 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContinuous Adversarial Flow Models
Apr 13, 2026We propose continuous adversarial flow models, a type of continuous-time flow model trained with an adversarial objective. Unlike flow matching, which uses a fixed mean-squared-error criterion, our approach introduces a learned discriminator to guide training. This change in objective induces a different generalized distribution, which empirically produces samples that are better aligned with the target data distribution. Our method is primarily proposed for post-training existing flow-matching models, although it can also train models from scratch. On the ImageNet 256px generation task, our post-training substantially improves the guidance-free FID of latent-space SiT from 8.26 to 3.63 and of pixel-space JiT from 7.17 to 3.57. It also improves guided generation, reducing FID from 2.06 to 1.53 for SiT and from 1.86 to 1.80 for JiT. We further evaluate our approach on text-to-image generation, where it achieves improved results on both the GenEval and DPG benchmarks.
Cubic Discrete Diffusion: Discrete Visual Generation on High-Dimensional Representation Tokens
Mar 19, 2026Visual generation with discrete tokens has gained significant attention as it enables a unified token prediction paradigm shared with language models, promising seamless multimodal architectures. However, current discrete generation methods remain limited to low-dimensional latent tokens (typically 8-32 dims), sacrificing the semantic richness essential for understanding. While high-dimensional pretrained representations (768-1024 dims) could bridge this gap, their discrete generation poses fundamental challenges. In this paper, we present Cubic Discrete Diffusion (CubiD), the first discrete generation model for high-dimensional representations. CubiD performs fine-grained masking throughout the high-dimensional discrete representation -- any dimension at any position can be masked and predicted from partial observations. This enables the model to learn rich correlations both within and across spatial positions, with the number of generation steps fixed at $T$ regardless of feature dimensionality, where $T \ll hwd$. On ImageNet-256, CubiD achieves state-of-the-art discrete generation with strong scaling behavior from 900M to 3.7B parameters. Crucially, we validate that these discretized tokens preserve original representation capabilities, demonstrating that the same discrete tokens can effectively serve both understanding and generation tasks. We hope this work will inspire future research toward unified multimodal architectures. Code is available at: https://github.com/YuqingWang1029/CubiD.
EVATok: Adaptive Length Video Tokenization for Efficient Visual Autoregressive Generation
Mar 12, 2026Autoregressive (AR) video generative models rely on video tokenizers that compress pixels into discrete token sequences. The length of these token sequences is crucial for balancing reconstruction quality against downstream generation computational cost. Traditional video tokenizers apply a uniform token assignment across temporal blocks of different videos, often wasting tokens on simple, static, or repetitive segments while underserving dynamic or complex ones. To address this inefficiency, we introduce $\textbf{EVATok}$, a framework to produce $\textbf{E}$fficient $\textbf{V}$ideo $\textbf{A}$daptive $\textbf{Tok}$enizers. Our framework estimates optimal token assignments for each video to achieve the best quality-cost trade-off, develops lightweight routers for fast prediction of these optimal assignments, and trains adaptive tokenizers that encode videos based on the assignments predicted by routers. We demonstrate that EVATok delivers substantial improvements in efficiency and overall quality for video reconstruction and downstream AR generation. Enhanced by our advanced training recipe that integrates video semantic encoders, EVATok achieves superior reconstruction and state-of-the-art class-to-video generation on UCF-101, with at least 24.4% savings in average token usage compared to the prior state-of-the-art LARP and our fixed-length baseline.
Seedance 1.5 pro: A Native Audio-Visual Joint Generation Foundation Model
Dec 23, 2025Recent strides in video generation have paved the way for unified audio-visual generation. In this work, we present Seedance 1.5 pro, a foundational model engineered specifically for native, joint audio-video generation. Leveraging a dual-branch Diffusion Transformer architecture, the model integrates a cross-modal joint module with a specialized multi-stage data pipeline, achieving exceptional audio-visual synchronization and superior generation quality. To ensure practical utility, we implement meticulous post-training optimizations, including Supervised Fine-Tuning (SFT) on high-quality datasets and Reinforcement Learning from Human Feedback (RLHF) with multi-dimensional reward models. Furthermore, we introduce an acceleration framework that boosts inference speed by over 10X. Seedance 1.5 pro distinguishes itself through precise multilingual and dialect lip-syncing, dynamic cinematic camera control, and enhanced narrative coherence, positioning it as a robust engine for professional-grade content creation. Seedance 1.5 pro is now accessible on Volcano Engine at https://console.volcengine.com/ark/region:ark+cn-beijing/experience/vision?type=GenVideo.
Seedance 1.0: Exploring the Boundaries of Video Generation Models
Jun 10, 2025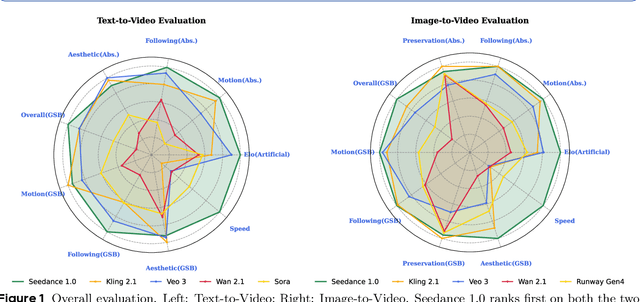
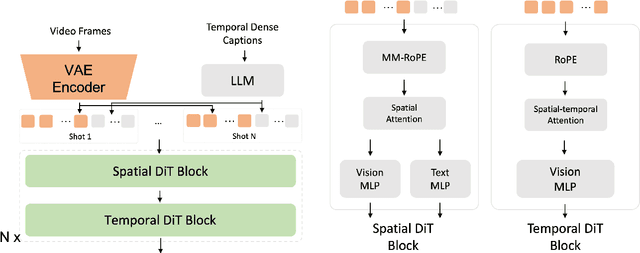
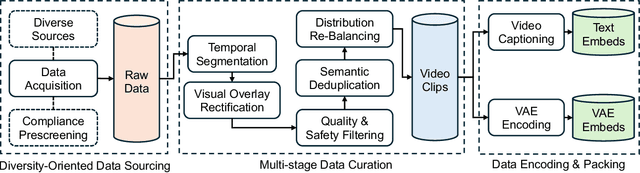
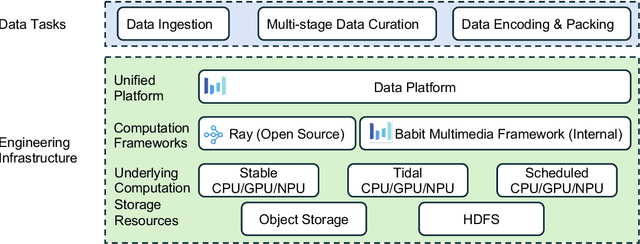
Notable breakthroughs in diffusion modeling have propelled rapid improvements in video generation, yet current foundational model still face critical challenges in simultaneously balancing prompt following, motion plausibility, and visual quality. In this report, we introduce Seedance 1.0, a high-performance and inference-efficient video foundation generation model that integrates several core technical improvements: (i) multi-source data curation augmented with precision and meaningful video captioning, enabling comprehensive learning across diverse scenarios; (ii) an efficient architecture design with proposed training paradigm, which allows for natively supporting multi-shot generation and jointly learning of both text-to-video and image-to-video tasks. (iii) carefully-optimized post-training approaches leveraging fine-grained supervised fine-tuning, and video-specific RLHF with multi-dimensional reward mechanisms for comprehensive performance improvements; (iv) excellent model acceleration achieving ~10x inference speedup through multi-stage distillation strategies and system-level optimizations. Seedance 1.0 can generate a 5-second video at 1080p resolution only with 41.4 seconds (NVIDIA-L20). Compared to state-of-the-art video generation models, Seedance 1.0 stands out with high-quality and fast video generation having superior spatiotemporal fluidity with structural stability, precise instruction adherence in complex multi-subject contexts, native multi-shot narrative coherence with consistent subject representation.
SeedVR2: One-Step Video Restoration via Diffusion Adversarial Post-Training
Jun 05, 2025



Recent advances in diffusion-based video restoration (VR) demonstrate significant improvement in visual quality, yet yield a prohibitive computational cost during inference. While several distillation-based approaches have exhibited the potential of one-step image restoration, extending existing approaches to VR remains challenging and underexplored, particularly when dealing with high-resolution video in real-world settings. In this work, we propose a one-step diffusion-based VR model, termed as SeedVR2, which performs adversarial VR training against real data. To handle the challenging high-resolution VR within a single step, we introduce several enhancements to both model architecture and training procedures. Specifically, an adaptive window attention mechanism is proposed, where the window size is dynamically adjusted to fit the output resolutions, avoiding window inconsistency observed under high-resolution VR using window attention with a predefined window size. To stabilize and improve the adversarial post-training towards VR, we further verify the effectiveness of a series of losses, including a proposed feature matching loss without significantly sacrificing training efficiency. Extensive experiments show that SeedVR2 can achieve comparable or even better performance compared with existing VR approaches in a single step.
Seaweed-7B: Cost-Effective Training of Video Generation Foundation Model
Apr 11, 2025
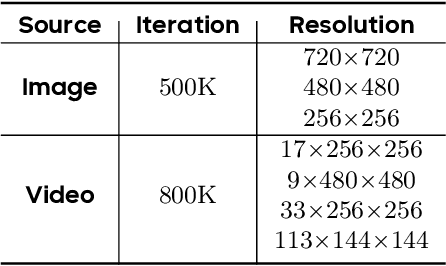

This technical report presents a cost-efficient strategy for training a video generation foundation model. We present a mid-sized research model with approximately 7 billion parameters (7B) called Seaweed-7B trained from scratch using 665,000 H100 GPU hours. Despite being trained with moderate computational resources, Seaweed-7B demonstrates highly competitive performance compared to contemporary video generation models of much larger size. Design choices are especially crucial in a resource-constrained setting. This technical report highlights the key design decisions that enhance the performance of the medium-sized diffusion model. Empirically, we make two observations: (1) Seaweed-7B achieves performance comparable to, or even surpasses, larger models trained on substantially greater GPU resources, and (2) our model, which exhibits strong generalization ability, can be effectively adapted across a wide range of downstream applications either by lightweight fine-tuning or continue training. See the project page at https://seaweed.video/
Bridging Continuous and Discrete Tokens for Autoregressive Visual Generation
Mar 20, 2025Autoregressive visual generation models typically rely on tokenizers to compress images into tokens that can be predicted sequentially. A fundamental dilemma exists in token representation: discrete tokens enable straightforward modeling with standard cross-entropy loss, but suffer from information loss and tokenizer training instability; continuous tokens better preserve visual details, but require complex distribution modeling, complicating the generation pipeline. In this paper, we propose TokenBridge, which bridges this gap by maintaining the strong representation capacity of continuous tokens while preserving the modeling simplicity of discrete tokens. To achieve this, we decouple discretization from the tokenizer training process through post-training quantization that directly obtains discrete tokens from continuous representations. Specifically, we introduce a dimension-wise quantization strategy that independently discretizes each feature dimension, paired with a lightweight autoregressive prediction mechanism that efficiently model the resulting large token space. Extensive experiments show that our approach achieves reconstruction and generation quality on par with continuous methods while using standard categorical prediction. This work demonstrates that bridging discrete and continuous paradigms can effectively harness the strengths of both approaches, providing a promising direction for high-quality visual generation with simple autoregressive modeling. Project page: https://yuqingwang1029.github.io/TokenBridge.
Long Context Tuning for Video Generation
Mar 13, 2025
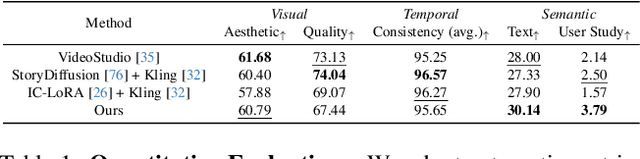

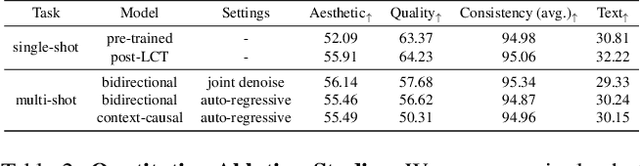
Recent advances in video generation can produce realistic, minute-long single-shot videos with scalable diffusion transformers. However, real-world narrative videos require multi-shot scenes with visual and dynamic consistency across shots. In this work, we introduce Long Context Tuning (LCT), a training paradigm that expands the context window of pre-trained single-shot video diffusion models to learn scene-level consistency directly from data. Our method expands full attention mechanisms from individual shots to encompass all shots within a scene, incorporating interleaved 3D position embedding and an asynchronous noise strategy, enabling both joint and auto-regressive shot generation without additional parameters. Models with bidirectional attention after LCT can further be fine-tuned with context-causal attention, facilitating auto-regressive generation with efficient KV-cache. Experiments demonstrate single-shot models after LCT can produce coherent multi-shot scenes and exhibit emerging capabilities, including compositional generation and interactive shot extension, paving the way for more practical visual content creation. See https://guoyww.github.io/projects/long-context-video/ for more details.
SeedVR: Seeding Infinity in Diffusion Transformer Towards Generic Video Restoration
Jan 04, 2025
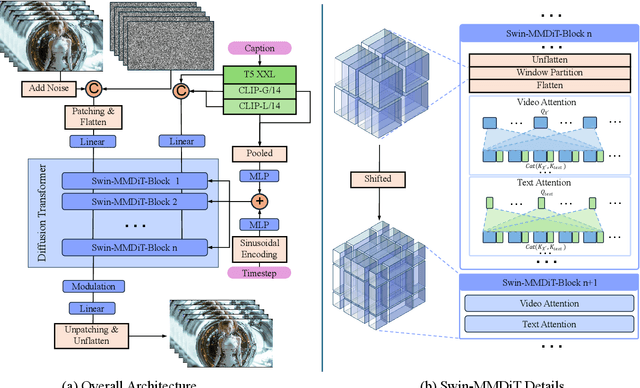


Video restoration poses non-trivial challenges in maintaining fidelity while recovering temporally consistent details from unknown degradations in the wild. Despite recent advances in diffusion-based restoration, these methods often face limitations in generation capability and sampling efficiency. In this work, we present SeedVR, a diffusion transformer designed to handle real-world video restoration with arbitrary length and resolution. The core design of SeedVR lies in the shifted window attention that facilitates effective restoration on long video sequences. SeedVR further supports variable-sized windows near the boundary of both spatial and temporal dimensions, overcoming the resolution constraints of traditional window attention. Equipped with contemporary practices, including causal video autoencoder, mixed image and video training, and progressive training, SeedVR achieves highly-competitive performance on both synthetic and real-world benchmarks, as well as AI-generated videos. Extensive experiments demonstrate SeedVR's superiority over existing methods for generic video restoration.