 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGrow, Don't Overwrite: Fine-tuning Without Forgetting
Mar 09, 2026Adapting pre-trained models to specialized tasks often leads to catastrophic forgetting, where new knowledge overwrites foundational capabilities. Existing methods either compromise performance on the new task or struggle to balance training stability with efficient reuse of pre-trained knowledge. We introduce a novel function-preserving expansion method that resolves this dilemma. Our technique expands model capacity by replicating pre-trained parameters within transformer submodules and applying a scaling correction that guarantees the expanded model is mathematically identical to the original at initialization, enabling stable training while exploiting existing knowledge. Empirically, our method eliminates the trade-off between plasticity and stability, matching the performance of full fine-tuning on downstream tasks without any degradation of the model's original capabilities. Furthermore, we demonstrate the modularity of our approach, showing that by selectively expanding a small subset of layers we can achieve the same performance as full fine-tuning at a fraction of the computational cost.
Learning by solving differential equations
May 19, 2025


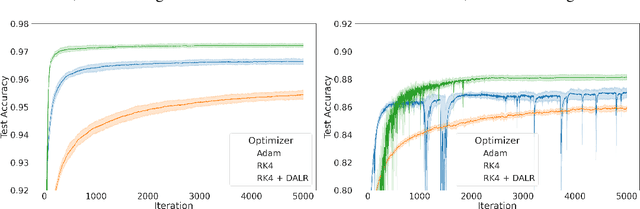
Modern deep learning algorithms use variations of gradient descent as their main learning methods. Gradient descent can be understood as the simplest Ordinary Differential Equation (ODE) solver; namely, the Euler method applied to the gradient flow differential equation. Since Euler, many ODE solvers have been devised that follow the gradient flow equation more precisely and more stably. Runge-Kutta (RK) methods provide a family of very powerful explicit and implicit high-order ODE solvers. However, these higher-order solvers have not found wide application in deep learning so far. In this work, we evaluate the performance of higher-order RK solvers when applied in deep learning, study their limitations, and propose ways to overcome these drawbacks. In particular, we explore how to improve their performance by naturally incorporating key ingredients of modern neural network optimizers such as preconditioning, adaptive learning rates, and momentum.
Training in reverse: How iteration order influences convergence and stability in deep learning
Feb 03, 2025
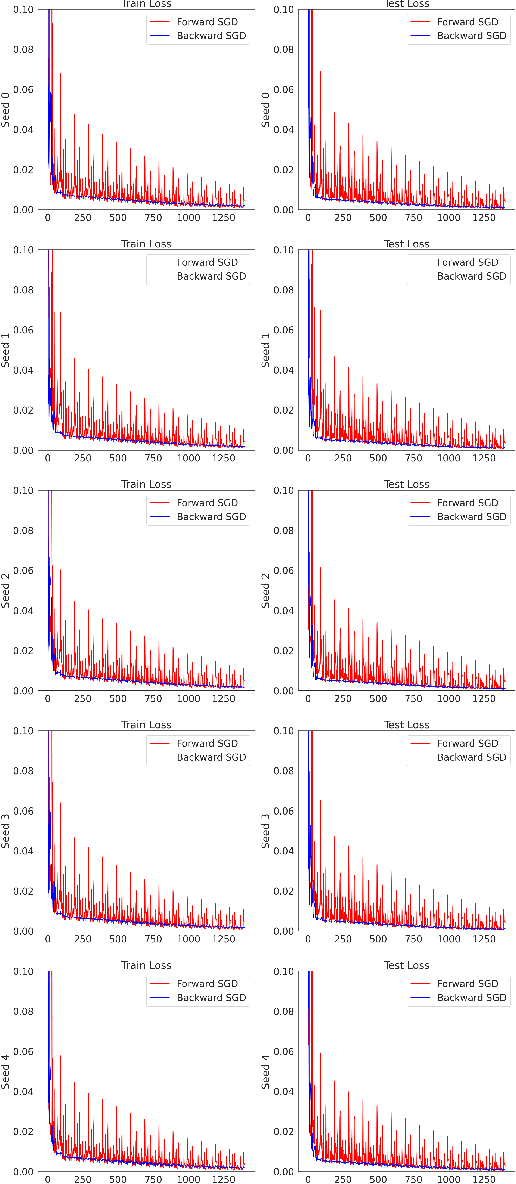


Despite exceptional achievements, training neural networks remains computationally expensive and is often plagued by instabilities that can degrade convergence. While learning rate schedules can help mitigate these issues, finding optimal schedules is time-consuming and resource-intensive. This work explores theoretical issues concerning training stability in the constant-learning-rate (i.e., without schedule) and small-batch-size regime. Surprisingly, we show that the order of gradient updates affects stability and convergence in gradient-based optimizers. We illustrate this new line of thinking using backward-SGD, which processes batch gradient updates like SGD but in reverse order. Our theoretical analysis shows that in contractive regions (e.g., around minima) backward-SGD converges to a point while the standard forward-SGD generally only converges to a distribution. This leads to improved stability and convergence which we demonstrate experimentally. While full backward-SGD is computationally intensive in practice, it highlights opportunities to exploit reverse training dynamics (or more generally alternate iteration orders) to improve training. To our knowledge, this represents a new and unexplored avenue in deep learning optimization.
The Impact of Geometric Complexity on Neural Collapse in Transfer Learning
May 28, 2024



Many of the recent remarkable advances in computer vision and language models can be attributed to the success of transfer learning via the pre-training of large foundation models. However, a theoretical framework which explains this empirical success is incomplete and remains an active area of research. Flatness of the loss surface and neural collapse have recently emerged as useful pre-training metrics which shed light on the implicit biases underlying pre-training. In this paper, we explore the geometric complexity of a model's learned representations as a fundamental mechanism that relates these two concepts. We show through experiments and theory that mechanisms which affect the geometric complexity of the pre-trained network also influence the neural collapse. Furthermore, we show how this effect of the geometric complexity generalizes to the neural collapse of new classes as well, thus encouraging better performance on downstream tasks, particularly in the few-shot setting.
A Margin-based Multiclass Generalization Bound via Geometric Complexity
May 28, 2024

There has been considerable effort to better understand the generalization capabilities of deep neural networks both as a means to unlock a theoretical understanding of their success as well as providing directions for further improvements. In this paper, we investigate margin-based multiclass generalization bounds for neural networks which rely on a recent complexity measure, the geometric complexity, developed for neural networks. We derive a new upper bound on the generalization error which scales with the margin-normalized geometric complexity of the network and which holds for a broad family of data distributions and model classes. Our generalization bound is empirically investigated for a ResNet-18 model trained with SGD on the CIFAR-10 and CIFAR-100 datasets with both original and random labels.
* Accepted as an ICML 2023 workshop paper (Topology, Algebra and Geometry in Machine Learning)
Corridor Geometry in Gradient-Based Optimization
Feb 13, 2024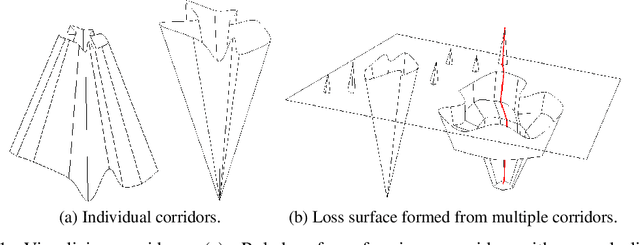
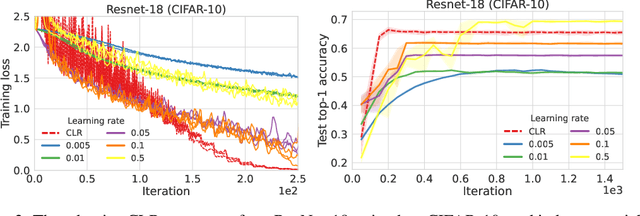
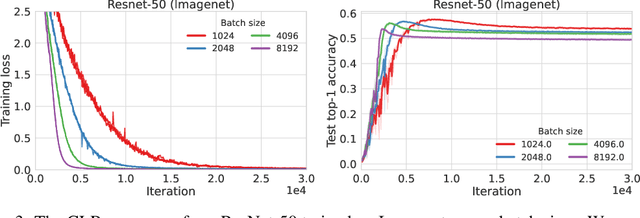
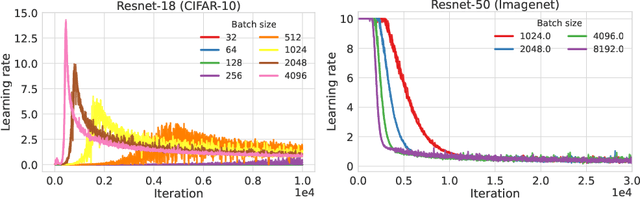
We characterize regions of a loss surface as corridors when the continuous curves of steepest descent -- the solutions of the gradient flow -- become straight lines. We show that corridors provide insights into gradient-based optimization, since corridors are exactly the regions where gradient descent and the gradient flow follow the same trajectory, while the loss decreases linearly. As a result, inside corridors there are no implicit regularization effects or training instabilities that have been shown to occur due to the drift between gradient descent and the gradient flow. Using the loss linear decrease on corridors, we devise a learning rate adaptation scheme for gradient descent; we call this scheme Corridor Learning Rate (CLR). The CLR formulation coincides with a special case of Polyak step-size, discovered in the context of convex optimization. The Polyak step-size has been shown recently to have also good convergence properties for neural networks; we further confirm this here with results on CIFAR-10 and ImageNet.
Implicit biases in multitask and continual learning from a backward error analysis perspective
Nov 01, 2023Using backward error analysis, we compute implicit training biases in multitask and continual learning settings for neural networks trained with stochastic gradient descent. In particular, we derive modified losses that are implicitly minimized during training. They have three terms: the original loss, accounting for convergence, an implicit flatness regularization term proportional to the learning rate, and a last term, the conflict term, which can theoretically be detrimental to both convergence and implicit regularization. In multitask, the conflict term is a well-known quantity, measuring the gradient alignment between the tasks, while in continual learning the conflict term is a new quantity in deep learning optimization, although a basic tool in differential geometry: The Lie bracket between the task gradients.
Morse Neural Networks for Uncertainty Quantification
Jul 02, 2023We introduce a new deep generative model useful for uncertainty quantification: the Morse neural network, which generalizes the unnormalized Gaussian densities to have modes of high-dimensional submanifolds instead of just discrete points. Fitting the Morse neural network via a KL-divergence loss yields 1) a (unnormalized) generative density, 2) an OOD detector, 3) a calibration temperature, 4) a generative sampler, along with in the supervised case 5) a distance aware-classifier. The Morse network can be used on top of a pre-trained network to bring distance-aware calibration w.r.t the training data. Because of its versatility, the Morse neural networks unifies many techniques: e.g., the Entropic Out-of-Distribution Detector of (Mac\^edo et al., 2021) in OOD detection, the one class Deep Support Vector Description method of (Ruff et al., 2018) in anomaly detection, or the Contrastive One Class classifier in continuous learning (Sun et al., 2021). The Morse neural network has connections to support vector machines, kernel methods, and Morse theory in topology.
On a continuous time model of gradient descent dynamics and instability in deep learning
Feb 03, 2023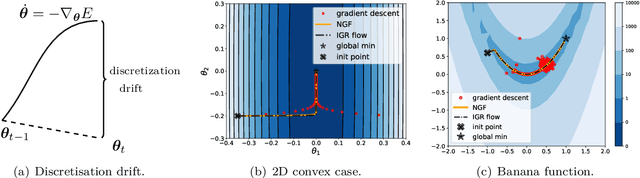
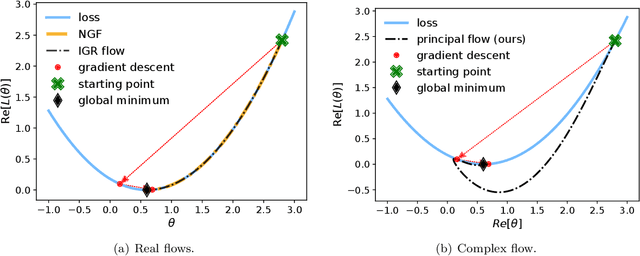
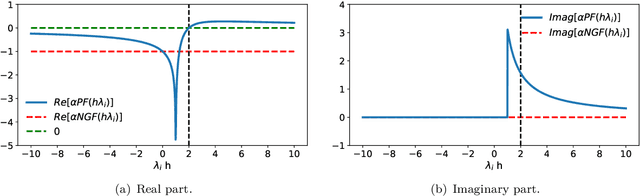
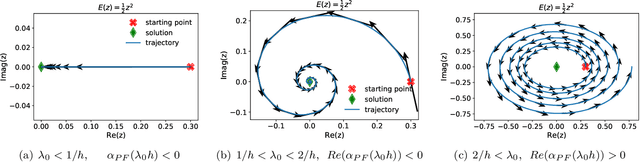
The recipe behind the success of deep learning has been the combination of neural networks and gradient-based optimization. Understanding the behavior of gradient descent however, and particularly its instability, has lagged behind its empirical success. To add to the theoretical tools available to study gradient descent we propose the principal flow (PF), a continuous time flow that approximates gradient descent dynamics. To our knowledge, the PF is the only continuous flow that captures the divergent and oscillatory behaviors of gradient descent, including escaping local minima and saddle points. Through its dependence on the eigendecomposition of the Hessian the PF sheds light on the recently observed edge of stability phenomena in deep learning. Using our new understanding of instability we propose a learning rate adaptation method which enables us to control the trade-off between training stability and test set evaluation performance.
Why neural networks find simple solutions: the many regularizers of geometric complexity
Sep 27, 2022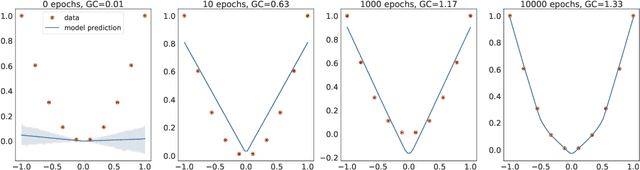
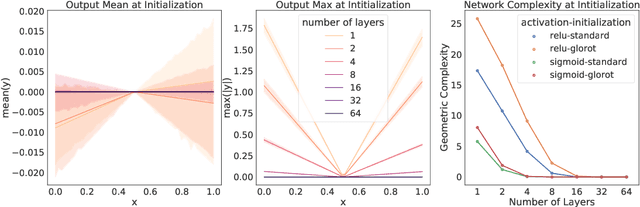
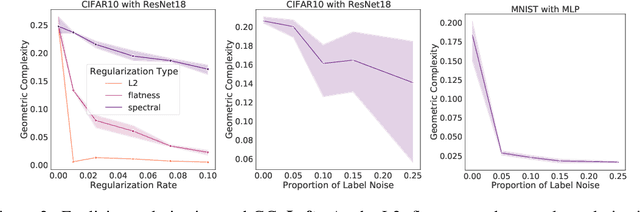
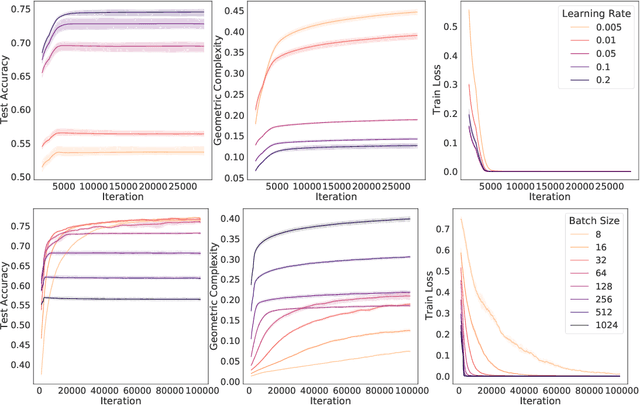
In many contexts, simpler models are preferable to more complex models and the control of this model complexity is the goal for many methods in machine learning such as regularization, hyperparameter tuning and architecture design. In deep learning, it has been difficult to understand the underlying mechanisms of complexity control, since many traditional measures are not naturally suitable for deep neural networks. Here we develop the notion of geometric complexity, which is a measure of the variability of the model function, computed using a discrete Dirichlet energy. Using a combination of theoretical arguments and empirical results, we show that many common training heuristics such as parameter norm regularization, spectral norm regularization, flatness regularization, implicit gradient regularization, noise regularization and the choice of parameter initialization all act to control geometric complexity, providing a unifying framework in which to characterize the behavior of deep learning models.