 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Pixel Histories: World Models with Persistent 3D State
Mar 03, 2026Interactive world models continually generate video by responding to a user's actions, enabling open-ended generation capabilities. However, existing models typically lack a 3D representation of the environment, meaning 3D consistency must be implicitly learned from data, and spatial memory is restricted to limited temporal context windows. This results in an unrealistic user experience and presents significant obstacles to down-stream tasks such as training agents. To address this, we present PERSIST, a new paradigm of world model which simulates the evolution of a latent 3D scene: environment, camera, and renderer. This allows us to synthesize new frames with persistent spatial memory and consistent geometry. Both quantitative metrics and a qualitative user study show substantial improvements in spatial memory, 3D consistency, and long-horizon stability over existing methods, enabling coherent, evolving 3D worlds. We further demonstrate novel capabilities, including synthesising diverse 3D environments from a single image, as well as enabling fine-grained, geometry-aware control over generated experiences by supporting environment editing and specification directly in 3D space. Project page: https://francelico.github.io/persist.github.io
Horizon Imagination: Efficient On-Policy Training in Diffusion World Models
Feb 08, 2026We study diffusion-based world models for reinforcement learning, which offer high generative fidelity but face critical efficiency challenges in control. Current methods either require heavyweight models at inference or rely on highly sequential imagination, both of which impose prohibitive computational costs. We propose Horizon Imagination (HI), an on-policy imagination process for discrete stochastic policies that denoises multiple future observations in parallel. HI incorporates a stabilization mechanism and a novel sampling schedule that decouples the denoising budget from the effective horizon over which denoising is applied while also supporting sub-frame budgets. Experiments on Atari 100K and Craftium show that our approach maintains control performance with a sub-frame budget of half the denoising steps and achieves superior generation quality under varied schedules. Code is available at https://github.com/leor-c/horizon-imagination.
Kimi K2.5: Visual Agentic Intelligence
Feb 02, 2026We introduce Kimi K2.5, an open-source multimodal agentic model designed to advance general agentic intelligence. K2.5 emphasizes the joint optimization of text and vision so that two modalities enhance each other. This includes a series of techniques such as joint text-vision pre-training, zero-vision SFT, and joint text-vision reinforcement learning. Building on this multimodal foundation, K2.5 introduces Agent Swarm, a self-directed parallel agent orchestration framework that dynamically decomposes complex tasks into heterogeneous sub-problems and executes them concurrently. Extensive evaluations show that Kimi K2.5 achieves state-of-the-art results across various domains including coding, vision, reasoning, and agentic tasks. Agent Swarm also reduces latency by up to $4.5\times$ over single-agent baselines. We release the post-trained Kimi K2.5 model checkpoint to facilitate future research and real-world applications of agentic intelligence.
How Do VLAs Effectively Inherit from VLMs?
Nov 10, 2025Vision-language-action (VLA) models hold the promise to attain generalizable embodied control. To achieve this, a pervasive paradigm is to leverage the rich vision-semantic priors of large vision-language models (VLMs). However, the fundamental question persists: How do VLAs effectively inherit the prior knowledge from VLMs? To address this critical question, we introduce a diagnostic benchmark, GrinningFace, an emoji tabletop manipulation task where the robot arm is asked to place objects onto printed emojis corresponding to language instructions. This task design is particularly revealing -- knowledge associated with emojis is ubiquitous in Internet-scale datasets used for VLM pre-training, yet emojis themselves are largely absent from standard robotics datasets. Consequently, they provide a clean proxy: successful task completion indicates effective transfer of VLM priors to embodied control. We implement this diagnostic task in both simulated environment and a real robot, and compare various promising techniques for knowledge transfer. Specifically, we investigate the effects of parameter-efficient fine-tuning, VLM freezing, co-training, predicting discretized actions, and predicting latent actions. Through systematic evaluation, our work not only demonstrates the critical importance of preserving VLM priors for the generalization of VLA but also establishes guidelines for future research in developing truly generalizable embodied AI systems.
Co-Evolving Latent Action World Models
Oct 30, 2025Adapting pre-trained video generation models into controllable world models via latent actions is a promising step towards creating generalist world models. The dominant paradigm adopts a two-stage approach that trains latent action model (LAM) and the world model separately, resulting in redundant training and limiting their potential for co-adaptation. A conceptually simple and appealing idea is to directly replace the forward dynamic model in LAM with a powerful world model and training them jointly, but it is non-trivial and prone to representational collapse. In this work, we propose CoLA-World, which for the first time successfully realizes this synergistic paradigm, resolving the core challenge in joint learning through a critical warm-up phase that effectively aligns the representations of the from-scratch LAM with the pre-trained world model. This unlocks a co-evolution cycle: the world model acts as a knowledgeable tutor, providing gradients to shape a high-quality LAM, while the LAM offers a more precise and adaptable control interface to the world model. Empirically, CoLA-World matches or outperforms prior two-stage methods in both video simulation quality and downstream visual planning, establishing a robust and efficient new paradigm for the field.
villa-X: Enhancing Latent Action Modeling in Vision-Language-Action Models
Jul 31, 2025Visual-Language-Action (VLA) models have emerged as a popular paradigm for learning robot manipulation policies that can follow language instructions and generalize to novel scenarios. Recent work has begun to explore the incorporation of latent actions, an abstract representation of visual change between two frames, into VLA pre-training. In this paper, we introduce villa-X, a novel Visual-Language-Latent-Action (ViLLA) framework that advances latent action modeling for learning generalizable robot manipulation policies. Our approach improves both how latent actions are learned and how they are incorporated into VLA pre-training. Together, these contributions enable villa-X to achieve superior performance across simulated environments including SIMPLER and LIBERO, as well as on two real-world robot setups including gripper and dexterous hand manipulation. We believe the ViLLA paradigm holds significant promise, and that our villa-X provides a strong foundation for future research.
TurboReg: TurboClique for Robust and Efficient Point Cloud Registration
Jul 02, 2025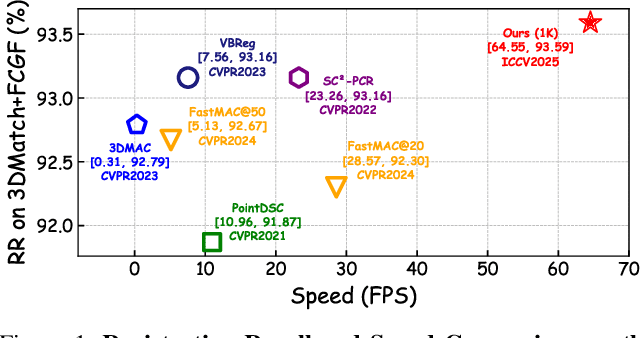
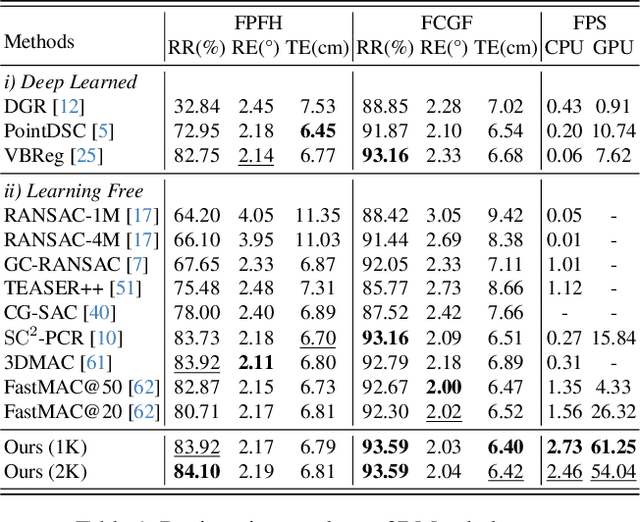


Robust estimation is essential in correspondence-based Point Cloud Registration (PCR). Existing methods using maximal clique search in compatibility graphs achieve high recall but suffer from exponential time complexity, limiting their use in time-sensitive applications. To address this challenge, we propose a fast and robust estimator, TurboReg, built upon a novel lightweight clique, TurboClique, and a highly parallelizable Pivot-Guided Search (PGS) algorithm. First, we define the TurboClique as a 3-clique within a highly-constrained compatibility graph. The lightweight nature of the 3-clique allows for efficient parallel searching, and the highly-constrained compatibility graph ensures robust spatial consistency for stable transformation estimation. Next, PGS selects matching pairs with high SC$^2$ scores as pivots, effectively guiding the search toward TurboCliques with higher inlier ratios. Moreover, the PGS algorithm has linear time complexity and is significantly more efficient than the maximal clique search with exponential time complexity. Extensive experiments show that TurboReg achieves state-of-the-art performance across multiple real-world datasets, with substantial speed improvements. For example, on the 3DMatch+FCGF dataset, TurboReg (1K) operates $208.22\times$ faster than 3DMAC while also achieving higher recall. Our code is accessible at \href{https://github.com/Laka-3DV/TurboReg}{\texttt{TurboReg}}.
Software Development Life Cycle Perspective: A Survey of Benchmarks for CodeLLMs and Agents
May 08, 2025Code large language models (CodeLLMs) and agents have shown great promise in tackling complex software engineering tasks.Compared to traditional software engineering methods, CodeLLMs and agents offer stronger abilities, and can flexibly process inputs and outputs in both natural and code. Benchmarking plays a crucial role in evaluating the capabilities of CodeLLMs and agents, guiding their development and deployment. However, despite their growing significance, there remains a lack of comprehensive reviews of benchmarks for CodeLLMs and agents. To bridge this gap, this paper provides a comprehensive review of existing benchmarks for CodeLLMs and agents, studying and analyzing 181 benchmarks from 461 relevant papers, covering the different phases of the software development life cycle (SDLC). Our findings reveal a notable imbalance in the coverage of current benchmarks, with approximately 60% focused on the software development phase in SDLC, while requirements engineering and software design phases receive minimal attention at only 5% and 3%, respectively. Additionally, Python emerges as the dominant programming language across the reviewed benchmarks. Finally, this paper highlights the challenges of current research and proposes future directions, aiming to narrow the gap between the theoretical capabilities of CodeLLMs and agents and their application in real-world scenarios.
$\text{M}^{\text{3}}$: A Modular World Model over Streams of Tokens
Feb 20, 2025Token-based world models emerged as a promising modular framework, modeling dynamics over token streams while optimizing tokenization separately. While successful in visual environments with discrete actions (e.g., Atari games), their broader applicability remains uncertain. In this paper, we introduce $\text{M}^{\text{3}}$, a $\textbf{m}$odular $\textbf{w}$orld $\textbf{m}$odel that extends this framework, enabling flexible combinations of observation and action modalities through independent modality-specific components. $\text{M}^{\text{3}}$ integrates several improvements from existing literature to enhance agent performance. Through extensive empirical evaluation across diverse benchmarks, $\text{M}^{\text{3}}$ achieves state-of-the-art sample efficiency for planning-free world models. Notably, among these methods, it is the first to reach a human-level median score on Atari 100K, with superhuman performance on 13 games. Our code and model weights are publicly available at https://github.com/leor-c/M3.
How Far is Video Generation from World Model: A Physical Law Perspective
Nov 04, 2024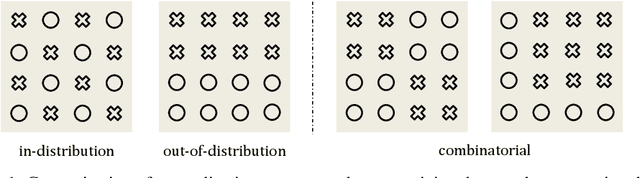

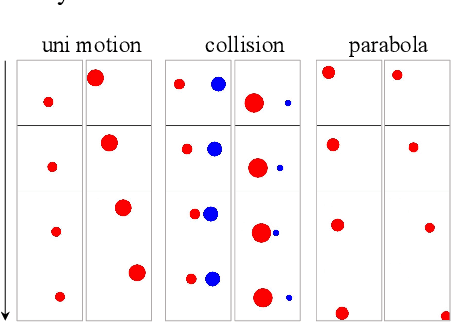
OpenAI's Sora highlights the potential of video generation for developing world models that adhere to fundamental physical laws. However, the ability of video generation models to discover such laws purely from visual data without human priors can be questioned. A world model learning the true law should give predictions robust to nuances and correctly extrapolate on unseen scenarios. In this work, we evaluate across three key scenarios: in-distribution, out-of-distribution, and combinatorial generalization. We developed a 2D simulation testbed for object movement and collisions to generate videos deterministically governed by one or more classical mechanics laws. This provides an unlimited supply of data for large-scale experimentation and enables quantitative evaluation of whether the generated videos adhere to physical laws. We trained diffusion-based video generation models to predict object movements based on initial frames. Our scaling experiments show perfect generalization within the distribution, measurable scaling behavior for combinatorial generalization, but failure in out-of-distribution scenarios. Further experiments reveal two key insights about the generalization mechanisms of these models: (1) the models fail to abstract general physical rules and instead exhibit "case-based" generalization behavior, i.e., mimicking the closest training example; (2) when generalizing to new cases, models are observed to prioritize different factors when referencing training data: color > size > velocity > shape. Our study suggests that scaling alone is insufficient for video generation models to uncover fundamental physical laws, despite its role in Sora's broader success. See our project page at https://phyworld.github.io