 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReward Redistribution for CVaR MDPs using a Bellman Operator on L-infinity
Feb 03, 2026Tail-end risk measures such as static conditional value-at-risk (CVaR) are used in safety-critical applications to prevent rare, yet catastrophic events. Unlike risk-neutral objectives, the static CVaR of the return depends on entire trajectories without admitting a recursive Bellman decomposition in the underlying Markov decision process. A classical resolution relies on state augmentation with a continuous variable. However, unless restricted to a specialized class of admissible value functions, this formulation induces sparse rewards and degenerate fixed points. In this work, we propose a novel formulation of the static CVaR objective based on augmentation. Our alternative approach leads to a Bellman operator with: (1) dense per-step rewards; (2) contracting properties on the full space of bounded value functions. Building on this theoretical foundation, we develop risk-averse value iteration and model-free Q-learning algorithms that rely on discretized augmented states. We further provide convergence guarantees and approximation error bounds due to discretization. Empirical results demonstrate that our algorithms successfully learn CVaR-sensitive policies and achieve effective performance-safety trade-offs.
State Entropy Regularization for Robust Reinforcement Learning
Jun 08, 2025



State entropy regularization has empirically shown better exploration and sample complexity in reinforcement learning (RL). However, its theoretical guarantees have not been studied. In this paper, we show that state entropy regularization improves robustness to structured and spatially correlated perturbations. These types of variation are common in transfer learning but often overlooked by standard robust RL methods, which typically focus on small, uncorrelated changes. We provide a comprehensive characterization of these robustness properties, including formal guarantees under reward and transition uncertainty, as well as settings where the method performs poorly. Much of our analysis contrasts state entropy with the widely used policy entropy regularization, highlighting their different benefits. Finally, from a practical standpoint, we illustrate that compared with policy entropy, the robustness advantages of state entropy are more sensitive to the number of rollouts used for policy evaluation.
Q-learning for Quantile MDPs: A Decomposition, Performance, and Convergence Analysis
Oct 31, 2024



In Markov decision processes (MDPs), quantile risk measures such as Value-at-Risk are a standard metric for modeling RL agents' preferences for certain outcomes. This paper proposes a new Q-learning algorithm for quantile optimization in MDPs with strong convergence and performance guarantees. The algorithm leverages a new, simple dynamic program (DP) decomposition for quantile MDPs. Compared with prior work, our DP decomposition requires neither known transition probabilities nor solving complex saddle point equations and serves as a suitable foundation for other model-free RL algorithms. Our numerical results in tabular domains show that our Q-learning algorithm converges to its DP variant and outperforms earlier algorithms.
Tree Search-Based Policy Optimization under Stochastic Execution Delay
Apr 08, 2024The standard formulation of Markov decision processes (MDPs) assumes that the agent's decisions are executed immediately. However, in numerous realistic applications such as robotics or healthcare, actions are performed with a delay whose value can even be stochastic. In this work, we introduce stochastic delayed execution MDPs, a new formalism addressing random delays without resorting to state augmentation. We show that given observed delay values, it is sufficient to perform a policy search in the class of Markov policies in order to reach optimal performance, thus extending the deterministic fixed delay case. Armed with this insight, we devise DEZ, a model-based algorithm that optimizes over the class of Markov policies. DEZ leverages Monte-Carlo tree search similar to its non-delayed variant EfficientZero to accurately infer future states from the action queue. Thus, it handles delayed execution while preserving the sample efficiency of EfficientZero. Through a series of experiments on the Atari suite, we demonstrate that although the previous baseline outperforms the naive method in scenarios with constant delay, it underperforms in the face of stochastic delays. In contrast, our approach significantly outperforms the baselines, for both constant and stochastic delays. The code is available at http://github.com/davidva1/Delayed-EZ .
Solving Non-Rectangular Reward-Robust MDPs via Frequency Regularization
Sep 03, 2023In robust Markov decision processes (RMDPs), it is assumed that the reward and the transition dynamics lie in a given uncertainty set. By targeting maximal return under the most adversarial model from that set, RMDPs address performance sensitivity to misspecified environments. Yet, to preserve computational tractability, the uncertainty set is traditionally independently structured for each state. This so-called rectangularity condition is solely motivated by computational concerns. As a result, it lacks a practical incentive and may lead to overly conservative behavior. In this work, we study coupled reward RMDPs where the transition kernel is fixed, but the reward function lies within an $\alpha$-radius from a nominal one. We draw a direct connection between this type of non-rectangular reward-RMDPs and applying policy visitation frequency regularization. We introduce a policy-gradient method, and prove its convergence. Numerical experiments illustrate the learned policy's robustness and its less conservative behavior when compared to rectangular uncertainty.
Twice Regularized Markov Decision Processes: The Equivalence between Robustness and Regularization
Mar 12, 2023
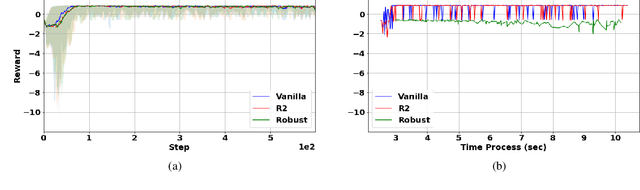
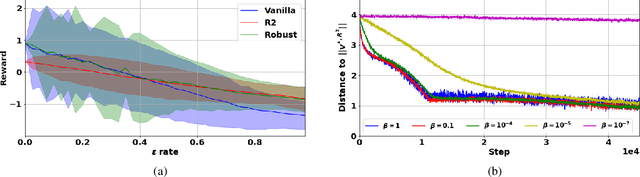
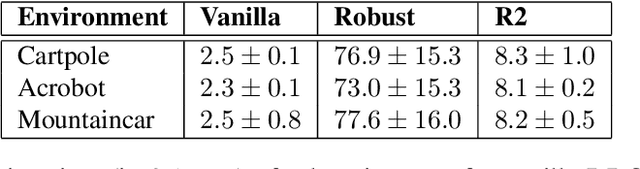
Robust Markov decision processes (MDPs) aim to handle changing or partially known system dynamics. To solve them, one typically resorts to robust optimization methods. However, this significantly increases computational complexity and limits scalability in both learning and planning. On the other hand, regularized MDPs show more stability in policy learning without impairing time complexity. Yet, they generally do not encompass uncertainty in the model dynamics. In this work, we aim to learn robust MDPs using regularization. We first show that regularized MDPs are a particular instance of robust MDPs with uncertain reward. We thus establish that policy iteration on reward-robust MDPs can have the same time complexity as on regularized MDPs. We further extend this relationship to MDPs with uncertain transitions: this leads to a regularization term with an additional dependence on the value function. We then generalize regularized MDPs to twice regularized MDPs ($\text{R}^2$ MDPs), i.e., MDPs with $\textit{both}$ value and policy regularization. The corresponding Bellman operators enable us to derive planning and learning schemes with convergence and generalization guarantees, thus reducing robustness to regularization. We numerically show this two-fold advantage on tabular and physical domains, highlighting the fact that $\text{R}^2$ preserves its efficacy in continuous environments.
Policy Gradient for s-Rectangular Robust Markov Decision Processes
Jan 31, 2023



We present a novel robust policy gradient method (RPG) for s-rectangular robust Markov Decision Processes (MDPs). We are the first to derive the adversarial kernel in a closed form and demonstrate that it is a one-rank perturbation of the nominal kernel. This allows us to derive an RPG that is similar to the one used in non-robust MDPs, except with a robust Q-value function and an additional correction term. Both robust Q-values and correction terms are efficiently computable, thus the time complexity of our method matches that of non-robust MDPs, which is significantly faster compared to existing black box methods.
Twice regularized MDPs and the equivalence between robustness and regularization
Oct 12, 2021
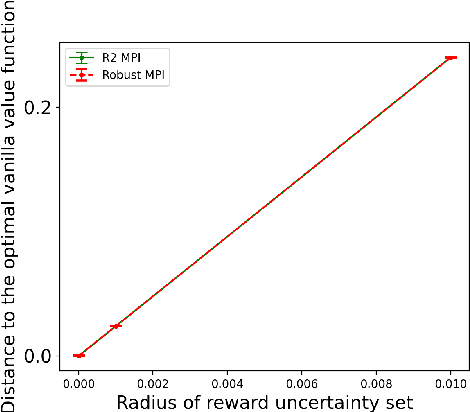
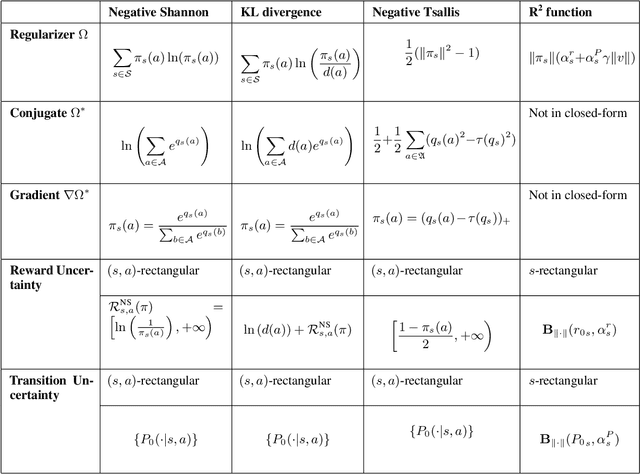

Robust Markov decision processes (MDPs) aim to handle changing or partially known system dynamics. To solve them, one typically resorts to robust optimization methods. However, this significantly increases computational complexity and limits scalability in both learning and planning. On the other hand, regularized MDPs show more stability in policy learning without impairing time complexity. Yet, they generally do not encompass uncertainty in the model dynamics. In this work, we aim to learn robust MDPs using regularization. We first show that regularized MDPs are a particular instance of robust MDPs with uncertain reward. We thus establish that policy iteration on reward-robust MDPs can have the same time complexity as on regularized MDPs. We further extend this relationship to MDPs with uncertain transitions: this leads to a regularization term with an additional dependence on the value function. We finally generalize regularized MDPs to twice regularized MDPs (R${}^2$ MDPs), i.e., MDPs with $\textit{both}$ value and policy regularization. The corresponding Bellman operators enable developing policy iteration schemes with convergence and robustness guarantees. It also reduces planning and learning in robust MDPs to regularized MDPs.
Acting in Delayed Environments with Non-Stationary Markov Policies
Jan 28, 2021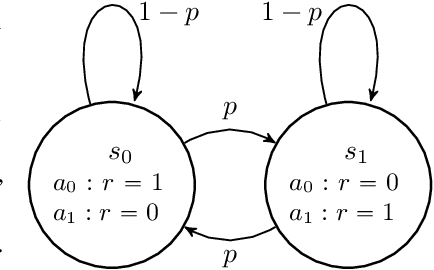

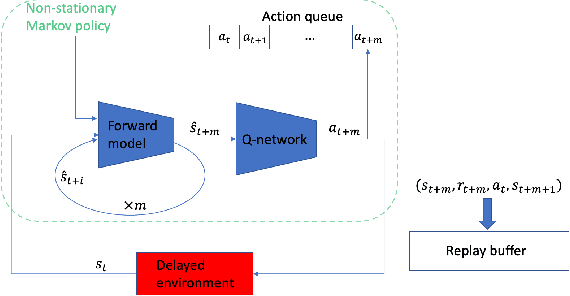
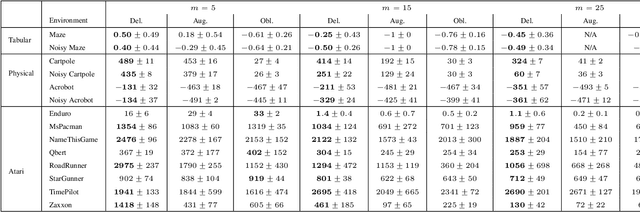
The standard Markov Decision Process (MDP) formulation hinges on the assumption that an action is executed immediately after it was chosen. However, assuming it is often unrealistic and can lead to catastrophic failures in applications such as robotic manipulation, cloud computing, and finance. We introduce a framework for learning and planning in MDPs where the decision-maker commits actions that are executed with a delay of $m$ steps. The brute-force state augmentation baseline where the state is concatenated to the last $m$ committed actions suffers from an exponential complexity in $m$, as we show for policy iteration. We then prove that with execution delay, Markov policies in the original state-space are sufficient for attaining maximal reward, but need to be non-stationary. As for stationary Markov policies, we show they are sub-optimal in general. Consequently, we devise a non-stationary Q-learning style model-based algorithm that solves delayed execution tasks without resorting to state-augmentation. Experiments on tabular, physical, and Atari domains reveal that it converges quickly to high performance even for substantial delays, while standard approaches that either ignore the delay or rely on state-augmentation struggle or fail due to divergence. The code is available at https://github.com/galdl/rl_delay_basic.git.
Distributional Robustness and Regularization in Reinforcement Learning
Mar 05, 2020Distributionally Robust Optimization (DRO) has enabled to prove the equivalence between robustness and regularization in classification and regression, thus providing an analytical reason why regularization generalizes well in statistical learning. Although DRO's extension to sequential decision-making overcomes $\textit{external uncertainty}$ through the robust Markov Decision Process (MDP) setting, the resulting formulation is hard to solve, especially on large domains. On the other hand, existing regularization methods in reinforcement learning only address $\textit{internal uncertainty}$ due to stochasticity. Our study aims to facilitate robust reinforcement learning by establishing a dual relation between robust MDPs and regularization. We introduce Wasserstein distributionally robust MDPs and prove that they hold out-of-sample performance guarantees. Then, we introduce a new regularizer for empirical value functions and show that it lower bounds the Wasserstein distributionally robust value function. We extend the result to linear value function approximation for large state spaces. Our approach provides an alternative formulation of robustness with guaranteed finite-sample performance. Moreover, it suggests using regularization as a practical tool for dealing with $\textit{external uncertainty}$ in reinforcement learning methods.