 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnd-to-End Training for Autoregressive Video Diffusion via Self-Resampling
Dec 17, 2025
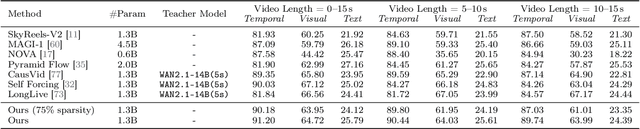
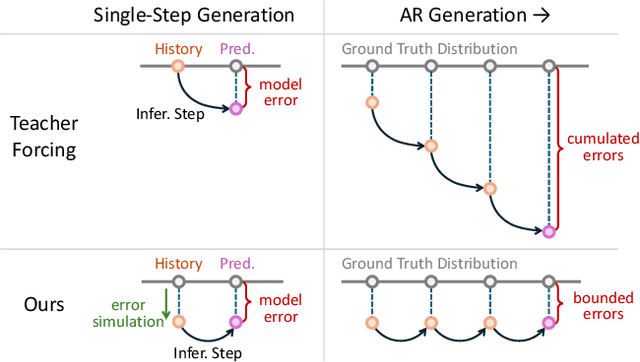

Autoregressive video diffusion models hold promise for world simulation but are vulnerable to exposure bias arising from the train-test mismatch. While recent works address this via post-training, they typically rely on a bidirectional teacher model or online discriminator. To achieve an end-to-end solution, we introduce Resampling Forcing, a teacher-free framework that enables training autoregressive video models from scratch and at scale. Central to our approach is a self-resampling scheme that simulates inference-time model errors on history frames during training. Conditioned on these degraded histories, a sparse causal mask enforces temporal causality while enabling parallel training with frame-level diffusion loss. To facilitate efficient long-horizon generation, we further introduce history routing, a parameter-free mechanism that dynamically retrieves the top-k most relevant history frames for each query. Experiments demonstrate that our approach achieves performance comparable to distillation-based baselines while exhibiting superior temporal consistency on longer videos owing to native-length training.
Composing Concepts from Images and Videos via Concept-prompt Binding
Dec 10, 2025Visual concept composition, which aims to integrate different elements from images and videos into a single, coherent visual output, still falls short in accurately extracting complex concepts from visual inputs and flexibly combining concepts from both images and videos. We introduce Bind & Compose, a one-shot method that enables flexible visual concept composition by binding visual concepts with corresponding prompt tokens and composing the target prompt with bound tokens from various sources. It adopts a hierarchical binder structure for cross-attention conditioning in Diffusion Transformers to encode visual concepts into corresponding prompt tokens for accurate decomposition of complex visual concepts. To improve concept-token binding accuracy, we design a Diversify-and-Absorb Mechanism that uses an extra absorbent token to eliminate the impact of concept-irrelevant details when training with diversified prompts. To enhance the compatibility between image and video concepts, we present a Temporal Disentanglement Strategy that decouples the training process of video concepts into two stages with a dual-branch binder structure for temporal modeling. Evaluations demonstrate that our method achieves superior concept consistency, prompt fidelity, and motion quality over existing approaches, opening up new possibilities for visual creativity.
Taming Flow-based I2V Models for Creative Video Editing
Sep 26, 2025Although image editing techniques have advanced significantly, video editing, which aims to manipulate videos according to user intent, remains an emerging challenge. Most existing image-conditioned video editing methods either require inversion with model-specific design or need extensive optimization, limiting their capability of leveraging up-to-date image-to-video (I2V) models to transfer the editing capability of image editing models to the video domain. To this end, we propose IF-V2V, an Inversion-Free method that can adapt off-the-shelf flow-matching-based I2V models for video editing without significant computational overhead. To circumvent inversion, we devise Vector Field Rectification with Sample Deviation to incorporate information from the source video into the denoising process by introducing a deviation term into the denoising vector field. To further ensure consistency with the source video in a model-agnostic way, we introduce Structure-and-Motion-Preserving Initialization to generate motion-aware temporally correlated noise with structural information embedded. We also present a Deviation Caching mechanism to minimize the additional computational cost for denoising vector rectification without significantly impacting editing quality. Evaluations demonstrate that our method achieves superior editing quality and consistency over existing approaches, offering a lightweight plug-and-play solution to realize visual creativity.
Mixture of Contexts for Long Video Generation
Aug 28, 2025Long video generation is fundamentally a long context memory problem: models must retain and retrieve salient events across a long range without collapsing or drifting. However, scaling diffusion transformers to generate long-context videos is fundamentally limited by the quadratic cost of self-attention, which makes memory and computation intractable and difficult to optimize for long sequences. We recast long-context video generation as an internal information retrieval task and propose a simple, learnable sparse attention routing module, Mixture of Contexts (MoC), as an effective long-term memory retrieval engine. In MoC, each query dynamically selects a few informative chunks plus mandatory anchors (caption, local windows) to attend to, with causal routing that prevents loop closures. As we scale the data and gradually sparsify the routing, the model allocates compute to salient history, preserving identities, actions, and scenes over minutes of content. Efficiency follows as a byproduct of retrieval (near-linear scaling), which enables practical training and synthesis, and the emergence of memory and consistency at the scale of minutes.
Captain Cinema: Towards Short Movie Generation
Jul 24, 2025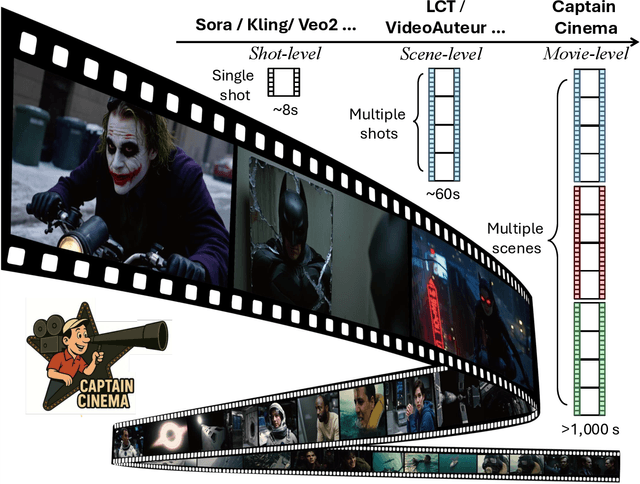
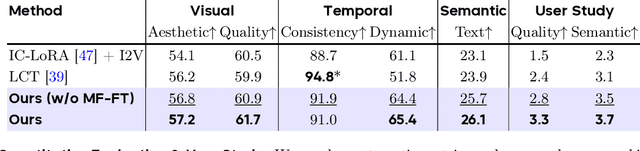

We present Captain Cinema, a generation framework for short movie generation. Given a detailed textual description of a movie storyline, our approach firstly generates a sequence of keyframes that outline the entire narrative, which ensures long-range coherence in both the storyline and visual appearance (e.g., scenes and characters). We refer to this step as top-down keyframe planning. These keyframes then serve as conditioning signals for a video synthesis model, which supports long context learning, to produce the spatio-temporal dynamics between them. This step is referred to as bottom-up video synthesis. To support stable and efficient generation of multi-scene long narrative cinematic works, we introduce an interleaved training strategy for Multimodal Diffusion Transformers (MM-DiT), specifically adapted for long-context video data. Our model is trained on a specially curated cinematic dataset consisting of interleaved data pairs. Our experiments demonstrate that Captain Cinema performs favorably in the automated creation of visually coherent and narrative consistent short movies in high quality and efficiency. Project page: https://thecinema.ai
Self-similarity Analysis in Deep Neural Networks
Jul 23, 2025Current research has found that some deep neural networks exhibit strong hierarchical self-similarity in feature representation or parameter distribution. However, aside from preliminary studies on how the power-law distribution of weights across different training stages affects model performance,there has been no quantitative analysis on how the self-similarity of hidden space geometry influences model weight optimization, nor is there a clear understanding of the dynamic behavior of internal neurons. Therefore, this paper proposes a complex network modeling method based on the output features of hidden-layer neurons to investigate the self-similarity of feature networks constructed at different hidden layers, and analyzes how adjusting the degree of self-similarity in feature networks can enhance the classification performance of deep neural networks. Validated on three types of networks MLP architectures, convolutional networks, and attention architectures this study reveals that the degree of self-similarity exhibited by feature networks varies across different model architectures. Furthermore, embedding constraints on the self-similarity of feature networks during the training process can improve the performance of self-similar deep neural networks (MLP architectures and attention architectures) by up to 6 percentage points.
UniTalk: Towards Universal Active Speaker Detection in Real World Scenarios
May 28, 2025We present UniTalk, a novel dataset specifically designed for the task of active speaker detection, emphasizing challenging scenarios to enhance model generalization. Unlike previously established benchmarks such as AVA, which predominantly features old movies and thus exhibits significant domain gaps, UniTalk focuses explicitly on diverse and difficult real-world conditions. These include underrepresented languages, noisy backgrounds, and crowded scenes - such as multiple visible speakers speaking concurrently or in overlapping turns. It contains over 44.5 hours of video with frame-level active speaker annotations across 48,693 speaking identities, and spans a broad range of video types that reflect real-world conditions. Through rigorous evaluation, we show that state-of-the-art models, while achieving nearly perfect scores on AVA, fail to reach saturation on UniTalk, suggesting that the ASD task remains far from solved under realistic conditions. Nevertheless, models trained on UniTalk demonstrate stronger generalization to modern "in-the-wild" datasets like Talkies and ASW, as well as to AVA. UniTalk thus establishes a new benchmark for active speaker detection, providing researchers with a valuable resource for developing and evaluating versatile and resilient models. Dataset: https://huggingface.co/datasets/plnguyen2908/UniTalk-ASD Code: https://github.com/plnguyen2908/UniTalk-ASD-code
Multi-identity Human Image Animation with Structural Video Diffusion
Apr 05, 2025Generating human videos from a single image while ensuring high visual quality and precise control is a challenging task, especially in complex scenarios involving multiple individuals and interactions with objects. Existing methods, while effective for single-human cases, often fail to handle the intricacies of multi-identity interactions because they struggle to associate the correct pairs of human appearance and pose condition and model the distribution of 3D-aware dynamics. To address these limitations, we present Structural Video Diffusion, a novel framework designed for generating realistic multi-human videos. Our approach introduces two core innovations: identity-specific embeddings to maintain consistent appearances across individuals and a structural learning mechanism that incorporates depth and surface-normal cues to model human-object interactions. Additionally, we expand existing human video dataset with 25K new videos featuring diverse multi-human and object interaction scenarios, providing a robust foundation for training. Experimental results demonstrate that Structural Video Diffusion achieves superior performance in generating lifelike, coherent videos for multiple subjects with dynamic and rich interactions, advancing the state of human-centric video generation.
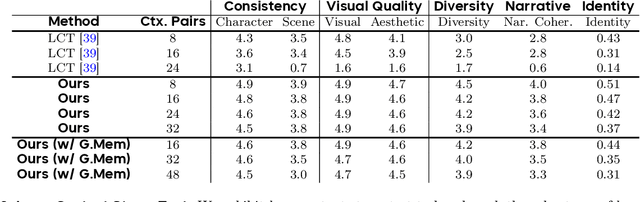
Long Context Tuning for Video Generation
Mar 13, 2025Recent advances in video generation can produce realistic, minute-long single-shot videos with scalable diffusion transformers. However, real-world narrative videos require multi-shot scenes with visual and dynamic consistency across shots. In this work, we introduce Long Context Tuning (LCT), a training paradigm that expands the context window of pre-trained single-shot video diffusion models to learn scene-level consistency directly from data. Our method expands full attention mechanisms from individual shots to encompass all shots within a scene, incorporating interleaved 3D position embedding and an asynchronous noise strategy, enabling both joint and auto-regressive shot generation without additional parameters. Models with bidirectional attention after LCT can further be fine-tuned with context-causal attention, facilitating auto-regressive generation with efficient KV-cache. Experiments demonstrate single-shot models after LCT can produce coherent multi-shot scenes and exhibit emerging capabilities, including compositional generation and interactive shot extension, paving the way for more practical visual content creation. See https://guoyww.github.io/projects/long-context-video/ for more details.
Simulating the Real World: A Unified Survey of Multimodal Generative Models
Mar 06, 2025



Understanding and replicating the real world is a critical challenge in Artificial General Intelligence (AGI) research. To achieve this, many existing approaches, such as world models, aim to capture the fundamental principles governing the physical world, enabling more accurate simulations and meaningful interactions. However, current methods often treat different modalities, including 2D (images), videos, 3D, and 4D representations, as independent domains, overlooking their interdependencies. Additionally, these methods typically focus on isolated dimensions of reality without systematically integrating their connections. In this survey, we present a unified survey for multimodal generative models that investigate the progression of data dimensionality in real-world simulation. Specifically, this survey starts from 2D generation (appearance), then moves to video (appearance+dynamics) and 3D generation (appearance+geometry), and finally culminates in 4D generation that integrate all dimensions. To the best of our knowledge, this is the first attempt to systematically unify the study of 2D, video, 3D and 4D generation within a single framework. To guide future research, we provide a comprehensive review of datasets, evaluation metrics and future directions, and fostering insights for newcomers. This survey serves as a bridge to advance the study of multimodal generative models and real-world simulation within a unified framework.