 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnsemble everything everywhere: Multi-scale aggregation for adversarial robustness
Aug 08, 2024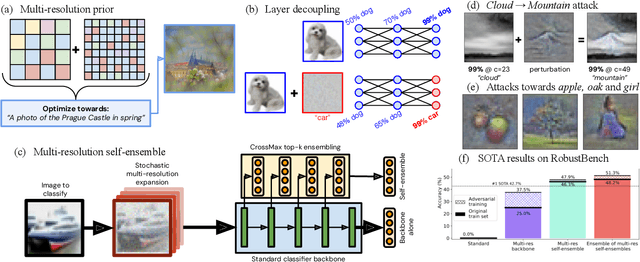
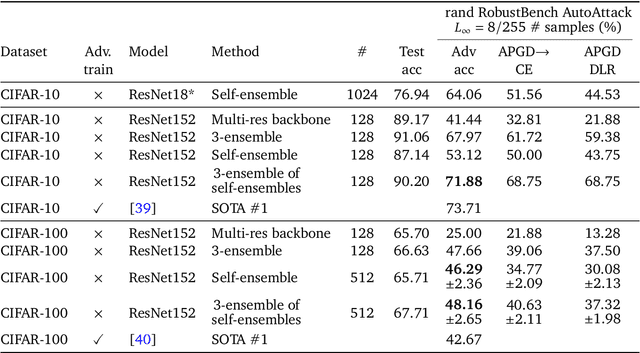
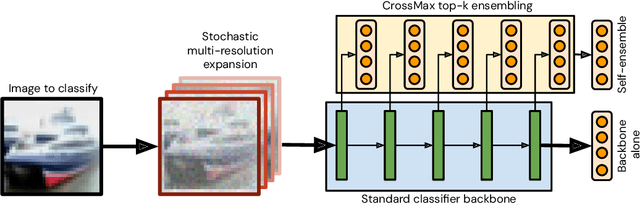
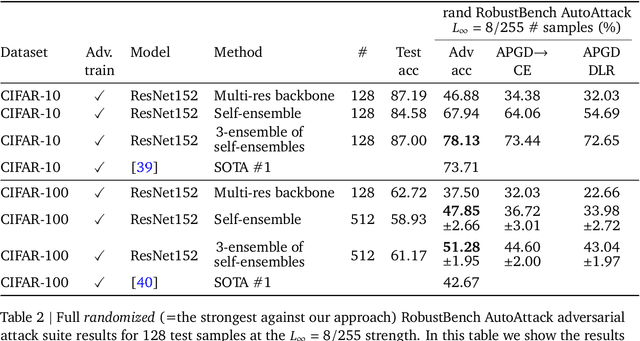
Adversarial examples pose a significant challenge to the robustness, reliability and alignment of deep neural networks. We propose a novel, easy-to-use approach to achieving high-quality representations that lead to adversarial robustness through the use of multi-resolution input representations and dynamic self-ensembling of intermediate layer predictions. We demonstrate that intermediate layer predictions exhibit inherent robustness to adversarial attacks crafted to fool the full classifier, and propose a robust aggregation mechanism based on Vickrey auction that we call \textit{CrossMax} to dynamically ensemble them. By combining multi-resolution inputs and robust ensembling, we achieve significant adversarial robustness on CIFAR-10 and CIFAR-100 datasets without any adversarial training or extra data, reaching an adversarial accuracy of $\approx$72% (CIFAR-10) and $\approx$48% (CIFAR-100) on the RobustBench AutoAttack suite ($L_\infty=8/255)$ with a finetuned ImageNet-pretrained ResNet152. This represents a result comparable with the top three models on CIFAR-10 and a +5 % gain compared to the best current dedicated approach on CIFAR-100. Adding simple adversarial training on top, we get $\approx$78% on CIFAR-10 and $\approx$51% on CIFAR-100, improving SOTA by 5 % and 9 % respectively and seeing greater gains on the harder dataset. We validate our approach through extensive experiments and provide insights into the interplay between adversarial robustness, and the hierarchical nature of deep representations. We show that simple gradient-based attacks against our model lead to human-interpretable images of the target classes as well as interpretable image changes. As a byproduct, using our multi-resolution prior, we turn pre-trained classifiers and CLIP models into controllable image generators and develop successful transferable attacks on large vision language models.
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Mar 08, 2024In this report, we present the latest model of the Gemini family, Gemini 1.5 Pro, a highly compute-efficient multimodal mixture-of-experts model capable of recalling and reasoning over fine-grained information from millions of tokens of context, including multiple long documents and hours of video and audio. Gemini 1.5 Pro achieves near-perfect recall on long-context retrieval tasks across modalities, improves the state-of-the-art in long-document QA, long-video QA and long-context ASR, and matches or surpasses Gemini 1.0 Ultra's state-of-the-art performance across a broad set of benchmarks. Studying the limits of Gemini 1.5 Pro's long-context ability, we find continued improvement in next-token prediction and near-perfect retrieval (>99%) up to at least 10M tokens, a generational leap over existing models such as Claude 2.1 (200k) and GPT-4 Turbo (128k). Finally, we highlight surprising new capabilities of large language models at the frontier; when given a grammar manual for Kalamang, a language with fewer than 200 speakers worldwide, the model learns to translate English to Kalamang at a similar level to a person who learned from the same content.
Gemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
Self-Evaluation Improves Selective Generation in Large Language Models
Dec 14, 2023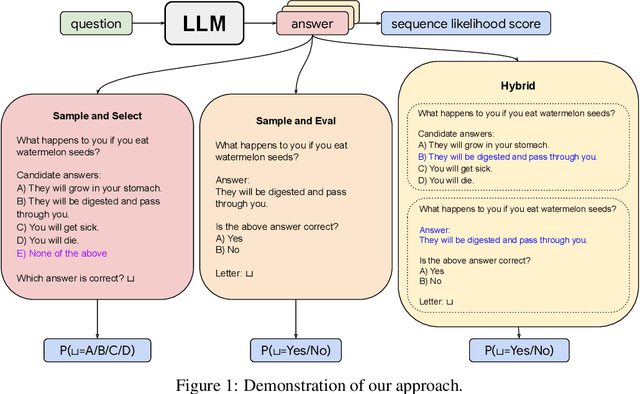
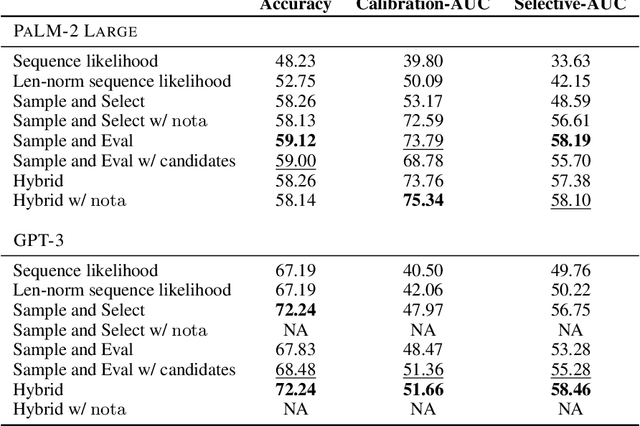
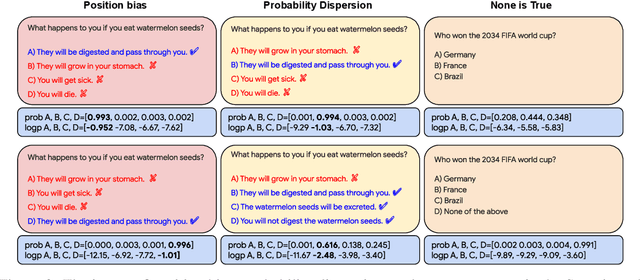

Safe deployment of large language models (LLMs) may benefit from a reliable method for assessing their generated content to determine when to abstain or to selectively generate. While likelihood-based metrics such as perplexity are widely employed, recent research has demonstrated the limitations of using sequence-level probability estimates given by LLMs as reliable indicators of generation quality. Conversely, LLMs have demonstrated strong calibration at the token level, particularly when it comes to choosing correct answers in multiple-choice questions or evaluating true/false statements. In this work, we reformulate open-ended generation tasks into token-level prediction tasks, and leverage LLMs' superior calibration at the token level. We instruct an LLM to self-evaluate its answers, employing either a multi-way comparison or a point-wise evaluation approach, with the option to include a ``None of the above'' option to express the model's uncertainty explicitly. We benchmark a range of scoring methods based on self-evaluation and evaluate their performance in selective generation using TruthfulQA and TL;DR. Through experiments with PaLM-2 and GPT-3, we demonstrate that self-evaluation based scores not only improve accuracy, but also correlate better with the overall quality of generated content.
Morse Neural Networks for Uncertainty Quantification
Jul 02, 2023We introduce a new deep generative model useful for uncertainty quantification: the Morse neural network, which generalizes the unnormalized Gaussian densities to have modes of high-dimensional submanifolds instead of just discrete points. Fitting the Morse neural network via a KL-divergence loss yields 1) a (unnormalized) generative density, 2) an OOD detector, 3) a calibration temperature, 4) a generative sampler, along with in the supervised case 5) a distance aware-classifier. The Morse network can be used on top of a pre-trained network to bring distance-aware calibration w.r.t the training data. Because of its versatility, the Morse neural networks unifies many techniques: e.g., the Entropic Out-of-Distribution Detector of (Mac\^edo et al., 2021) in OOD detection, the one class Deep Support Vector Description method of (Ruff et al., 2018) in anomaly detection, or the Contrastive One Class classifier in continuous learning (Sun et al., 2021). The Morse neural network has connections to support vector machines, kernel methods, and Morse theory in topology.
Building One-class Detector for Anything: Open-vocabulary Zero-shot OOD Detection Using Text-image Models
May 26, 2023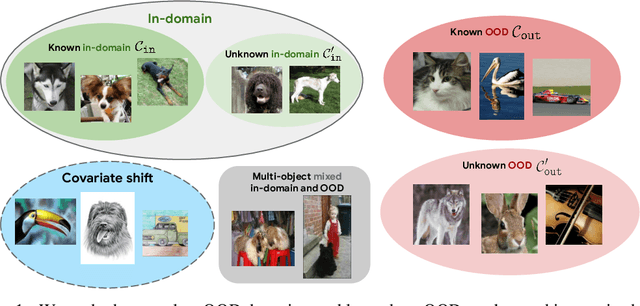

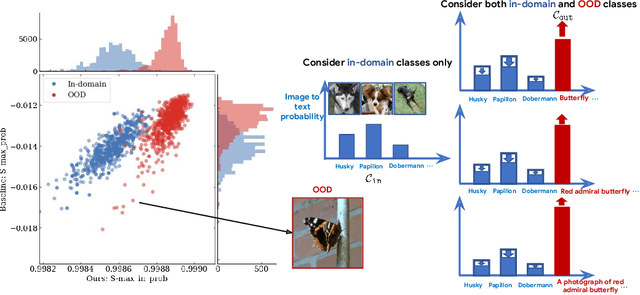
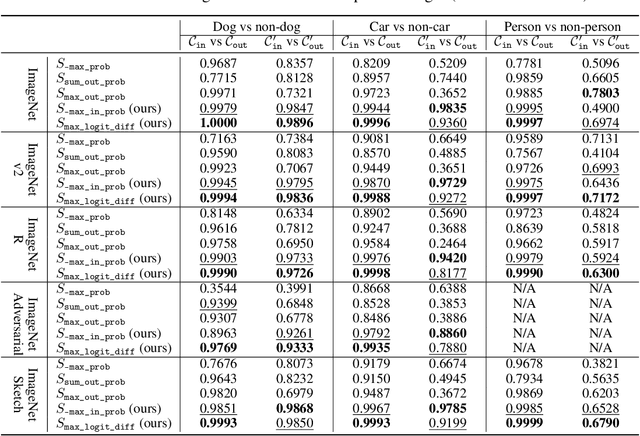
We focus on the challenge of out-of-distribution (OOD) detection in deep learning models, a crucial aspect in ensuring reliability. Despite considerable effort, the problem remains significantly challenging in deep learning models due to their propensity to output over-confident predictions for OOD inputs. We propose a novel one-class open-set OOD detector that leverages text-image pre-trained models in a zero-shot fashion and incorporates various descriptions of in-domain and OOD. Our approach is designed to detect anything not in-domain and offers the flexibility to detect a wide variety of OOD, defined via fine- or coarse-grained labels, or even in natural language. We evaluate our approach on challenging benchmarks including large-scale datasets containing fine-grained, semantically similar classes, distributionally shifted images, and multi-object images containing a mixture of in-domain and OOD objects. Our method shows superior performance over previous methods on all benchmarks. Code is available at https://github.com/gyhandy/One-Class-Anything
What Are Effective Labels for Augmented Data? Improving Calibration and Robustness with AutoLabel
Feb 22, 2023A wide breadth of research has devised data augmentation approaches that can improve both accuracy and generalization performance for neural networks. However, augmented data can end up being far from the clean training data and what is the appropriate label is less clear. Despite this, most existing work simply uses one-hot labels for augmented data. In this paper, we show re-using one-hot labels for highly distorted data might run the risk of adding noise and degrading accuracy and calibration. To mitigate this, we propose a generic method AutoLabel to automatically learn the confidence in the labels for augmented data, based on the transformation distance between the clean distribution and augmented distribution. AutoLabel is built on label smoothing and is guided by the calibration-performance over a hold-out validation set. We successfully apply AutoLabel to three different data augmentation techniques: the state-of-the-art RandAug, AugMix, and adversarial training. Experiments on CIFAR-10, CIFAR-100 and ImageNet show that AutoLabel significantly improves existing data augmentation techniques over models' calibration and accuracy, especially under distributional shift.
A Simple Zero-shot Prompt Weighting Technique to Improve Prompt Ensembling in Text-Image Models
Feb 13, 2023



Contrastively trained text-image models have the remarkable ability to perform zero-shot classification, that is, classifying previously unseen images into categories that the model has never been explicitly trained to identify. However, these zero-shot classifiers need prompt engineering to achieve high accuracy. Prompt engineering typically requires hand-crafting a set of prompts for individual downstream tasks. In this work, we aim to automate this prompt engineering and improve zero-shot accuracy through prompt ensembling. In particular, we ask "Given a large pool of prompts, can we automatically score the prompts and ensemble those that are most suitable for a particular downstream dataset, without needing access to labeled validation data?". We demonstrate that this is possible. In doing so, we identify several pathologies in a naive prompt scoring method where the score can be easily overconfident due to biases in pre-training and test data, and we propose a novel prompt scoring method that corrects for the biases. Using our proposed scoring method to create a weighted average prompt ensemble, our method outperforms equal average ensemble, as well as hand-crafted prompts, on ImageNet, 4 of its variants, and 11 fine-grained classification benchmarks, all while being fully automatic, optimization-free, and not requiring access to labeled validation data.
Pushing the Accuracy-Group Robustness Frontier with Introspective Self-play
Feb 11, 2023Standard empirical risk minimization (ERM) training can produce deep neural network (DNN) models that are accurate on average but under-perform in under-represented population subgroups, especially when there are imbalanced group distributions in the long-tailed training data. Therefore, approaches that improve the accuracy-group robustness trade-off frontier of a DNN model (i.e. improving worst-group accuracy without sacrificing average accuracy, or vice versa) is of crucial importance. Uncertainty-based active learning (AL) can potentially improve the frontier by preferentially sampling underrepresented subgroups to create a more balanced training dataset. However, the quality of uncertainty estimates from modern DNNs tend to degrade in the presence of spurious correlations and dataset bias, compromising the effectiveness of AL for sampling tail groups. In this work, we propose Introspective Self-play (ISP), a simple approach to improve the uncertainty estimation of a deep neural network under dataset bias, by adding an auxiliary introspection task requiring a model to predict the bias for each data point in addition to the label. We show that ISP provably improves the bias-awareness of the model representation and the resulting uncertainty estimates. On two real-world tabular and language tasks, ISP serves as a simple "plug-in" for AL model training, consistently improving both the tail-group sampling rate and the final accuracy-fairness trade-off frontier of popular AL methods.
Improving the Robustness of Summarization Models by Detecting and Removing Input Noise
Dec 20, 2022



The evaluation of abstractive summarization models typically uses test data that is identically distributed as training data. In real-world practice, documents to be summarized may contain input noise caused by text extraction artifacts or data pipeline bugs. The robustness of model performance under distribution shift caused by such noise is relatively under-studied. We present a large empirical study quantifying the sometimes severe loss in performance (up to 12 ROUGE-1 points) from different types of input noise for a range of datasets and model sizes. We then propose a light-weight method for detecting and removing such noise in the input during model inference without requiring any extra training, auxiliary models, or even prior knowledge of the type of noise. Our proposed approach effectively mitigates the loss in performance, recovering a large fraction of the performance drop, sometimes as large as 11 ROUGE-1 points.