 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Reason for Hallucination Span Detection
Oct 02, 2025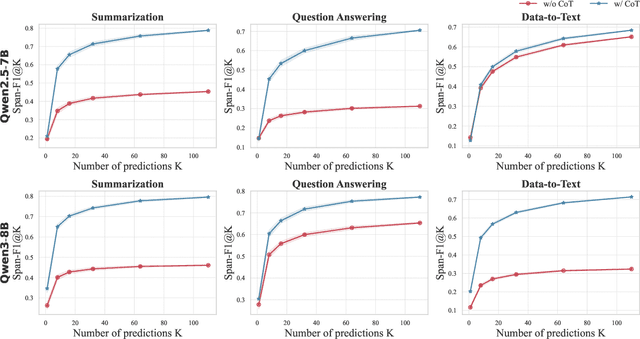
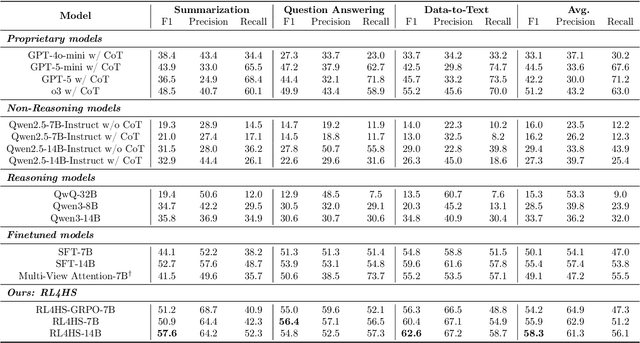
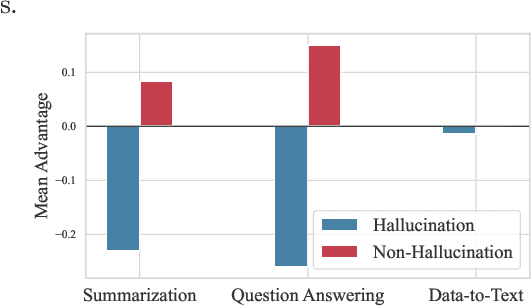
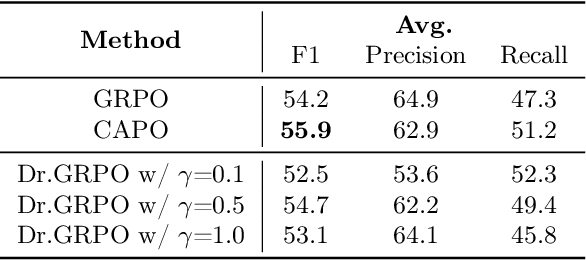
Large language models (LLMs) often generate hallucinations -- unsupported content that undermines reliability. While most prior works frame hallucination detection as a binary task, many real-world applications require identifying hallucinated spans, which is a multi-step decision making process. This naturally raises the question of whether explicit reasoning can help the complex task of detecting hallucination spans. To answer this question, we first evaluate pretrained models with and without Chain-of-Thought (CoT) reasoning, and show that CoT reasoning has the potential to generate at least one correct answer when sampled multiple times. Motivated by this, we propose RL4HS, a reinforcement learning framework that incentivizes reasoning with a span-level reward function. RL4HS builds on Group Relative Policy Optimization and introduces Class-Aware Policy Optimization to mitigate reward imbalance issue. Experiments on the RAGTruth benchmark (summarization, question answering, data-to-text) show that RL4HS surpasses pretrained reasoning models and supervised fine-tuning, demonstrating the necessity of reinforcement learning with span-level rewards for detecting hallucination spans.
Towards Bidirectional Human-AI Alignment: A Systematic Review for Clarifications, Framework, and Future Directions
Jun 17, 2024Recent advancements in general-purpose AI have highlighted the importance of guiding AI systems towards the intended goals, ethical principles, and values of individuals and groups, a concept broadly recognized as alignment. However, the lack of clarified definitions and scopes of human-AI alignment poses a significant obstacle, hampering collaborative efforts across research domains to achieve this alignment. In particular, ML- and philosophy-oriented alignment research often views AI alignment as a static, unidirectional process (i.e., aiming to ensure that AI systems' objectives match humans) rather than an ongoing, mutual alignment problem [429]. This perspective largely neglects the long-term interaction and dynamic changes of alignment. To understand these gaps, we introduce a systematic review of over 400 papers published between 2019 and January 2024, spanning multiple domains such as Human-Computer Interaction (HCI), Natural Language Processing (NLP), Machine Learning (ML), and others. We characterize, define and scope human-AI alignment. From this, we present a conceptual framework of "Bidirectional Human-AI Alignment" to organize the literature from a human-centered perspective. This framework encompasses both 1) conventional studies of aligning AI to humans that ensures AI produces the intended outcomes determined by humans, and 2) a proposed concept of aligning humans to AI, which aims to help individuals and society adjust to AI advancements both cognitively and behaviorally. Additionally, we articulate the key findings derived from literature analysis, including discussions about human values, interaction techniques, and evaluations. To pave the way for future studies, we envision three key challenges for future directions and propose examples of potential future solutions.
GenAudit: Fixing Factual Errors in Language Model Outputs with Evidence
Feb 19, 2024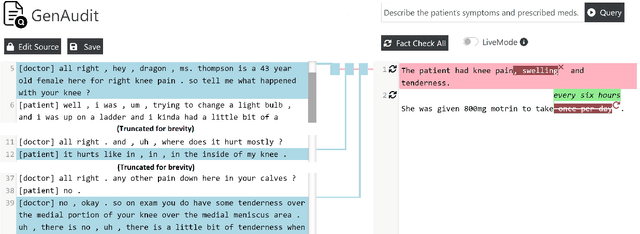


LLMs can generate factually incorrect statements even when provided access to reference documents. Such errors can be dangerous in high-stakes applications (e.g., document-grounded QA for healthcare or finance). We present GenAudit -- a tool intended to assist fact-checking LLM responses for document-grounded tasks. GenAudit suggests edits to the LLM response by revising or removing claims that are not supported by the reference document, and also presents evidence from the reference for facts that do appear to have support. We train models to execute these tasks, and design an interactive interface to present suggested edits and evidence to users. Comprehensive evaluation by human raters shows that GenAudit can detect errors in 8 different LLM outputs when summarizing documents from diverse domains. To ensure that most errors are flagged by the system, we propose a method that can increase the error recall while minimizing impact on precision. We will release our tool (GenAudit) and fact-checking model for public use.
Evaluating the Factuality of Zero-shot Summarizers Across Varied Domains
Feb 05, 2024



Recent work has shown that large language models (LLMs) are capable of generating summaries zero-shot (i.e., without explicit supervision) that, under human assessment, are often comparable or even preferred to manually composed reference summaries. However, this prior work has focussed almost exclusively on evaluating news article summarization. How do zero-shot summarizers perform in other (potentially more specialized) domains? In this work we evaluate zero-shot generated summaries across specialized domains including biomedical articles, and legal bills (in addition to standard news benchmarks for reference). We focus especially on the factuality of outputs. We acquire annotations from domain experts to identify inconsistencies in summaries and systematically categorize these errors. We analyze whether the prevalence of a given domain in the pretraining corpus affects extractiveness and faithfulness of generated summaries of articles in this domain. We release all collected annotations to facilitate additional research toward measuring and realizing factually accurate summarization, beyond news articles. The dataset can be downloaded from https://github.com/sanjanaramprasad/zero_shot_faceval_domains
USB: A Unified Summarization Benchmark Across Tasks and Domains
May 23, 2023



An abundance of datasets exist for training and evaluating models on the task of summary generation.However, these datasets are often derived heuristically, and lack sufficient annotations to support research into all aspects of summarization, such as evidence extraction and controllable summarization. We introduce a benchmark comprising 8 tasks that require multi-dimensional understanding of summarization, e.g., surfacing evidence for a summary, assessing its correctness, and gauging its relevance to different topics. We compare various methods on this benchmark and discover that on multiple tasks, moderately-sized fine-tuned models consistently outperform much larger few-shot prompted language models. For factuality related tasks, we also evaluate existing heuristics to create training data and find that training on them performs worse than training on $20\times$ less human-labeled data. Our benchmark consists of data from 6 different domains, allowing us to study cross-domain performance of trained models. We find that for some tasks, the amount of training data matters more than the domain where it comes from, while for other tasks training specifically on data from the target domain, even if limited, is more beneficial. Our work fulfills the need for a well-annotated summarization benchmark with diverse tasks, and provides useful insights about the impact of the quality, size and domain of training data.
Improving the Robustness of Summarization Models by Detecting and Removing Input Noise
Dec 20, 2022



The evaluation of abstractive summarization models typically uses test data that is identically distributed as training data. In real-world practice, documents to be summarized may contain input noise caused by text extraction artifacts or data pipeline bugs. The robustness of model performance under distribution shift caused by such noise is relatively under-studied. We present a large empirical study quantifying the sometimes severe loss in performance (up to 12 ROUGE-1 points) from different types of input noise for a range of datasets and model sizes. We then propose a light-weight method for detecting and removing such noise in the input during model inference without requiring any extra training, auxiliary models, or even prior knowledge of the type of noise. Our proposed approach effectively mitigates the loss in performance, recovering a large fraction of the performance drop, sometimes as large as 11 ROUGE-1 points.
Out-of-Distribution Detection and Selective Generation for Conditional Language Models
Sep 30, 2022
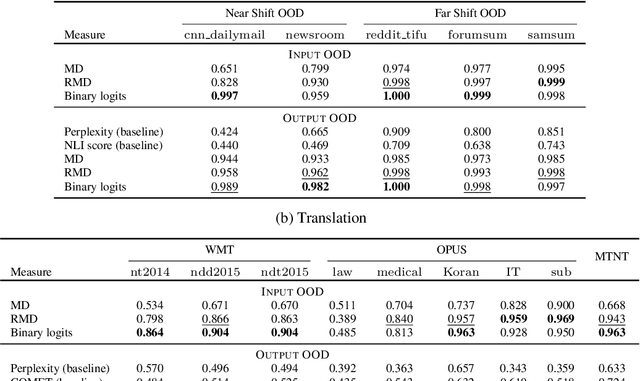
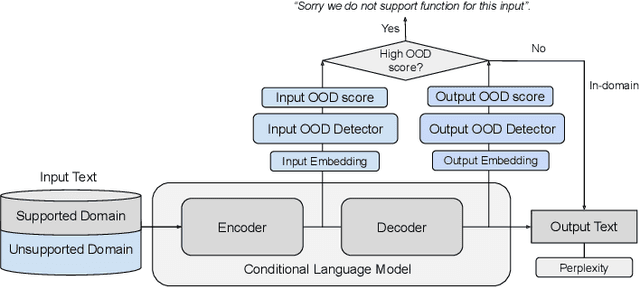

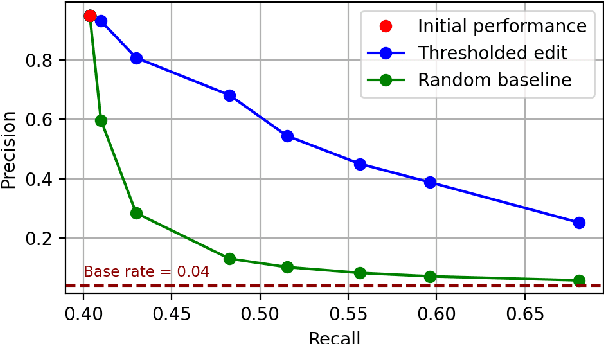
Machine learning algorithms typically assume independent and identically distributed samples in training and at test time. Much work has shown that high-performing ML classifiers can degrade significantly and provide overly-confident, wrong classification predictions, particularly for out-of-distribution (OOD) inputs. Conditional language models (CLMs) are predominantly trained to classify the next token in an output sequence, and may suffer even worse degradation on OOD inputs as the prediction is done auto-regressively over many steps. Furthermore, the space of potential low-quality outputs is larger as arbitrary text can be generated and it is important to know when to trust the generated output. We present a highly accurate and lightweight OOD detection method for CLMs, and demonstrate its effectiveness on abstractive summarization and translation. We also show how our method can be used under the common and realistic setting of distribution shift for selective generation (analogous to selective prediction for classification) of high-quality outputs, while automatically abstaining from low-quality ones, enabling safer deployment of generative language models.
Downstream Datasets Make Surprisingly Good Pretraining Corpora
Sep 28, 2022
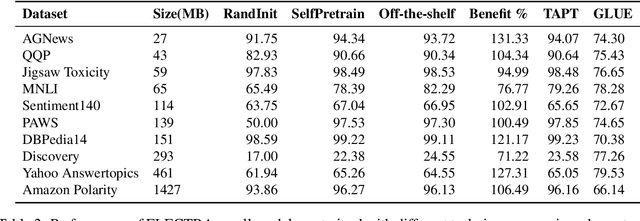
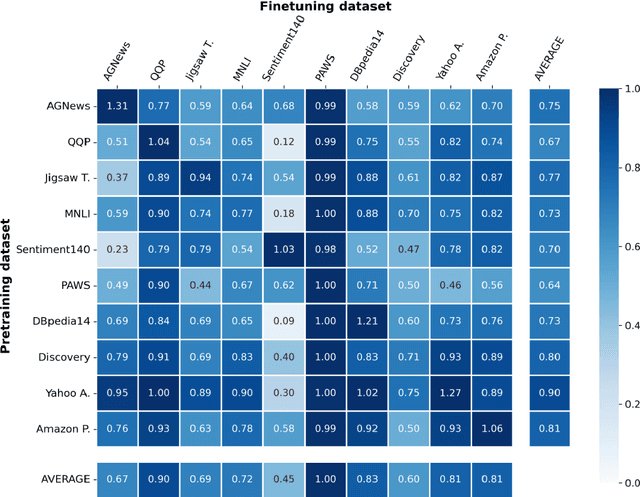
For most natural language processing tasks, the dominant practice is to finetune large pretrained transformer models (e.g., BERT) using smaller downstream datasets. Despite the success of this approach, it remains unclear to what extent these gains are attributable to the massive background corpora employed for pretraining versus to the pretraining objectives themselves. This paper introduces a large-scale study of self-pretraining, where the same (downstream) training data is used for both pretraining and finetuning. In experiments addressing both ELECTRA and RoBERTa models and 10 distinct downstream datasets, we observe that self-pretraining rivals standard pretraining on the BookWiki corpus (despite using around $10\times$--$500\times$ less data), outperforming the latter on $7$ and $5$ datasets, respectively. Surprisingly, these task-specific pretrained models often perform well on other tasks, including the GLUE benchmark. Our results suggest that in many scenarios, performance gains attributable to pretraining are driven primarily by the pretraining objective itself and are not always attributable to the incorporation of massive datasets. These findings are especially relevant in light of concerns about intellectual property and offensive content in web-scale pretraining data.
Does Pretraining for Summarization Require Knowledge Transfer?
Sep 10, 2021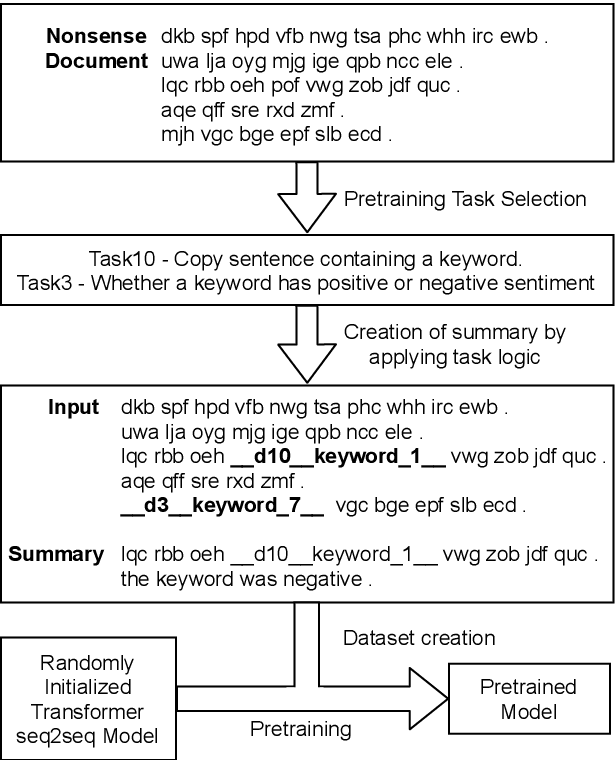
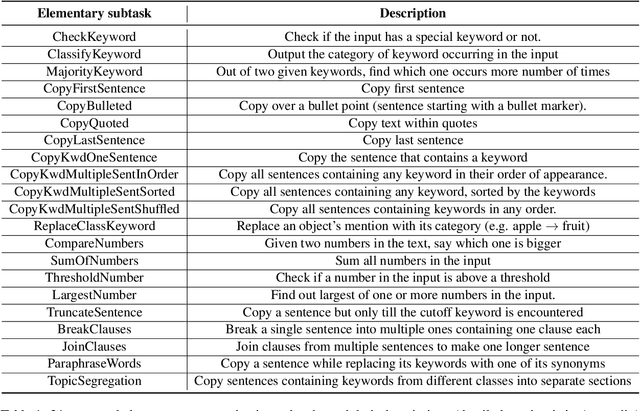
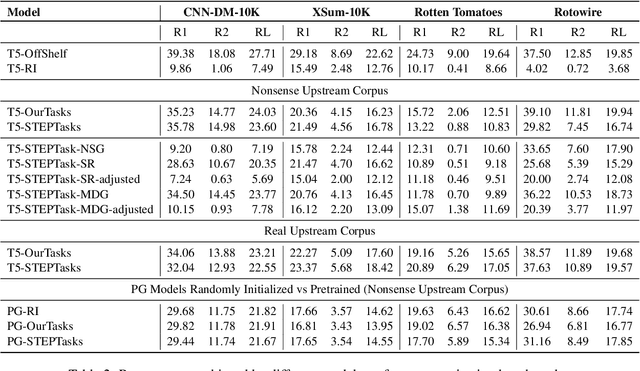
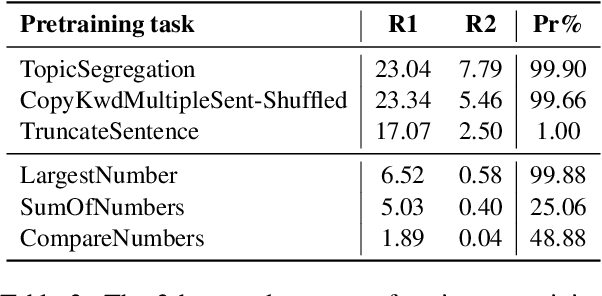
Pretraining techniques leveraging enormous datasets have driven recent advances in text summarization. While folk explanations suggest that knowledge transfer accounts for pretraining's benefits, little is known about why it works or what makes a pretraining task or dataset suitable. In this paper, we challenge the knowledge transfer story, showing that pretraining on documents consisting of character n-grams selected at random, we can nearly match the performance of models pretrained on real corpora. This work holds the promise of eliminating upstream corpora, which may alleviate some concerns over offensive language, bias, and copyright issues. To see whether the small residual benefit of using real data could be accounted for by the structure of the pretraining task, we design several tasks motivated by a qualitative study of summarization corpora. However, these tasks confer no appreciable benefit, leaving open the possibility of a small role for knowledge transfer.
Extracting Structured Data from Physician-Patient Conversations By Predicting Noteworthy Utterances
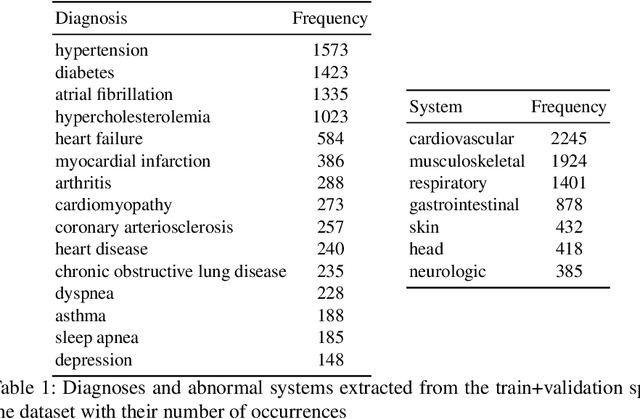
Jul 14, 2020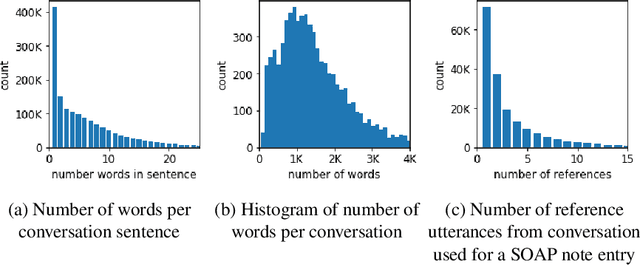
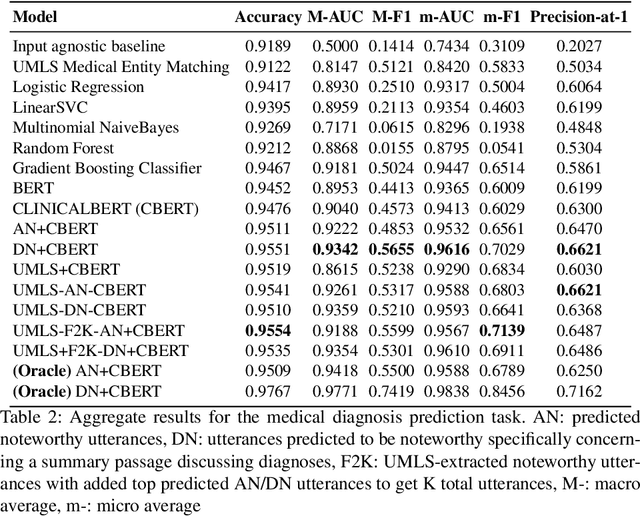
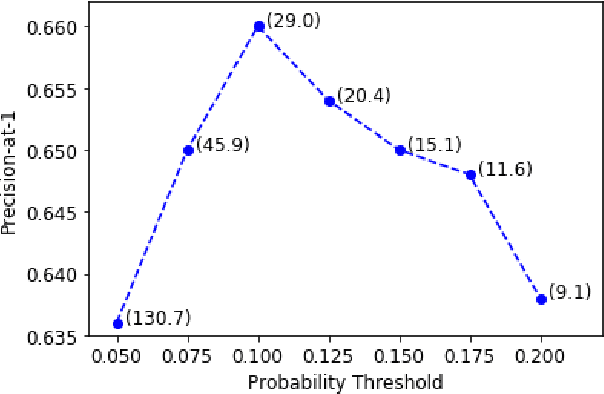
Despite diverse efforts to mine various modalities of medical data, the conversations between physicians and patients at the time of care remain an untapped source of insights. In this paper, we leverage this data to extract structured information that might assist physicians with post-visit documentation in electronic health records, potentially lightening the clerical burden. In this exploratory study, we describe a new dataset consisting of conversation transcripts, post-visit summaries, corresponding supporting evidence (in the transcript), and structured labels. We focus on the tasks of recognizing relevant diagnoses and abnormalities in the review of organ systems (RoS). One methodological challenge is that the conversations are long (around 1500 words), making it difficult for modern deep-learning models to use them as input. To address this challenge, we extract noteworthy utterances---parts of the conversation likely to be cited as evidence supporting some summary sentence. We find that by first filtering for (predicted) noteworthy utterances, we can significantly boost predictive performance for recognizing both diagnoses and RoS abnormalities.