 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSolving Non-Rectangular Reward-Robust MDPs via Frequency Regularization
Sep 03, 2023In robust Markov decision processes (RMDPs), it is assumed that the reward and the transition dynamics lie in a given uncertainty set. By targeting maximal return under the most adversarial model from that set, RMDPs address performance sensitivity to misspecified environments. Yet, to preserve computational tractability, the uncertainty set is traditionally independently structured for each state. This so-called rectangularity condition is solely motivated by computational concerns. As a result, it lacks a practical incentive and may lead to overly conservative behavior. In this work, we study coupled reward RMDPs where the transition kernel is fixed, but the reward function lies within an $\alpha$-radius from a nominal one. We draw a direct connection between this type of non-rectangular reward-RMDPs and applying policy visitation frequency regularization. We introduce a policy-gradient method, and prove its convergence. Numerical experiments illustrate the learned policy's robustness and its less conservative behavior when compared to rectangular uncertainty.
Robust Reinforcement Learning via Adversarial Kernel Approximation
Jun 09, 2023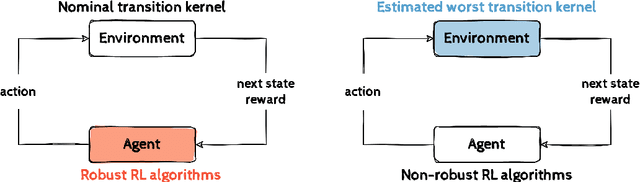
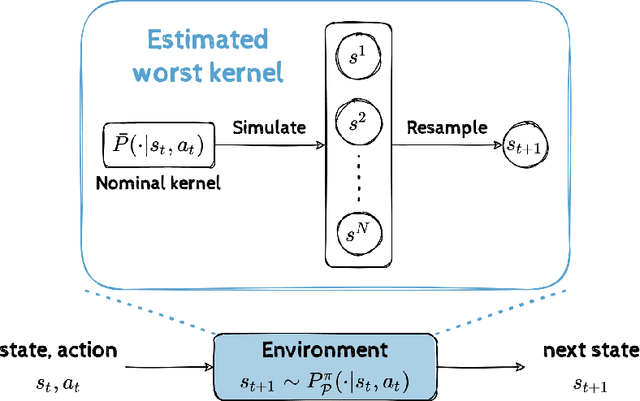
Robust Markov Decision Processes (RMDPs) provide a framework for sequential decision-making that is robust to perturbations on the transition kernel. However, robust reinforcement learning (RL) approaches in RMDPs do not scale well to realistic online settings with high-dimensional domains. By characterizing the adversarial kernel in RMDPs, we propose a novel approach for online robust RL that approximates the adversarial kernel and uses a standard (non-robust) RL algorithm to learn a robust policy. Notably, our approach can be applied on top of any underlying RL algorithm, enabling easy scaling to high-dimensional domains. Experiments in classic control tasks, MinAtar and DeepMind Control Suite demonstrate the effectiveness and the applicability of our method.
Policy Gradient for s-Rectangular Robust Markov Decision Processes
Jan 31, 2023



We present a novel robust policy gradient method (RPG) for s-rectangular robust Markov Decision Processes (MDPs). We are the first to derive the adversarial kernel in a closed form and demonstrate that it is a one-rank perturbation of the nominal kernel. This allows us to derive an RPG that is similar to the one used in non-robust MDPs, except with a robust Q-value function and an additional correction term. Both robust Q-values and correction terms are efficiently computable, thus the time complexity of our method matches that of non-robust MDPs, which is significantly faster compared to existing black box methods.
An Efficient Solution to s-Rectangular Robust Markov Decision Processes
Jan 31, 2023
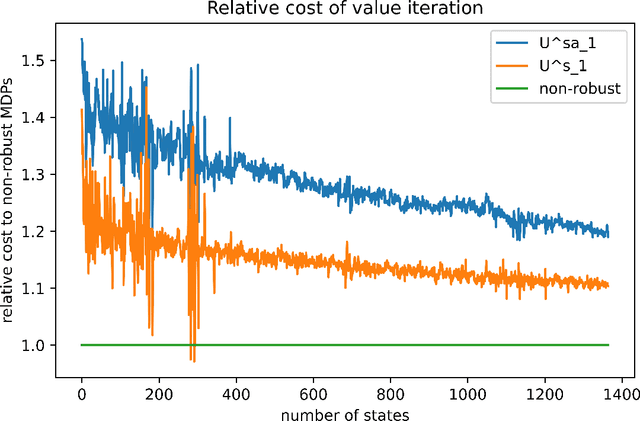


We present an efficient robust value iteration for \texttt{s}-rectangular robust Markov Decision Processes (MDPs) with a time complexity comparable to standard (non-robust) MDPs which is significantly faster than any existing method. We do so by deriving the optimal robust Bellman operator in concrete forms using our $L_p$ water filling lemma. We unveil the exact form of the optimal policies, which turn out to be novel threshold policies with the probability of playing an action proportional to its advantage.
Policy Gradient for Reinforcement Learning with General Utilities
Oct 03, 2022In Reinforcement Learning (RL), the goal of agents is to discover an optimal policy that maximizes the expected cumulative rewards. This objective may also be viewed as finding a policy that optimizes a linear function of its state-action occupancy measure, hereafter referred as Linear RL. However, many supervised and unsupervised RL problems are not covered in the Linear RL framework, such as apprenticeship learning, pure exploration and variational intrinsic control, where the objectives are non-linear functions of the occupancy measures. RL with non-linear utilities looks unwieldy, as methods like Bellman equation, value iteration, policy gradient, dynamic programming that had tremendous success in Linear RL, fail to trivially generalize. In this paper, we derive the policy gradient theorem for RL with general utilities. The policy gradient theorem proves to be a cornerstone in Linear RL due to its elegance and ease of implementability. Our policy gradient theorem for RL with general utilities shares the same elegance and ease of implementability. Based on the policy gradient theorem derived, we also present a simple sample-based algorithm. We believe our results will be of interest to the community and offer inspiration to future works in this generalized setting.
Efficient Policy Iteration for Robust Markov Decision Processes via Regularization
May 28, 2022

Robust Markov decision processes (MDPs) provide a general framework to model decision problems where the system dynamics are changing or only partially known. Recent work established the equivalence between \texttt{s} rectangular $L_p$ robust MDPs and regularized MDPs, and derived a regularized policy iteration scheme that enjoys the same level of efficiency as standard MDPs. However, there lacks a clear understanding of the policy improvement step. For example, we know the greedy policy can be stochastic but have little clue how each action affects this greedy policy. In this work, we focus on the policy improvement step and derive concrete forms for the greedy policy and the optimal robust Bellman operators. We find that the greedy policy is closely related to some combination of the top $k$ actions, which provides a novel characterization of its stochasticity. The exact nature of the combination depends on the shape of the uncertainty set. Furthermore, our results allow us to efficiently compute the policy improvement step by a simple binary search, without turning to an external optimization subroutine. Moreover, for $L_1, L_2$, and $L_\infty$ robust MDPs, we can even get rid of the binary search and evaluate the optimal robust Bellman operators exactly. Our work greatly extends existing results on solving \texttt{s}-rectangular $L_p$ robust MDPs via regularized policy iteration and can be readily adapted to sample-based model-free algorithms.