 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Watermark in the Latent Space of Generative Models
Jan 22, 2026Existing approaches for watermarking AI-generated images often rely on post-hoc methods applied in pixel space, introducing computational overhead and potential visual artifacts. In this work, we explore latent space watermarking and introduce DistSeal, a unified approach for latent watermarking that works across both diffusion and autoregressive models. Our approach works by training post-hoc watermarking models in the latent space of generative models. We demonstrate that these latent watermarkers can be effectively distilled either into the generative model itself or into the latent decoder, enabling in-model watermarking. The resulting latent watermarks achieve competitive robustness while offering similar imperceptibility and up to 20x speedup compared to pixel-space baselines. Our experiments further reveal that distilling latent watermarkers outperforms distilling pixel-space ones, providing a solution that is both more efficient and more robust.
Pixel Seal: Adversarial-only training for invisible image and video watermarking
Dec 18, 2025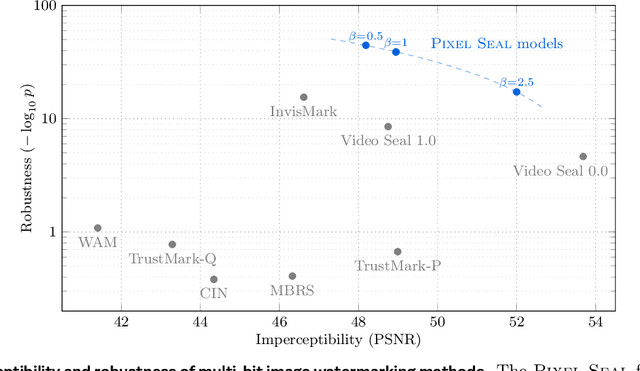
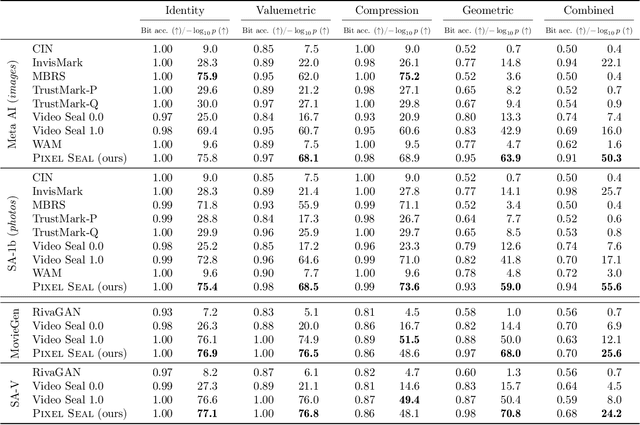
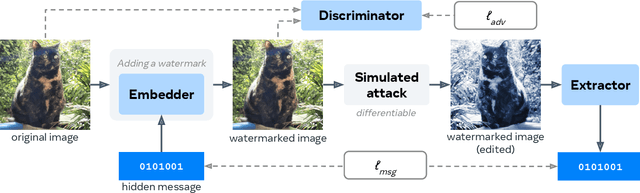
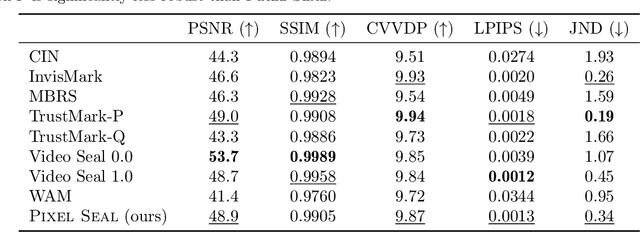
Invisible watermarking is essential for tracing the provenance of digital content. However, training state-of-the-art models remains notoriously difficult, with current approaches often struggling to balance robustness against true imperceptibility. This work introduces Pixel Seal, which sets a new state-of-the-art for image and video watermarking. We first identify three fundamental issues of existing methods: (i) the reliance on proxy perceptual losses such as MSE and LPIPS that fail to mimic human perception and result in visible watermark artifacts; (ii) the optimization instability caused by conflicting objectives, which necessitates exhaustive hyperparameter tuning; and (iii) reduced robustness and imperceptibility of watermarks when scaling models to high-resolution images and videos. To overcome these issues, we first propose an adversarial-only training paradigm that eliminates unreliable pixel-wise imperceptibility losses. Second, we introduce a three-stage training schedule that stabilizes convergence by decoupling robustness and imperceptibility. Third, we address the resolution gap via high-resolution adaptation, employing JND-based attenuation and training-time inference simulation to eliminate upscaling artifacts. We thoroughly evaluate the robustness and imperceptibility of Pixel Seal on different image types and across a wide range of transformations, and show clear improvements over the state-of-the-art. We finally demonstrate that the model efficiently adapts to video via temporal watermark pooling, positioning Pixel Seal as a practical and scalable solution for reliable provenance in real-world image and video settings.
How Good is Post-Hoc Watermarking With Language Model Rephrasing?
Dec 18, 2025Generation-time text watermarking embeds statistical signals into text for traceability of AI-generated content. We explore *post-hoc watermarking* where an LLM rewrites existing text while applying generation-time watermarking, to protect copyrighted documents, or detect their use in training or RAG via watermark radioactivity. Unlike generation-time approaches, which is constrained by how LLMs are served, this setting offers additional degrees of freedom for both generation and detection. We investigate how allocating compute (through larger rephrasing models, beam search, multi-candidate generation, or entropy filtering at detection) affects the quality-detectability trade-off. Our strategies achieve strong detectability and semantic fidelity on open-ended text such as books. Among our findings, the simple Gumbel-max scheme surprisingly outperforms more recent alternatives under nucleus sampling, and most methods benefit significantly from beam search. However, most approaches struggle when watermarking verifiable text such as code, where we counterintuitively find that smaller models outperform larger ones. This study reveals both the potential and limitations of post-hoc watermarking, laying groundwork for practical applications and future research.
Transferable Black-Box One-Shot Forging of Watermarks via Image Preference Models
Oct 23, 2025Recent years have seen a surge in interest in digital content watermarking techniques, driven by the proliferation of generative models and increased legal pressure. With an ever-growing percentage of AI-generated content available online, watermarking plays an increasingly important role in ensuring content authenticity and attribution at scale. There have been many works assessing the robustness of watermarking to removal attacks, yet, watermark forging, the scenario when a watermark is stolen from genuine content and applied to malicious content, remains underexplored. In this work, we investigate watermark forging in the context of widely used post-hoc image watermarking. Our contributions are as follows. First, we introduce a preference model to assess whether an image is watermarked. The model is trained using a ranking loss on purely procedurally generated images without any need for real watermarks. Second, we demonstrate the model's capability to remove and forge watermarks by optimizing the input image through backpropagation. This technique requires only a single watermarked image and works without knowledge of the watermarking model, making our attack much simpler and more practical than attacks introduced in related work. Third, we evaluate our proposed method on a variety of post-hoc image watermarking models, demonstrating that our approach can effectively forge watermarks, questioning the security of current watermarking approaches. Our code and further resources are publicly available.
Geometric Image Synchronization with Deep Watermarking
Sep 18, 2025Synchronization is the task of estimating and inverting geometric transformations (e.g., crop, rotation) applied to an image. This work introduces SyncSeal, a bespoke watermarking method for robust image synchronization, which can be applied on top of existing watermarking methods to enhance their robustness against geometric transformations. It relies on an embedder network that imperceptibly alters images and an extractor network that predicts the geometric transformation to which the image was subjected. Both networks are end-to-end trained to minimize the error between the predicted and ground-truth parameters of the transformation, combined with a discriminator to maintain high perceptual quality. We experimentally validate our method on a wide variety of geometric and valuemetric transformations, demonstrating its effectiveness in accurately synchronizing images. We further show that our synchronization can effectively upgrade existing watermarking methods to withstand geometric transformations to which they were previously vulnerable.
Imagen 3
Aug 13, 2024We introduce Imagen 3, a latent diffusion model that generates high quality images from text prompts. We describe our quality and responsibility evaluations. Imagen 3 is preferred over other state-of-the-art (SOTA) models at the time of evaluation. In addition, we discuss issues around safety and representation, as well as methods we used to minimize the potential harm of our models.
Generative models improve fairness of medical classifiers under distribution shifts
Apr 18, 2023A ubiquitous challenge in machine learning is the problem of domain generalisation. This can exacerbate bias against groups or labels that are underrepresented in the datasets used for model development. Model bias can lead to unintended harms, especially in safety-critical applications like healthcare. Furthermore, the challenge is compounded by the difficulty of obtaining labelled data due to high cost or lack of readily available domain expertise. In our work, we show that learning realistic augmentations automatically from data is possible in a label-efficient manner using generative models. In particular, we leverage the higher abundance of unlabelled data to capture the underlying data distribution of different conditions and subgroups for an imaging modality. By conditioning generative models on appropriate labels, we can steer the distribution of synthetic examples according to specific requirements. We demonstrate that these learned augmentations can surpass heuristic ones by making models more robust and statistically fair in- and out-of-distribution. To evaluate the generality of our approach, we study 3 distinct medical imaging contexts of varying difficulty: (i) histopathology images from a publicly available generalisation benchmark, (ii) chest X-rays from publicly available clinical datasets, and (iii) dermatology images characterised by complex shifts and imaging conditions. Complementing real training samples with synthetic ones improves the robustness of models in all three medical tasks and increases fairness by improving the accuracy of diagnosis within underrepresented groups. This approach leads to stark improvements OOD across modalities: 7.7% prediction accuracy improvement in histopathology, 5.2% in chest radiology with 44.6% lower fairness gap and a striking 63.5% improvement in high-risk sensitivity for dermatology with a 7.5x reduction in fairness gap.
Seasoning Model Soups for Robustness to Adversarial and Natural Distribution Shifts
Feb 20, 2023



Adversarial training is widely used to make classifiers robust to a specific threat or adversary, such as $\ell_p$-norm bounded perturbations of a given $p$-norm. However, existing methods for training classifiers robust to multiple threats require knowledge of all attacks during training and remain vulnerable to unseen distribution shifts. In this work, we describe how to obtain adversarially-robust model soups (i.e., linear combinations of parameters) that smoothly trade-off robustness to different $\ell_p$-norm bounded adversaries. We demonstrate that such soups allow us to control the type and level of robustness, and can achieve robustness to all threats without jointly training on all of them. In some cases, the resulting model soups are more robust to a given $\ell_p$-norm adversary than the constituent model specialized against that same adversary. Finally, we show that adversarially-robust model soups can be a viable tool to adapt to distribution shifts from a few examples.
NEVIS'22: A Stream of 100 Tasks Sampled from 30 Years of Computer Vision Research
Nov 15, 2022We introduce the Never Ending VIsual-classification Stream (NEVIS'22), a benchmark consisting of a stream of over 100 visual classification tasks, sorted chronologically and extracted from papers sampled uniformly from computer vision proceedings spanning the last three decades. The resulting stream reflects what the research community thought was meaningful at any point in time. Despite being limited to classification, the resulting stream has a rich diversity of tasks from OCR, to texture analysis, crowd counting, scene recognition, and so forth. The diversity is also reflected in the wide range of dataset sizes, spanning over four orders of magnitude. Overall, NEVIS'22 poses an unprecedented challenge for current sequential learning approaches due to the scale and diversity of tasks, yet with a low entry barrier as it is limited to a single modality and each task is a classical supervised learning problem. Moreover, we provide a reference implementation including strong baselines and a simple evaluation protocol to compare methods in terms of their trade-off between accuracy and compute. We hope that NEVIS'22 can be useful to researchers working on continual learning, meta-learning, AutoML and more generally sequential learning, and help these communities join forces towards more robust and efficient models that efficiently adapt to a never ending stream of data. Implementations have been made available at https://github.com/deepmind/dm_nevis.
Revisiting adapters with adversarial training
Oct 10, 2022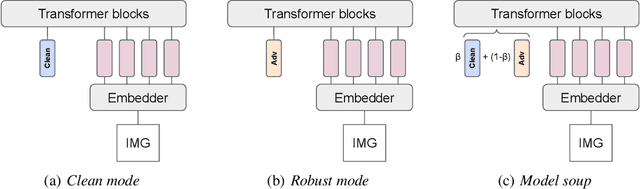
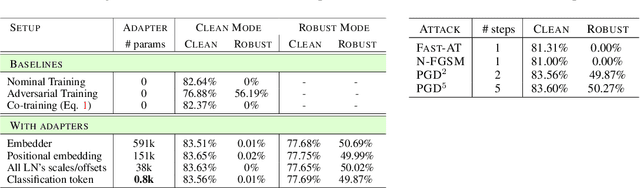
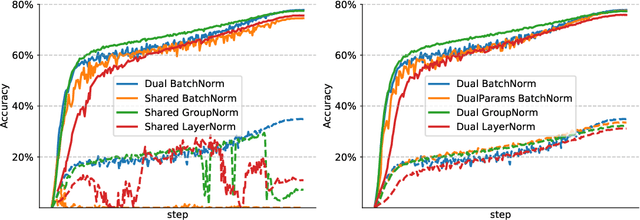
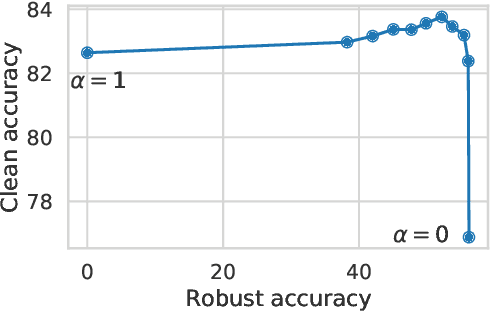
While adversarial training is generally used as a defense mechanism, recent works show that it can also act as a regularizer. By co-training a neural network on clean and adversarial inputs, it is possible to improve classification accuracy on the clean, non-adversarial inputs. We demonstrate that, contrary to previous findings, it is not necessary to separate batch statistics when co-training on clean and adversarial inputs, and that it is sufficient to use adapters with few domain-specific parameters for each type of input. We establish that using the classification token of a Vision Transformer (ViT) as an adapter is enough to match the classification performance of dual normalization layers, while using significantly less additional parameters. First, we improve upon the top-1 accuracy of a non-adversarially trained ViT-B16 model by +1.12% on ImageNet (reaching 83.76% top-1 accuracy). Second, and more importantly, we show that training with adapters enables model soups through linear combinations of the clean and adversarial tokens. These model soups, which we call adversarial model soups, allow us to trade-off between clean and robust accuracy without sacrificing efficiency. Finally, we show that we can easily adapt the resulting models in the face of distribution shifts. Our ViT-B16 obtains top-1 accuracies on ImageNet variants that are on average +4.00% better than those obtained with Masked Autoencoders.