 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA scalable and real-time neural decoder for topological quantum codes
Dec 08, 2025Fault-tolerant quantum computing will require error rates far below those achievable with physical qubits. Quantum error correction (QEC) bridges this gap, but depends on decoders being simultaneously fast, accurate, and scalable. This combination of requirements has not yet been met by a machine-learning decoder, nor by any decoder for promising resource-efficient codes such as the colour code. Here we introduce AlphaQubit 2, a neural-network decoder that achieves near-optimal logical error rates for both surface and colour codes at large scales under realistic noise. For the colour code, it is orders of magnitude faster than other high-accuracy decoders. For the surface code, we demonstrate real-time decoding faster than 1 microsecond per cycle up to distance 11 on current commercial accelerators with better accuracy than leading real-time decoders. These results support the practical application of a wider class of promising QEC codes, and establish a credible path towards high-accuracy, real-time neural decoding at the scales required for fault-tolerant quantum computation.
Improving cosmological reach of a gravitational wave observatory using Deep Loop Shaping
Sep 17, 2025Improved low-frequency sensitivity of gravitational wave observatories would unlock study of intermediate-mass black hole mergers, binary black hole eccentricity, and provide early warnings for multi-messenger observations of binary neutron star mergers. Today's mirror stabilization control injects harmful noise, constituting a major obstacle to sensitivity improvements. We eliminated this noise through Deep Loop Shaping, a reinforcement learning method using frequency domain rewards. We proved our methodology on the LIGO Livingston Observatory (LLO). Our controller reduced control noise in the 10--30Hz band by over 30x, and up to 100x in sub-bands surpassing the design goal motivated by the quantum limit. These results highlight the potential of Deep Loop Shaping to improve current and future GW observatories, and more broadly instrumentation and control systems.
AlphaEarth Foundations: An embedding field model for accurate and efficient global mapping from sparse label data
Jul 29, 2025Unprecedented volumes of Earth observation data are continually collected around the world, but high-quality labels remain scarce given the effort required to make physical measurements and observations. This has led to considerable investment in bespoke modeling efforts translating sparse labels into maps. Here we introduce AlphaEarth Foundations, an embedding field model yielding a highly general, geospatial representation that assimilates spatial, temporal, and measurement contexts across multiple sources, enabling accurate and efficient production of maps and monitoring systems from local to global scales. The embeddings generated by AlphaEarth Foundations are the only to consistently outperform all previous featurization approaches tested on a diverse set of mapping evaluations without re-training. We will release a dataset of global, annual, analysis-ready embedding field layers from 2017 through 2024.
AlphaEvolve: A coding agent for scientific and algorithmic discovery
Jun 16, 2025In this white paper, we present AlphaEvolve, an evolutionary coding agent that substantially enhances capabilities of state-of-the-art LLMs on highly challenging tasks such as tackling open scientific problems or optimizing critical pieces of computational infrastructure. AlphaEvolve orchestrates an autonomous pipeline of LLMs, whose task is to improve an algorithm by making direct changes to the code. Using an evolutionary approach, continuously receiving feedback from one or more evaluators, AlphaEvolve iteratively improves the algorithm, potentially leading to new scientific and practical discoveries. We demonstrate the broad applicability of this approach by applying it to a number of important computational problems. When applied to optimizing critical components of large-scale computational stacks at Google, AlphaEvolve developed a more efficient scheduling algorithm for data centers, found a functionally equivalent simplification in the circuit design of hardware accelerators, and accelerated the training of the LLM underpinning AlphaEvolve itself. Furthermore, AlphaEvolve discovered novel, provably correct algorithms that surpass state-of-the-art solutions on a spectrum of problems in mathematics and computer science, significantly expanding the scope of prior automated discovery methods (Romera-Paredes et al., 2023). Notably, AlphaEvolve developed a search algorithm that found a procedure to multiply two $4 \times 4$ complex-valued matrices using $48$ scalar multiplications; offering the first improvement, after 56 years, over Strassen's algorithm in this setting. We believe AlphaEvolve and coding agents like it can have a significant impact in improving solutions of problems across many areas of science and computation.
SensorLM: Learning the Language of Wearable Sensors
Jun 10, 2025We present SensorLM, a family of sensor-language foundation models that enable wearable sensor data understanding with natural language. Despite its pervasive nature, aligning and interpreting sensor data with language remains challenging due to the lack of paired, richly annotated sensor-text descriptions in uncurated, real-world wearable data. We introduce a hierarchical caption generation pipeline designed to capture statistical, structural, and semantic information from sensor data. This approach enabled the curation of the largest sensor-language dataset to date, comprising over 59.7 million hours of data from more than 103,000 people. Furthermore, SensorLM extends prominent multimodal pretraining architectures (e.g., CLIP, CoCa) and recovers them as specific variants within a generic architecture. Extensive experiments on real-world tasks in human activity analysis and healthcare verify the superior performance of SensorLM over state-of-the-art in zero-shot recognition, few-shot learning, and cross-modal retrieval. SensorLM also demonstrates intriguing capabilities including scaling behaviors, label efficiency, sensor captioning, and zero-shot generalization to unseen tasks.
LSM-2: Learning from Incomplete Wearable Sensor Data
Jun 05, 2025



Foundation models, a cornerstone of recent advancements in machine learning, have predominantly thrived on complete and well-structured data. Wearable sensor data frequently suffers from significant missingness, posing a substantial challenge for self-supervised learning (SSL) models that typically assume complete data inputs. This paper introduces the second generation of Large Sensor Model (LSM-2) with Adaptive and Inherited Masking (AIM), a novel SSL approach that learns robust representations directly from incomplete data without requiring explicit imputation. AIM's core novelty lies in its use of learnable mask tokens to model both existing ("inherited") and artificially introduced missingness, enabling it to robustly handle fragmented real-world data during inference. Pre-trained on an extensive dataset of 40M hours of day-long multimodal sensor data, our LSM-2 with AIM achieves the best performance across a diverse range of tasks, including classification, regression and generative modeling. Furthermore, LSM-2 with AIM exhibits superior scaling performance, and critically, maintains high performance even under targeted missingness scenarios, reflecting clinically coherent patterns, such as the diagnostic value of nighttime biosignals for hypertension prediction. This makes AIM a more reliable choice for real-world wearable data applications.
Advancing Conversational Diagnostic AI with Multimodal Reasoning
May 06, 2025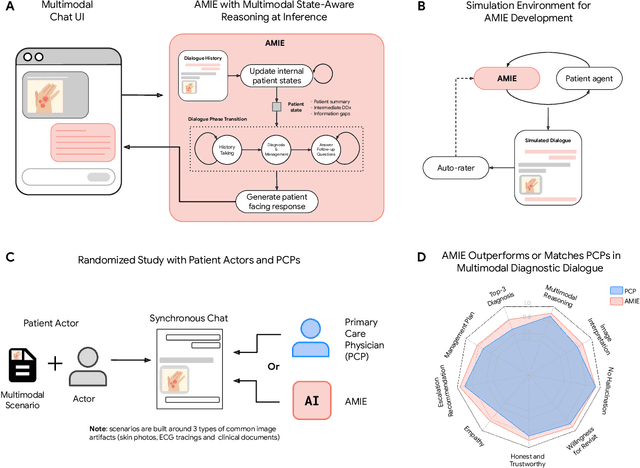
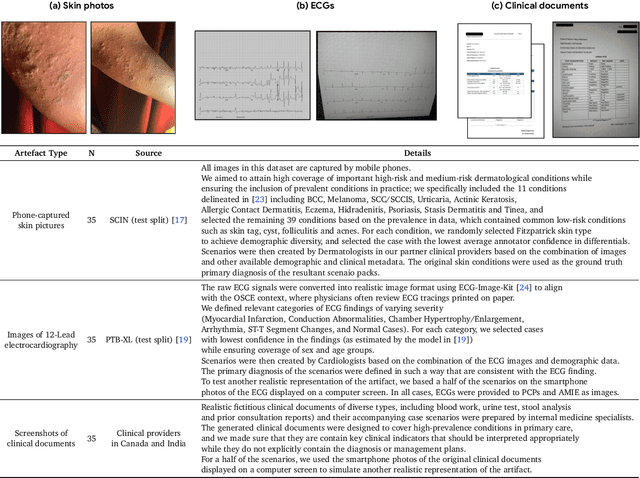
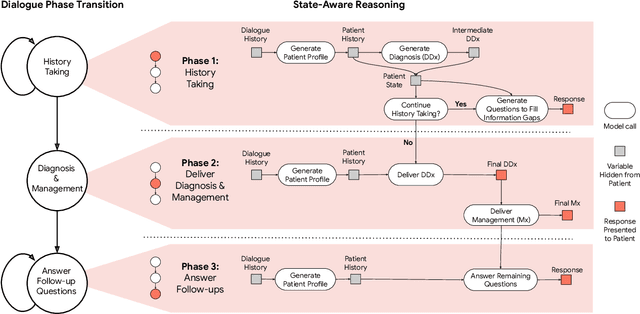
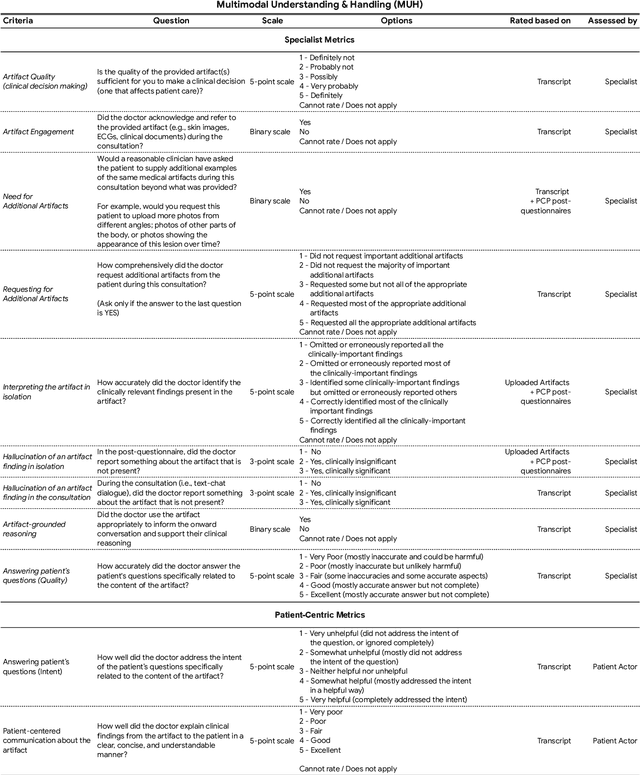
Large Language Models (LLMs) have demonstrated great potential for conducting diagnostic conversations but evaluation has been largely limited to language-only interactions, deviating from the real-world requirements of remote care delivery. Instant messaging platforms permit clinicians and patients to upload and discuss multimodal medical artifacts seamlessly in medical consultation, but the ability of LLMs to reason over such data while preserving other attributes of competent diagnostic conversation remains unknown. Here we advance the conversational diagnosis and management performance of the Articulate Medical Intelligence Explorer (AMIE) through a new capability to gather and interpret multimodal data, and reason about this precisely during consultations. Leveraging Gemini 2.0 Flash, our system implements a state-aware dialogue framework, where conversation flow is dynamically controlled by intermediate model outputs reflecting patient states and evolving diagnoses. Follow-up questions are strategically directed by uncertainty in such patient states, leading to a more structured multimodal history-taking process that emulates experienced clinicians. We compared AMIE to primary care physicians (PCPs) in a randomized, blinded, OSCE-style study of chat-based consultations with patient actors. We constructed 105 evaluation scenarios using artifacts like smartphone skin photos, ECGs, and PDFs of clinical documents across diverse conditions and demographics. Our rubric assessed multimodal capabilities and other clinically meaningful axes like history-taking, diagnostic accuracy, management reasoning, communication, and empathy. Specialist evaluation showed AMIE to be superior to PCPs on 7/9 multimodal and 29/32 non-multimodal axes (including diagnostic accuracy). The results show clear progress in multimodal conversational diagnostic AI, but real-world translation needs further research.
Towards an AI co-scientist
Feb 26, 2025Scientific discovery relies on scientists generating novel hypotheses that undergo rigorous experimental validation. To augment this process, we introduce an AI co-scientist, a multi-agent system built on Gemini 2.0. The AI co-scientist is intended to help uncover new, original knowledge and to formulate demonstrably novel research hypotheses and proposals, building upon prior evidence and aligned to scientist-provided research objectives and guidance. The system's design incorporates a generate, debate, and evolve approach to hypothesis generation, inspired by the scientific method and accelerated by scaling test-time compute. Key contributions include: (1) a multi-agent architecture with an asynchronous task execution framework for flexible compute scaling; (2) a tournament evolution process for self-improving hypotheses generation. Automated evaluations show continued benefits of test-time compute, improving hypothesis quality. While general purpose, we focus development and validation in three biomedical areas: drug repurposing, novel target discovery, and explaining mechanisms of bacterial evolution and anti-microbial resistance. For drug repurposing, the system proposes candidates with promising validation findings, including candidates for acute myeloid leukemia that show tumor inhibition in vitro at clinically applicable concentrations. For novel target discovery, the AI co-scientist proposed new epigenetic targets for liver fibrosis, validated by anti-fibrotic activity and liver cell regeneration in human hepatic organoids. Finally, the AI co-scientist recapitulated unpublished experimental results via a parallel in silico discovery of a novel gene transfer mechanism in bacterial evolution. These results, detailed in separate, co-timed reports, demonstrate the potential to augment biomedical and scientific discovery and usher an era of AI empowered scientists.
Scaling Wearable Foundation Models
Oct 17, 2024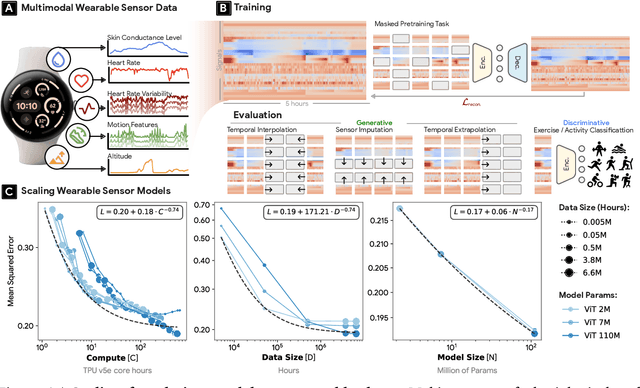
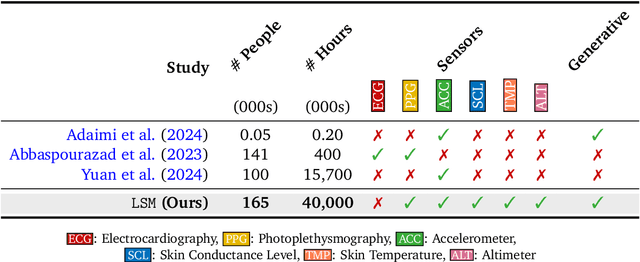


Wearable sensors have become ubiquitous thanks to a variety of health tracking features. The resulting continuous and longitudinal measurements from everyday life generate large volumes of data; however, making sense of these observations for scientific and actionable insights is non-trivial. Inspired by the empirical success of generative modeling, where large neural networks learn powerful representations from vast amounts of text, image, video, or audio data, we investigate the scaling properties of sensor foundation models across compute, data, and model size. Using a dataset of up to 40 million hours of in-situ heart rate, heart rate variability, electrodermal activity, accelerometer, skin temperature, and altimeter per-minute data from over 165,000 people, we create LSM, a multimodal foundation model built on the largest wearable-signals dataset with the most extensive range of sensor modalities to date. Our results establish the scaling laws of LSM for tasks such as imputation, interpolation and extrapolation, both across time and sensor modalities. Moreover, we highlight how LSM enables sample-efficient downstream learning for tasks like exercise and activity recognition.
Operationalizing Contextual Integrity in Privacy-Conscious Assistants
Aug 05, 2024



Advanced AI assistants combine frontier LLMs and tool access to autonomously perform complex tasks on behalf of users. While the helpfulness of such assistants can increase dramatically with access to user information including emails and documents, this raises privacy concerns about assistants sharing inappropriate information with third parties without user supervision. To steer information-sharing assistants to behave in accordance with privacy expectations, we propose to operationalize $\textit{contextual integrity}$ (CI), a framework that equates privacy with the appropriate flow of information in a given context. In particular, we design and evaluate a number of strategies to steer assistants' information-sharing actions to be CI compliant. Our evaluation is based on a novel form filling benchmark composed of synthetic data and human annotations, and it reveals that prompting frontier LLMs to perform CI-based reasoning yields strong results.