To reduce the redundancy, a temporal discrimination focus module, termed TDF, is developed to capture the local sensitive points of the temporal dynamics. MCF and TDF are integrated into the standard GCN network to form a unified architecture, named STF-Net. It is noted that STF-Net provides the capability to capture robust movement patterns from these skeleton topology structures, based on multi-grain context aggregation and temporal dependency. Extensive experimental results show that our STF-Net significantly achieves state-of-the-art results on three challenging benchmarks NTU RGB+D 60, NTU RGB+D 120, and Kinetics-skeleton.