 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGriffin: Mixing Gated Linear Recurrences with Local Attention for Efficient Language Models
Feb 29, 2024Recurrent neural networks (RNNs) have fast inference and scale efficiently on long sequences, but they are difficult to train and hard to scale. We propose Hawk, an RNN with gated linear recurrences, and Griffin, a hybrid model that mixes gated linear recurrences with local attention. Hawk exceeds the reported performance of Mamba on downstream tasks, while Griffin matches the performance of Llama-2 despite being trained on over 6 times fewer tokens. We also show that Griffin can extrapolate on sequences significantly longer than those seen during training. Our models match the hardware efficiency of Transformers during training, and during inference they have lower latency and significantly higher throughput. We scale Griffin up to 14B parameters, and explain how to shard our models for efficient distributed training.
ConvNets Match Vision Transformers at Scale
Oct 25, 2023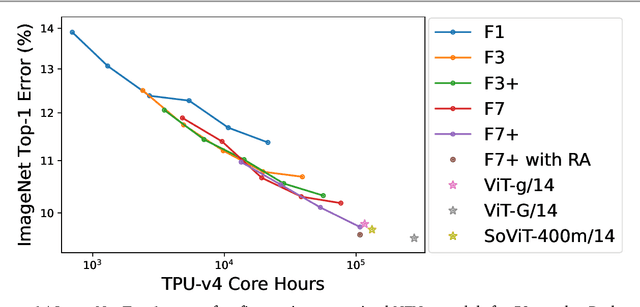
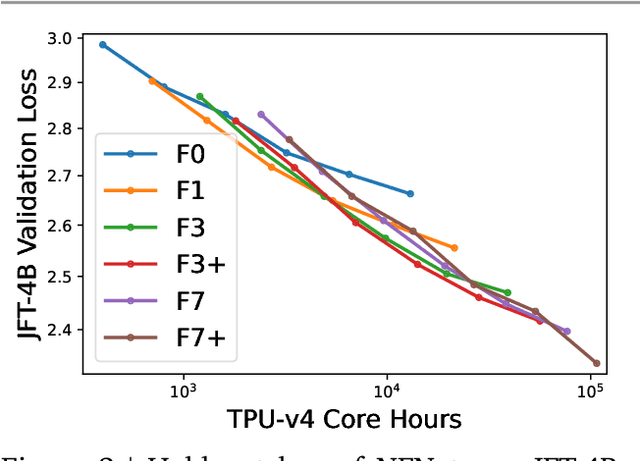
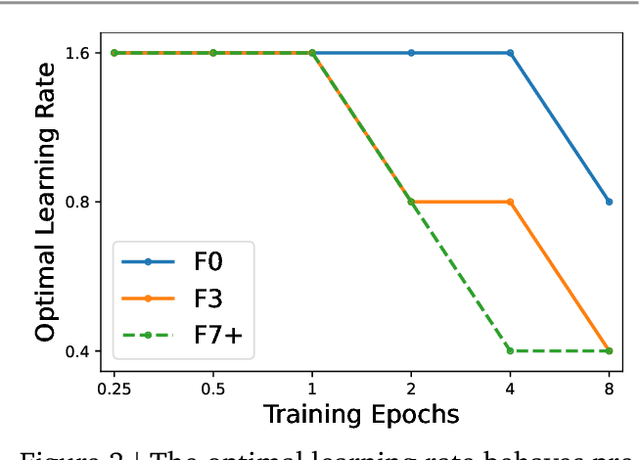
Many researchers believe that ConvNets perform well on small or moderately sized datasets, but are not competitive with Vision Transformers when given access to datasets on the web-scale. We challenge this belief by evaluating a performant ConvNet architecture pre-trained on JFT-4B, a large labelled dataset of images often used for training foundation models. We consider pre-training compute budgets between 0.4k and 110k TPU-v4 core compute hours, and train a series of networks of increasing depth and width from the NFNet model family. We observe a log-log scaling law between held out loss and compute budget. After fine-tuning on ImageNet, NFNets match the reported performance of Vision Transformers with comparable compute budgets. Our strongest fine-tuned model achieves a Top-1 accuracy of 90.4%.
Unlocking Accuracy and Fairness in Differentially Private Image Classification
Aug 21, 2023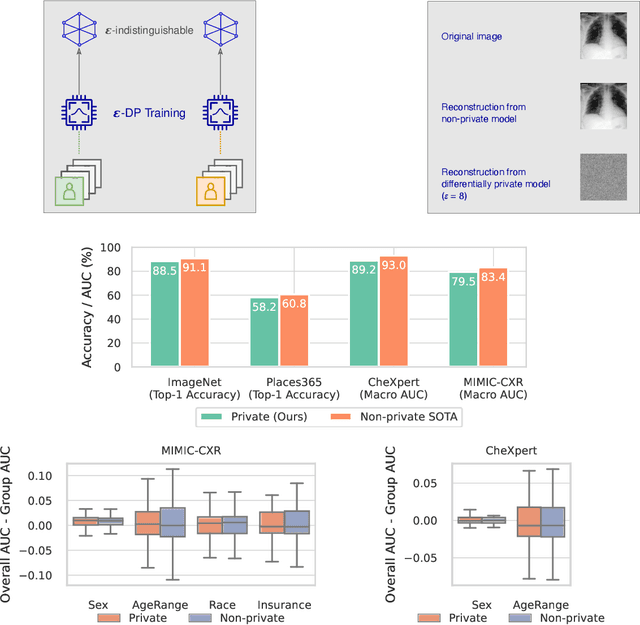
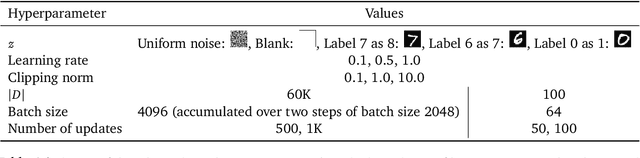
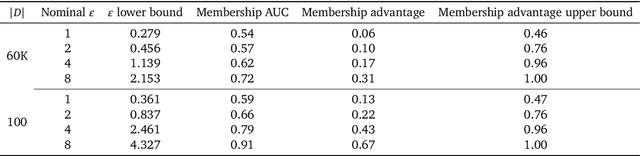
Privacy-preserving machine learning aims to train models on private data without leaking sensitive information. Differential privacy (DP) is considered the gold standard framework for privacy-preserving training, as it provides formal privacy guarantees. However, compared to their non-private counterparts, models trained with DP often have significantly reduced accuracy. Private classifiers are also believed to exhibit larger performance disparities across subpopulations, raising fairness concerns. The poor performance of classifiers trained with DP has prevented the widespread adoption of privacy preserving machine learning in industry. Here we show that pre-trained foundation models fine-tuned with DP can achieve similar accuracy to non-private classifiers, even in the presence of significant distribution shifts between pre-training data and downstream tasks. We achieve private accuracies within a few percent of the non-private state of the art across four datasets, including two medical imaging benchmarks. Furthermore, our private medical classifiers do not exhibit larger performance disparities across demographic groups than non-private models. This milestone to make DP training a practical and reliable technology has the potential to widely enable machine learning practitioners to train safely on sensitive datasets while protecting individuals' privacy.
On the Universality of Linear Recurrences Followed by Nonlinear Projections
Jul 21, 2023



In this note (work in progress towards a full-length paper) we show that a family of sequence models based on recurrent linear layers~(including S4, S5, and the LRU) interleaved with position-wise multi-layer perceptrons~(MLPs) can approximate arbitrarily well any sufficiently regular non-linear sequence-to-sequence map. The main idea behind our result is to see recurrent layers as compression algorithms that can faithfully store information about the input sequence into an inner state, before it is processed by the highly expressive MLP.
Differentially Private Diffusion Models Generate Useful Synthetic Images
Feb 27, 2023



The ability to generate privacy-preserving synthetic versions of sensitive image datasets could unlock numerous ML applications currently constrained by data availability. Due to their astonishing image generation quality, diffusion models are a prime candidate for generating high-quality synthetic data. However, recent studies have found that, by default, the outputs of some diffusion models do not preserve training data privacy. By privately fine-tuning ImageNet pre-trained diffusion models with more than 80M parameters, we obtain SOTA results on CIFAR-10 and Camelyon17 in terms of both FID and the accuracy of downstream classifiers trained on synthetic data. We decrease the SOTA FID on CIFAR-10 from 26.2 to 9.8, and increase the accuracy from 51.0% to 88.0%. On synthetic data from Camelyon17, we achieve a downstream accuracy of 91.1% which is close to the SOTA of 96.5% when training on the real data. We leverage the ability of generative models to create infinite amounts of data to maximise the downstream prediction performance, and further show how to use synthetic data for hyperparameter tuning. Our results demonstrate that diffusion models fine-tuned with differential privacy can produce useful and provably private synthetic data, even in applications with significant distribution shift between the pre-training and fine-tuning distributions.
Unlocking High-Accuracy Differentially Private Image Classification through Scale
Apr 28, 2022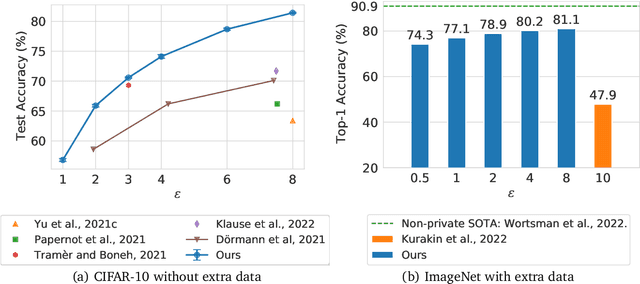
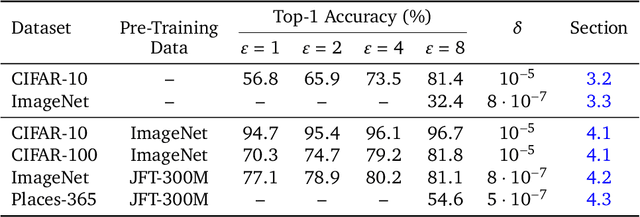


Differential Privacy (DP) provides a formal privacy guarantee preventing adversaries with access to a machine learning model from extracting information about individual training points. Differentially Private Stochastic Gradient Descent (DP-SGD), the most popular DP training method, realizes this protection by injecting noise during training. However previous works have found that DP-SGD often leads to a significant degradation in performance on standard image classification benchmarks. Furthermore, some authors have postulated that DP-SGD inherently performs poorly on large models, since the norm of the noise required to preserve privacy is proportional to the model dimension. In contrast, we demonstrate that DP-SGD on over-parameterized models can perform significantly better than previously thought. Combining careful hyper-parameter tuning with simple techniques to ensure signal propagation and improve the convergence rate, we obtain a new SOTA on CIFAR-10 of 81.4% under (8, 10^{-5})-DP using a 40-layer Wide-ResNet, improving over the previous SOTA of 71.7%. When fine-tuning a pre-trained 200-layer Normalizer-Free ResNet, we achieve a remarkable 77.1% top-1 accuracy on ImageNet under (1, 8*10^{-7})-DP, and achieve 81.1% under (8, 8*10^{-7})-DP. This markedly exceeds the previous SOTA of 47.9% under a larger privacy budget of (10, 10^{-6})-DP. We believe our results are a significant step towards closing the accuracy gap between private and non-private image classification.
Drawing Multiple Augmentation Samples Per Image During Training Efficiently Decreases Test Error
May 27, 2021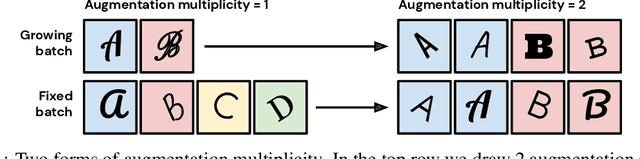

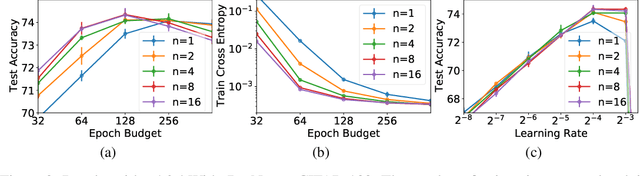

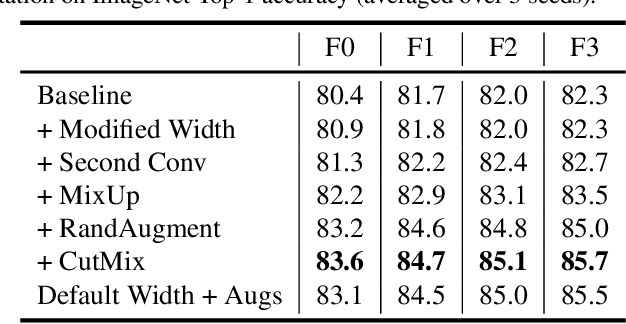
In computer vision, it is standard practice to draw a single sample from the data augmentation procedure for each unique image in the mini-batch, however it is not clear whether this choice is optimal for generalization. In this work, we provide a detailed empirical evaluation of how the number of augmentation samples per unique image influences performance on held out data. Remarkably, we find that drawing multiple samples per image consistently enhances the test accuracy achieved for both small and large batch training, despite reducing the number of unique training examples in each mini-batch. This benefit arises even when different augmentation multiplicities perform the same number of parameter updates and gradient evaluations. Our results suggest that, although the variance in the gradient estimate arising from subsampling the dataset has an implicit regularization benefit, the variance which arises from the data augmentation process harms test accuracy. By applying augmentation multiplicity to the recently proposed NFNet model family, we achieve a new ImageNet state of the art of 86.8$\%$ top-1 w/o extra data.
High-Performance Large-Scale Image Recognition Without Normalization
Feb 11, 2021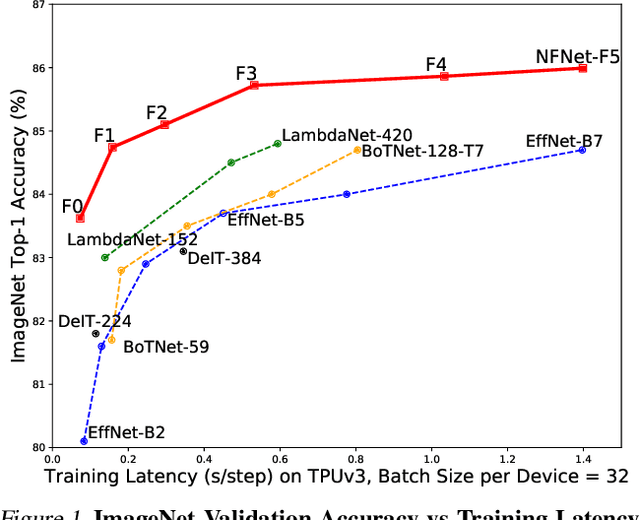
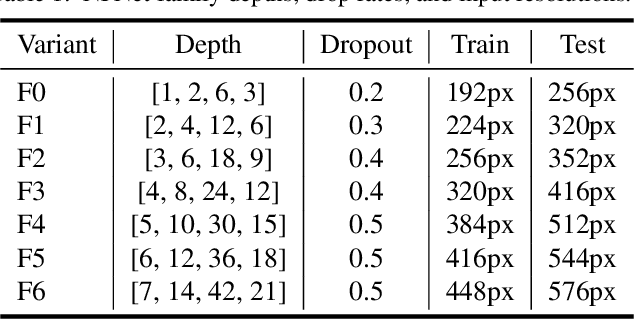
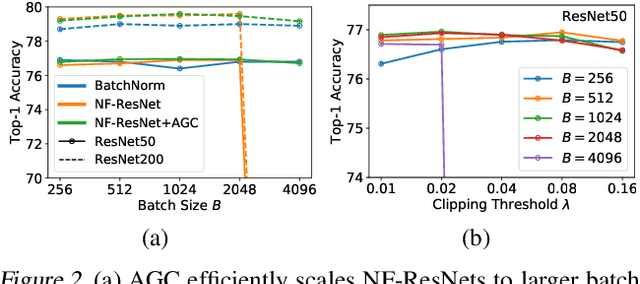
Batch normalization is a key component of most image classification models, but it has many undesirable properties stemming from its dependence on the batch size and interactions between examples. Although recent work has succeeded in training deep ResNets without normalization layers, these models do not match the test accuracies of the best batch-normalized networks, and are often unstable for large learning rates or strong data augmentations. In this work, we develop an adaptive gradient clipping technique which overcomes these instabilities, and design a significantly improved class of Normalizer-Free ResNets. Our smaller models match the test accuracy of an EfficientNet-B7 on ImageNet while being up to 8.7x faster to train, and our largest models attain a new state-of-the-art top-1 accuracy of 86.5%. In addition, Normalizer-Free models attain significantly better performance than their batch-normalized counterparts when finetuning on ImageNet after large-scale pre-training on a dataset of 300 million labeled images, with our best models obtaining an accuracy of 89.2%. Our code is available at https://github.com/deepmind/ deepmind-research/tree/master/nfnets
On the Origin of Implicit Regularization in Stochastic Gradient Descent
Jan 28, 2021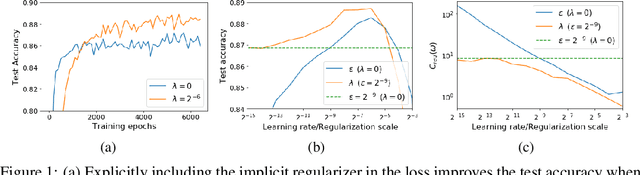
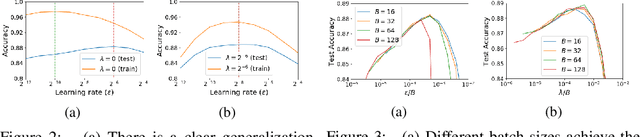
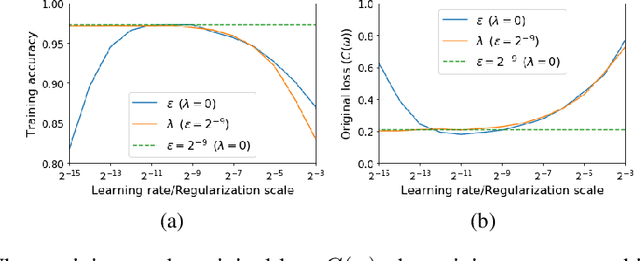
For infinitesimal learning rates, stochastic gradient descent (SGD) follows the path of gradient flow on the full batch loss function. However moderately large learning rates can achieve higher test accuracies, and this generalization benefit is not explained by convergence bounds, since the learning rate which maximizes test accuracy is often larger than the learning rate which minimizes training loss. To interpret this phenomenon we prove that for SGD with random shuffling, the mean SGD iterate also stays close to the path of gradient flow if the learning rate is small and finite, but on a modified loss. This modified loss is composed of the original loss function and an implicit regularizer, which penalizes the norms of the minibatch gradients. Under mild assumptions, when the batch size is small the scale of the implicit regularization term is proportional to the ratio of the learning rate to the batch size. We verify empirically that explicitly including the implicit regularizer in the loss can enhance the test accuracy when the learning rate is small.
Characterizing signal propagation to close the performance gap in unnormalized ResNets
Jan 27, 2021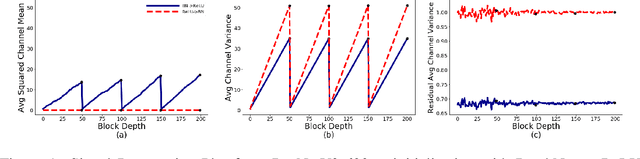

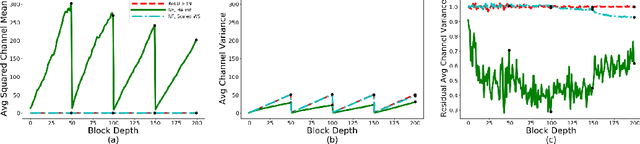

Batch Normalization is a key component in almost all state-of-the-art image classifiers, but it also introduces practical challenges: it breaks the independence between training examples within a batch, can incur compute and memory overhead, and often results in unexpected bugs. Building on recent theoretical analyses of deep ResNets at initialization, we propose a simple set of analysis tools to characterize signal propagation on the forward pass, and leverage these tools to design highly performant ResNets without activation normalization layers. Crucial to our success is an adapted version of the recently proposed Weight Standardization. Our analysis tools show how this technique preserves the signal in networks with ReLU or Swish activation functions by ensuring that the per-channel activation means do not grow with depth. Across a range of FLOP budgets, our networks attain performance competitive with the state-of-the-art EfficientNets on ImageNet.