 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMuZero with Self-competition for Rate Control in VP9 Video Compression
Feb 14, 2022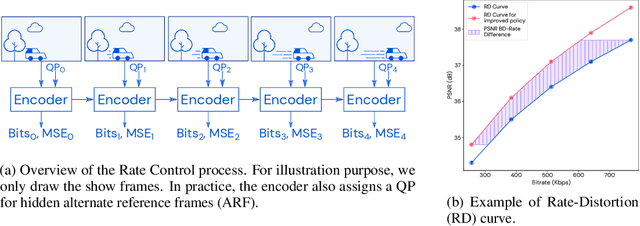

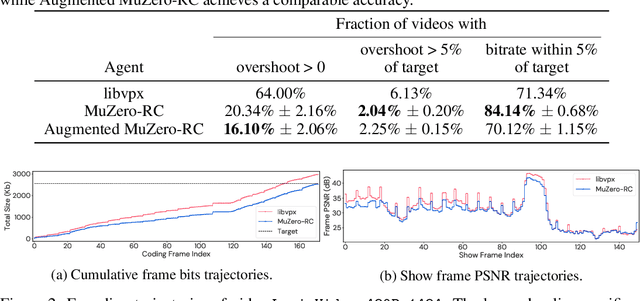
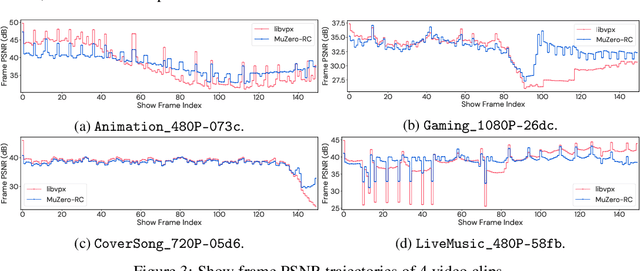
Video streaming usage has seen a significant rise as entertainment, education, and business increasingly rely on online video. Optimizing video compression has the potential to increase access and quality of content to users, and reduce energy use and costs overall. In this paper, we present an application of the MuZero algorithm to the challenge of video compression. Specifically, we target the problem of learning a rate control policy to select the quantization parameters (QP) in the encoding process of libvpx, an open source VP9 video compression library widely used by popular video-on-demand (VOD) services. We treat this as a sequential decision making problem to maximize the video quality with an episodic constraint imposed by the target bitrate. Notably, we introduce a novel self-competition based reward mechanism to solve constrained RL with variable constraint satisfaction difficulty, which is challenging for existing constrained RL methods. We demonstrate that the MuZero-based rate control achieves an average 6.28% reduction in size of the compressed videos for the same delivered video quality level (measured as PSNR BD-rate) compared to libvpx's two-pass VBR rate control policy, while having better constraint satisfaction behavior.
Data Augmentation Can Improve Robustness
Nov 09, 2021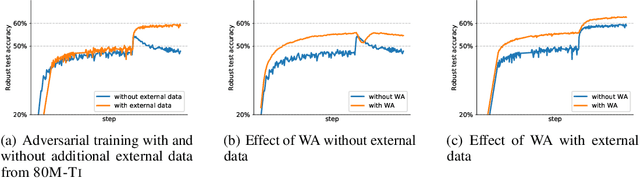
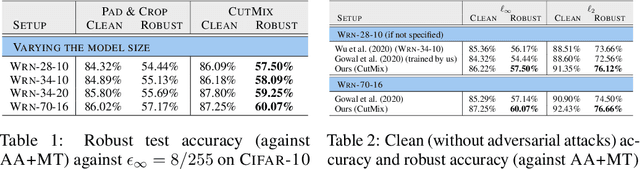
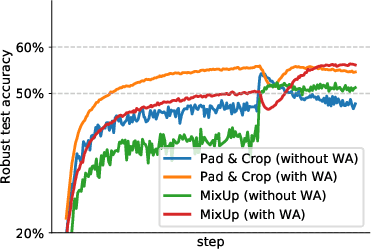
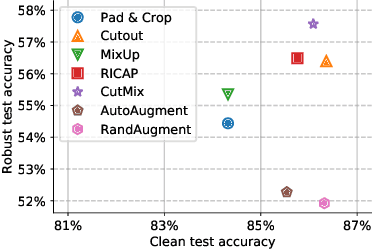
Adversarial training suffers from robust overfitting, a phenomenon where the robust test accuracy starts to decrease during training. In this paper, we focus on reducing robust overfitting by using common data augmentation schemes. We demonstrate that, contrary to previous findings, when combined with model weight averaging, data augmentation can significantly boost robust accuracy. Furthermore, we compare various augmentations techniques and observe that spatial composition techniques work the best for adversarial training. Finally, we evaluate our approach on CIFAR-10 against $\ell_\infty$ and $\ell_2$ norm-bounded perturbations of size $\epsilon = 8/255$ and $\epsilon = 128/255$, respectively. We show large absolute improvements of +2.93% and +2.16% in robust accuracy compared to previous state-of-the-art methods. In particular, against $\ell_\infty$ norm-bounded perturbations of size $\epsilon = 8/255$, our model reaches 60.07% robust accuracy without using any external data. We also achieve a significant performance boost with this approach while using other architectures and datasets such as CIFAR-100, SVHN and TinyImageNet.
Improving Robustness using Generated Data
Oct 18, 2021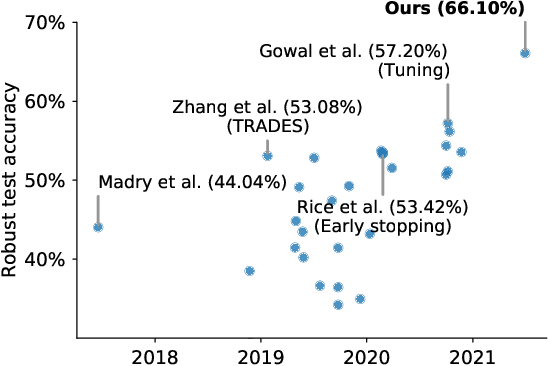
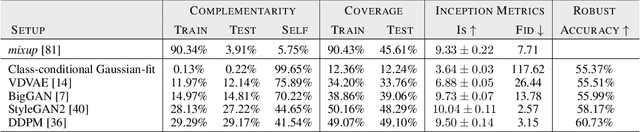
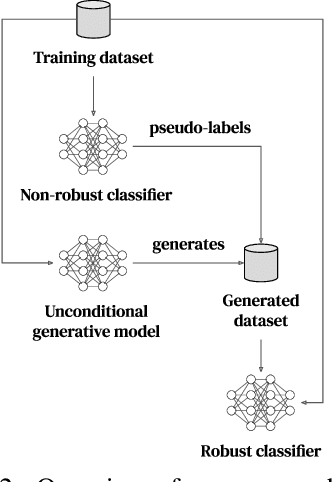
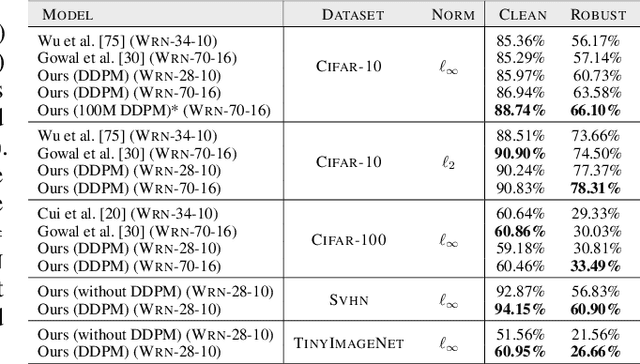
Recent work argues that robust training requires substantially larger datasets than those required for standard classification. On CIFAR-10 and CIFAR-100, this translates into a sizable robust-accuracy gap between models trained solely on data from the original training set and those trained with additional data extracted from the "80 Million Tiny Images" dataset (TI-80M). In this paper, we explore how generative models trained solely on the original training set can be leveraged to artificially increase the size of the original training set and improve adversarial robustness to $\ell_p$ norm-bounded perturbations. We identify the sufficient conditions under which incorporating additional generated data can improve robustness, and demonstrate that it is possible to significantly reduce the robust-accuracy gap to models trained with additional real data. Surprisingly, we even show that even the addition of non-realistic random data (generated by Gaussian sampling) can improve robustness. We evaluate our approach on CIFAR-10, CIFAR-100, SVHN and TinyImageNet against $\ell_\infty$ and $\ell_2$ norm-bounded perturbations of size $\epsilon = 8/255$ and $\epsilon = 128/255$, respectively. We show large absolute improvements in robust accuracy compared to previous state-of-the-art methods. Against $\ell_\infty$ norm-bounded perturbations of size $\epsilon = 8/255$, our models achieve 66.10% and 33.49% robust accuracy on CIFAR-10 and CIFAR-100, respectively (improving upon the state-of-the-art by +8.96% and +3.29%). Against $\ell_2$ norm-bounded perturbations of size $\epsilon = 128/255$, our model achieves 78.31% on CIFAR-10 (+3.81%). These results beat most prior works that use external data.
Defending Against Image Corruptions Through Adversarial Augmentations
Apr 20, 2021
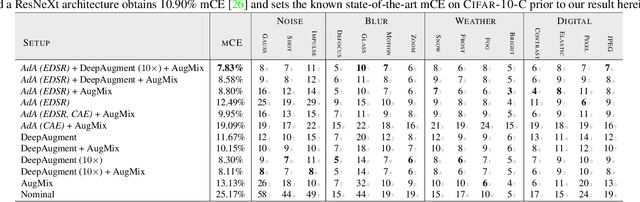
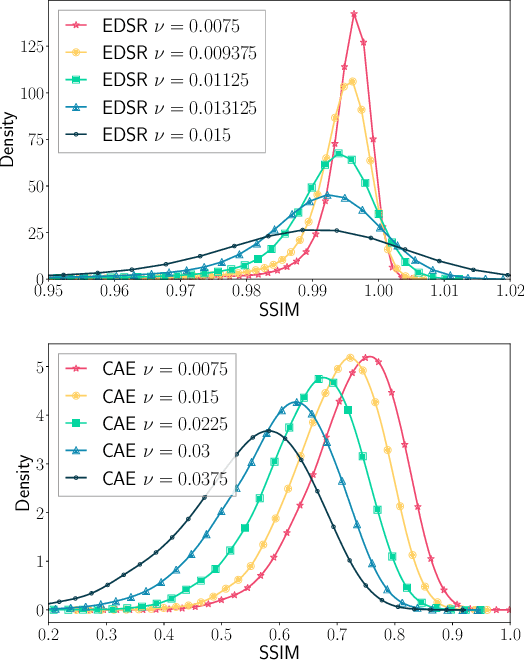
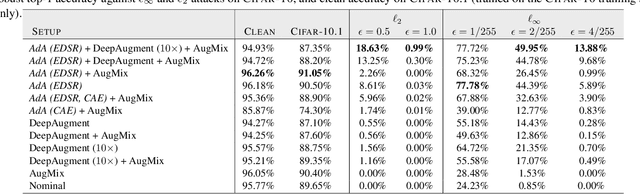
Modern neural networks excel at image classification, yet they remain vulnerable to common image corruptions such as blur, speckle noise or fog. Recent methods that focus on this problem, such as AugMix and DeepAugment, introduce defenses that operate in expectation over a distribution of image corruptions. In contrast, the literature on $\ell_p$-norm bounded perturbations focuses on defenses against worst-case corruptions. In this work, we reconcile both approaches by proposing AdversarialAugment, a technique which optimizes the parameters of image-to-image models to generate adversarially corrupted augmented images. We theoretically motivate our method and give sufficient conditions for the consistency of its idealized version as well as that of DeepAugment. Our classifiers improve upon the state-of-the-art on common image corruption benchmarks conducted in expectation on CIFAR-10-C and improve worst-case performance against $\ell_p$-norm bounded perturbations on both CIFAR-10 and ImageNet.
Fixing Data Augmentation to Improve Adversarial Robustness
Mar 02, 2021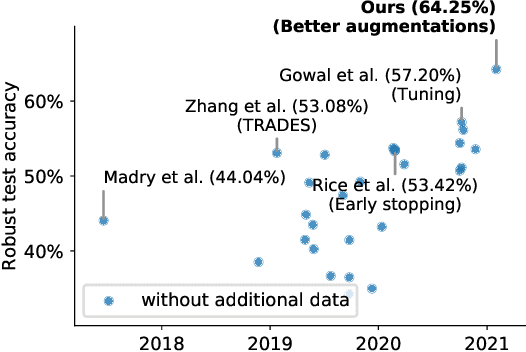
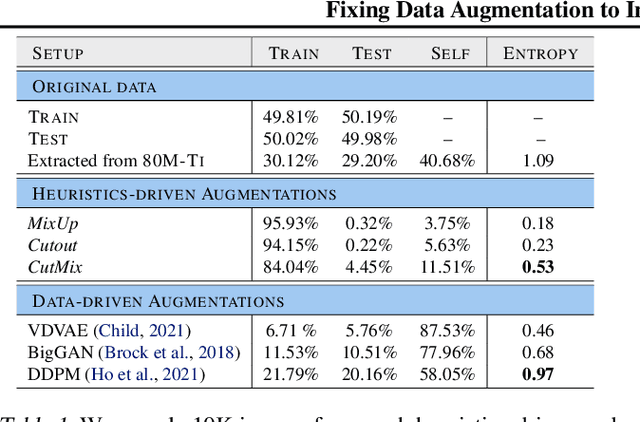
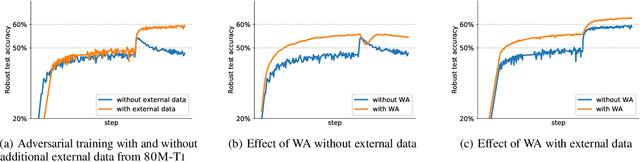
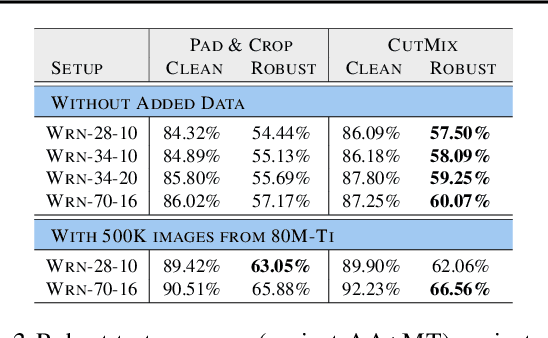
Adversarial training suffers from robust overfitting, a phenomenon where the robust test accuracy starts to decrease during training. In this paper, we focus on both heuristics-driven and data-driven augmentations as a means to reduce robust overfitting. First, we demonstrate that, contrary to previous findings, when combined with model weight averaging, data augmentation can significantly boost robust accuracy. Second, we explore how state-of-the-art generative models can be leveraged to artificially increase the size of the training set and further improve adversarial robustness. Finally, we evaluate our approach on CIFAR-10 against $\ell_\infty$ and $\ell_2$ norm-bounded perturbations of size $\epsilon = 8/255$ and $\epsilon = 128/255$, respectively. We show large absolute improvements of +7.06% and +5.88% in robust accuracy compared to previous state-of-the-art methods. In particular, against $\ell_\infty$ norm-bounded perturbations of size $\epsilon = 8/255$, our model reaches 64.20% robust accuracy without using any external data, beating most prior works that use external data.
Uncovering the Limits of Adversarial Training against Norm-Bounded Adversarial Examples
Oct 27, 2020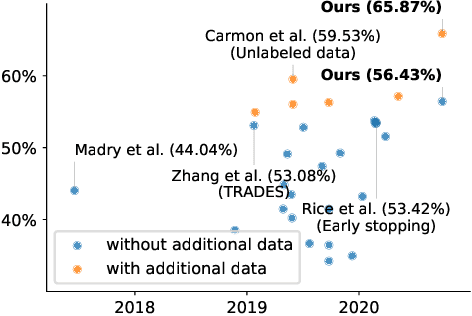

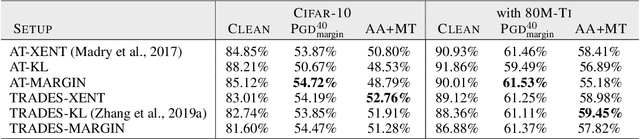
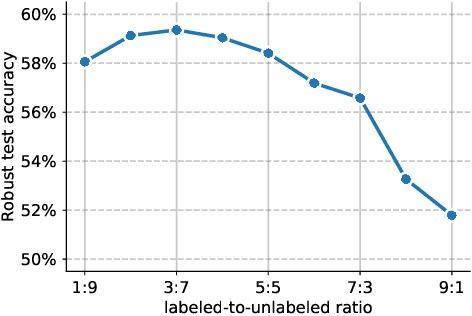
Adversarial training and its variants have become de facto standards for learning robust deep neural networks. In this paper, we explore the landscape around adversarial training in a bid to uncover its limits. We systematically study the effect of different training losses, model sizes, activation functions, the addition of unlabeled data (through pseudo-labeling) and other factors on adversarial robustness. We discover that it is possible to train robust models that go well beyond state-of-the-art results by combining larger models, Swish/SiLU activations and model weight averaging. We demonstrate large improvements on CIFAR-10 and CIFAR-100 against $\ell_\infty$ and $\ell_2$ norm-bounded perturbations of size $8/255$ and $128/255$, respectively. In the setting with additional unlabeled data, we obtain an accuracy under attack of 65.88% against $\ell_\infty$ perturbations of size $8/255$ on CIFAR-10 (+6.35% with respect to prior art). Without additional data, we obtain an accuracy under attack of 57.20% (+3.46%). To test the generality of our findings and without any additional modifications, we obtain an accuracy under attack of 80.53% (+7.62%) against $\ell_2$ perturbations of size $128/255$ on CIFAR-10, and of 36.88% (+8.46%) against $\ell_\infty$ perturbations of size $8/255$ on CIFAR-100.
Robust Constrained Reinforcement Learning for Continuous Control with Model Misspecification
Oct 20, 2020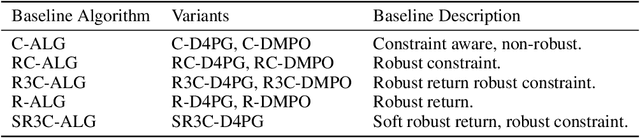
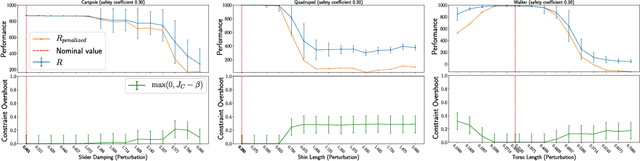
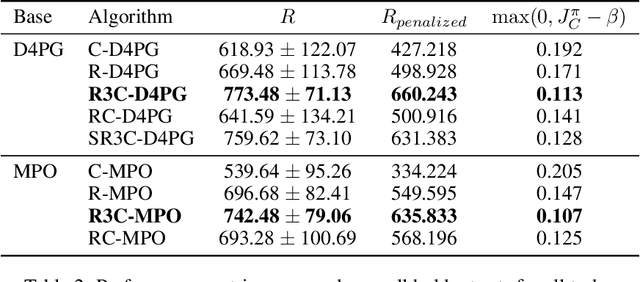
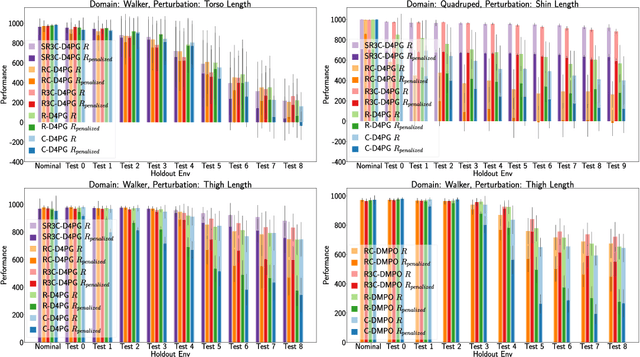
Many real-world physical control systems are required to satisfy constraints upon deployment. Furthermore, real-world systems are often subject to effects such as non-stationarity, wear-and-tear, uncalibrated sensors and so on. Such effects effectively perturb the system dynamics and can cause a policy trained successfully in one domain to perform poorly when deployed to a perturbed version of the same domain. This can affect a policy's ability to maximize future rewards as well as the extent to which it satisfies constraints. We refer to this as constrained model misspecification. We present an algorithm with theoretical guarantees that mitigates this form of misspecification, and showcase its performance in multiple Mujoco tasks from the Real World Reinforcement Learning (RWRL) suite.
Balancing Constraints and Rewards with Meta-Gradient D4PG
Oct 13, 2020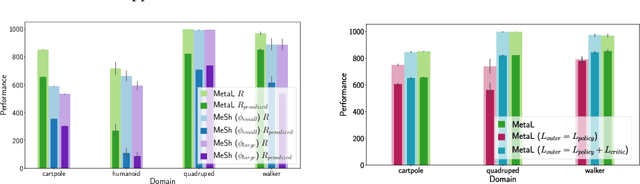
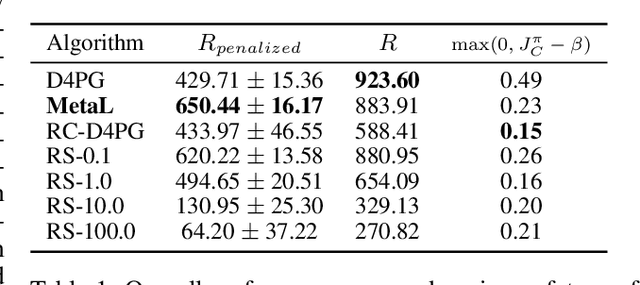

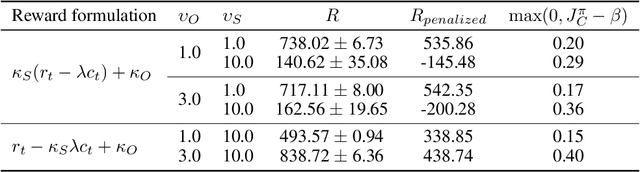
Deploying Reinforcement Learning (RL) agents to solve real-world applications often requires satisfying complex system constraints. Often the constraint thresholds are incorrectly set due to the complex nature of a system or the inability to verify the thresholds offline (e.g, no simulator or reasonable offline evaluation procedure exists). This results in solutions where a task cannot be solved without violating the constraints. However, in many real-world cases, constraint violations are undesirable yet they are not catastrophic, motivating the need for soft-constrained RL approaches. We present two soft-constrained RL approaches that utilize meta-gradients to find a good trade-off between expected return and minimizing constraint violations. We demonstrate the effectiveness of these approaches by showing that they consistently outperform the baselines across four different Mujoco domains.
Non-Stationary Bandits with Intermediate Observations
Jun 03, 2020
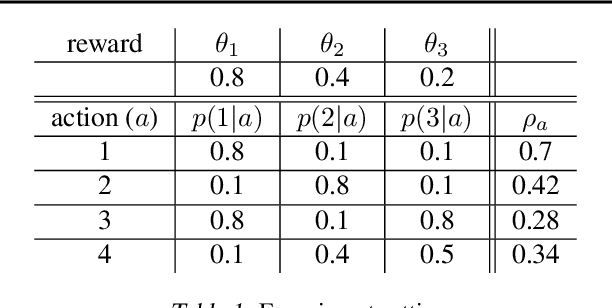
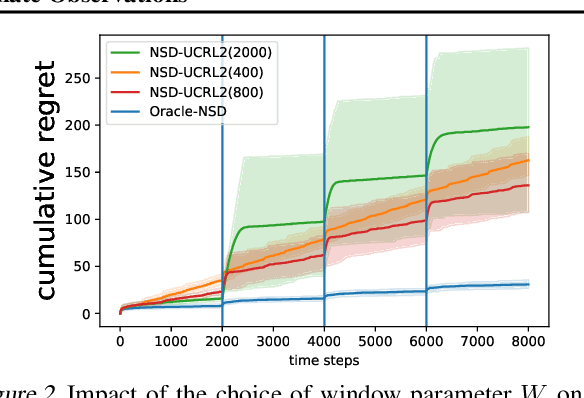
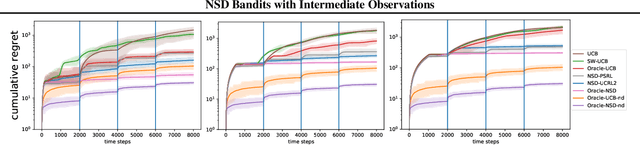
Online recommender systems often face long delays in receiving feedback, especially when optimizing for some long-term metrics. While mitigating the effects of delays in learning is well-understood in stationary environments, the problem becomes much more challenging when the environment changes. In fact, if the timescale of the change is comparable to the delay, it is impossible to learn about the environment, since the available observations are already obsolete. However, the arising issues can be addressed if intermediate signals are available without delay, such that given those signals, the long-term behavior of the system is stationary. To model this situation, we introduce the problem of stochastic, non-stationary, delayed bandits with intermediate observations. We develop a computationally efficient algorithm based on UCRL, and prove sublinear regret guarantees for its performance. Experimental results demonstrate that our method is able to learn in non-stationary delayed environments where existing methods fail.
Achieving Robustness in the Wild via Adversarial Mixing with Disentangled Representations
Dec 06, 2019



Recent research has made the surprising finding that state-of-the-art deep learning models sometimes fail to generalize to small variations of the input. Adversarial training has been shown to be an effective approach to overcome this problem. However, its application has been limited to enforcing invariance to analytically defined transformations like $\ell_p$-norm bounded perturbations. Such perturbations do not necessarily cover plausible real-world variations that preserve the semantics of the input (such as a change in lighting conditions). In this paper, we propose a novel approach to express and formalize robustness to these kinds of real-world transformations of the input. The two key ideas underlying our formulation are (1) leveraging disentangled representations of the input to define different factors of variations, and (2) generating new input images by adversarially composing the representations of different images. We use a StyleGAN model to demonstrate the efficacy of this framework. Specifically, we leverage the disentangled latent representations computed by a StyleGAN model to generate perturbations of an image that are similar to real-world variations (like adding make-up, or changing the skin-tone of a person) and train models to be invariant to these perturbations. Extensive experiments show that our method improves generalization and reduces the effect of spurious correlations.