 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeApple Intelligence Foundation Language Models
Jul 29, 2024



We present foundation language models developed to power Apple Intelligence features, including a ~3 billion parameter model designed to run efficiently on devices and a large server-based language model designed for Private Cloud Compute. These models are designed to perform a wide range of tasks efficiently, accurately, and responsibly. This report describes the model architecture, the data used to train the model, the training process, how the models are optimized for inference, and the evaluation results. We highlight our focus on Responsible AI and how the principles are applied throughout the model development.
DialCrowd 2.0: A Quality-Focused Dialog System Crowdsourcing Toolkit
Jul 25, 2022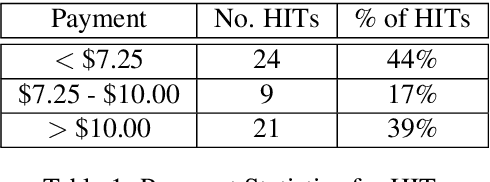
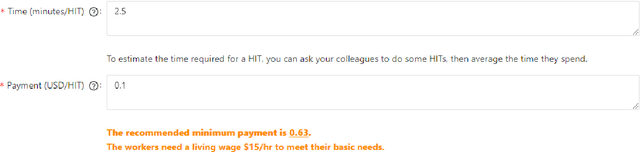
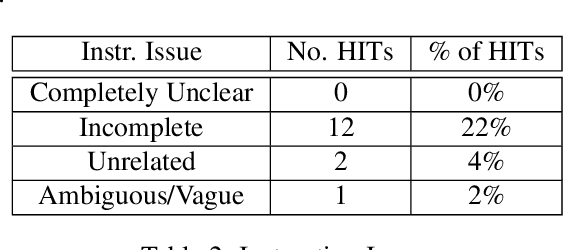
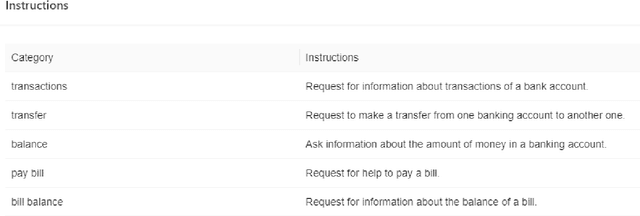
Dialog system developers need high-quality data to train, fine-tune and assess their systems. They often use crowdsourcing for this since it provides large quantities of data from many workers. However, the data may not be of sufficiently good quality. This can be due to the way that the requester presents a task and how they interact with the workers. This paper introduces DialCrowd 2.0 to help requesters obtain higher quality data by, for example, presenting tasks more clearly and facilitating effective communication with workers. DialCrowd 2.0 guides developers in creating improved Human Intelligence Tasks (HITs) and is directly applicable to the workflows used currently by developers and researchers.
A Survey of NLP-Related Crowdsourcing HITs: what works and what does not
Nov 09, 2021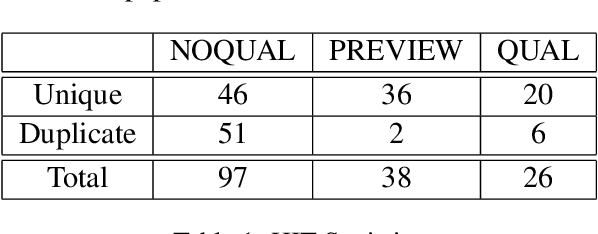
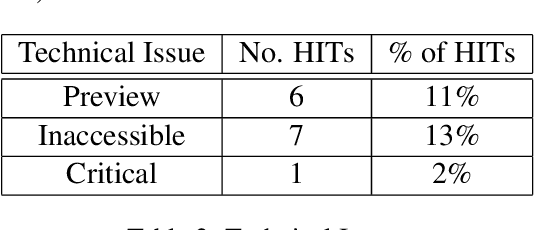

Crowdsourcing requesters on Amazon Mechanical Turk (AMT) have raised questions about the reliability of the workers. The AMT workforce is very diverse and it is not possible to make blanket assumptions about them as a group. Some requesters now reject work en mass when they do not get the results they expect. This has the effect of giving each worker (good or bad) a lower Human Intelligence Task (HIT) approval score, which is unfair to the good workers. It also has the effect of giving the requester a bad reputation on the workers' forums. Some of the issues causing the mass rejections stem from the requesters not taking the time to create a well-formed task with complete instructions and/or not paying a fair wage. To explore this assumption, this paper describes a study that looks at the crowdsourcing HITs on AMT that were available over a given span of time and records information about those HITs. This study also records information from a crowdsourcing forum on the worker perspective on both those HITs and on their corresponding requesters. Results reveal issues in worker payment and presentation issues such as missing instructions or HITs that are not doable.
Does Pretraining for Summarization Require Knowledge Transfer?
Sep 10, 2021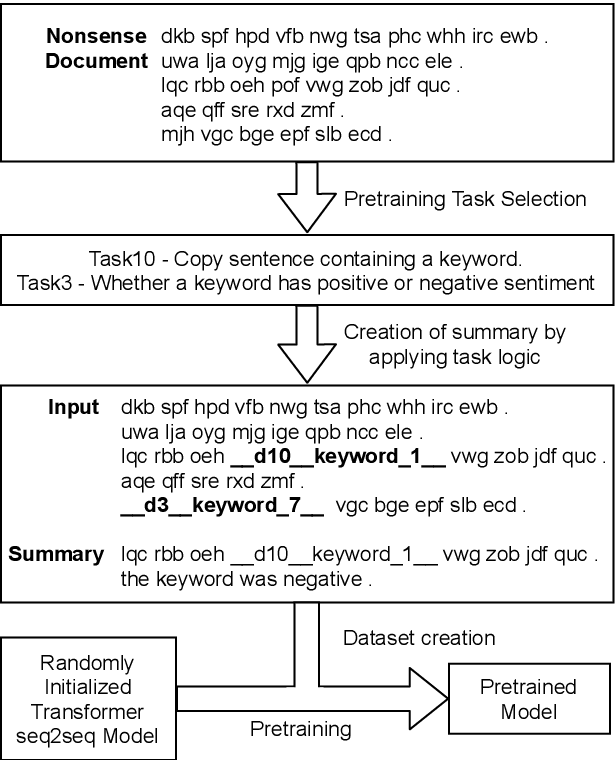
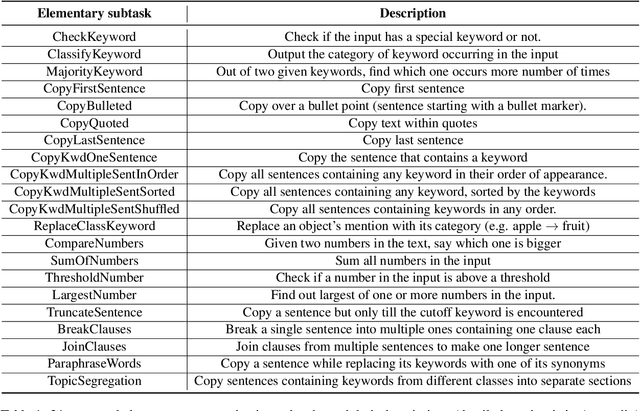
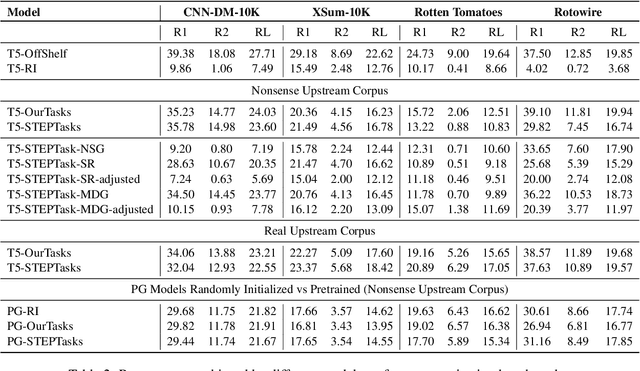
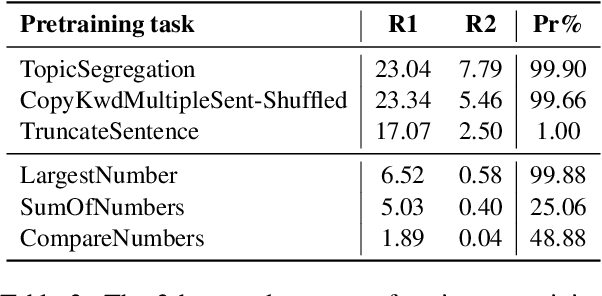
Pretraining techniques leveraging enormous datasets have driven recent advances in text summarization. While folk explanations suggest that knowledge transfer accounts for pretraining's benefits, little is known about why it works or what makes a pretraining task or dataset suitable. In this paper, we challenge the knowledge transfer story, showing that pretraining on documents consisting of character n-grams selected at random, we can nearly match the performance of models pretrained on real corpora. This work holds the promise of eliminating upstream corpora, which may alleviate some concerns over offensive language, bias, and copyright issues. To see whether the small residual benefit of using real data could be accounted for by the structure of the pretraining task, we design several tasks motivated by a qualitative study of summarization corpora. However, these tasks confer no appreciable benefit, leaving open the possibility of a small role for knowledge transfer.
Challenging common interpretability assumptions in feature attribution explanations
Dec 04, 2020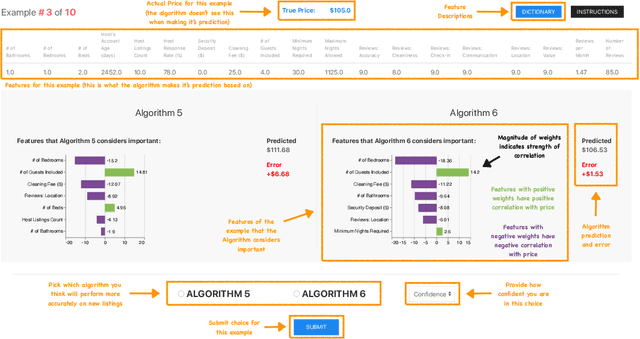

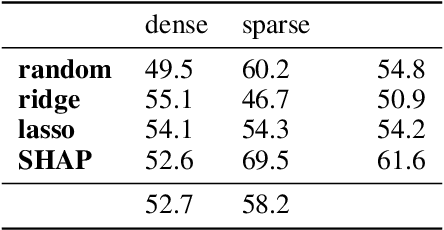
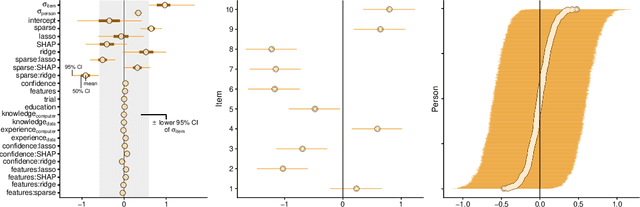
As machine learning and algorithmic decision making systems are increasingly being leveraged in high-stakes human-in-the-loop settings, there is a pressing need to understand the rationale of their predictions. Researchers have responded to this need with explainable AI (XAI), but often proclaim interpretability axiomatically without evaluation. When these systems are evaluated, they are often tested through offline simulations with proxy metrics of interpretability (such as model complexity). We empirically evaluate the veracity of three common interpretability assumptions through a large scale human-subjects experiment with a simple "placebo explanation" control. We find that feature attribution explanations provide marginal utility in our task for a human decision maker and in certain cases result in worse decisions due to cognitive and contextual confounders. This result challenges the assumed universal benefit of applying these methods and we hope this work will underscore the importance of human evaluation in XAI research. Supplemental materials -- including anonymized data from the experiment, code to replicate the study, an interactive demo of the experiment, and the models used in the analysis -- can be found at: https://doi.pizza/challenging-xai.
Combining Independent Modules in Lexical Multiple-Choice Problems
Jan 10, 2005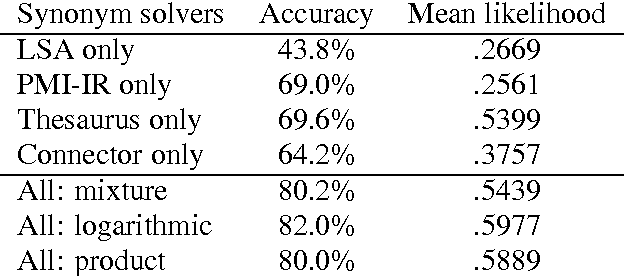
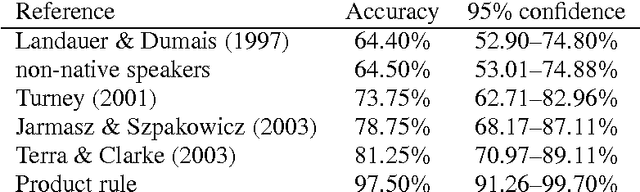
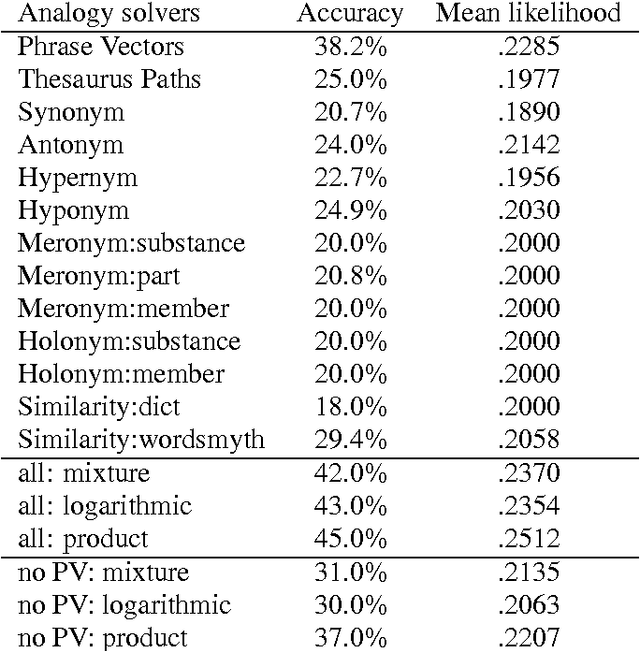
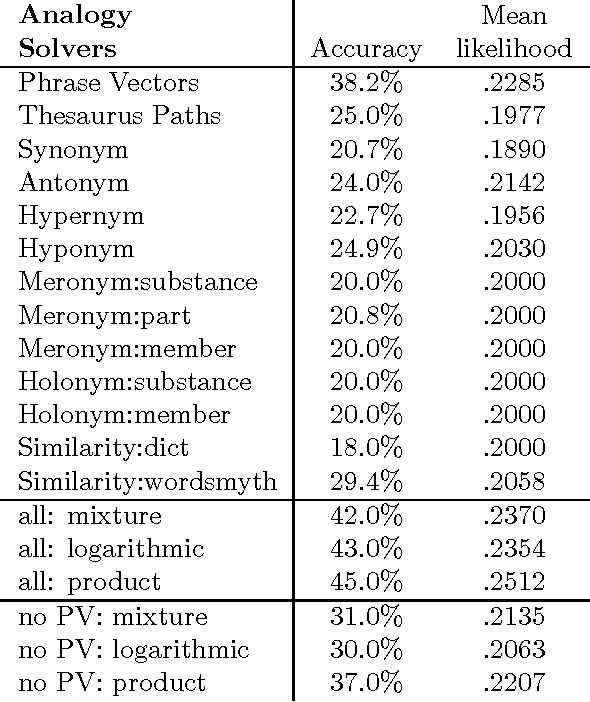
Existing statistical approaches to natural language problems are very coarse approximations to the true complexity of language processing. As such, no single technique will be best for all problem instances. Many researchers are examining ensemble methods that combine the output of multiple modules to create more accurate solutions. This paper examines three merging rules for combining probability distributions: the familiar mixture rule, the logarithmic rule, and a novel product rule. These rules were applied with state-of-the-art results to two problems used to assess human mastery of lexical semantics -- synonym questions and analogy questions. All three merging rules result in ensembles that are more accurate than any of their component modules. The differences among the three rules are not statistically significant, but it is suggestive that the popular mixture rule is not the best rule for either of the two problems.
* 10 pages, related work available at http://www.cs.rutgers.edu/~mlittman/ and http://purl.org/peter.turney/
Combining Independent Modules to Solve Multiple-choice Synonym and Analogy Problems
Sep 19, 2003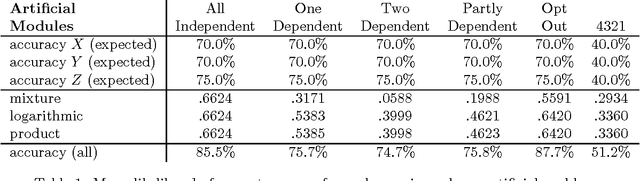

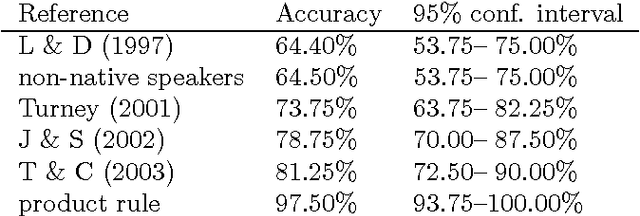
Existing statistical approaches to natural language problems are very coarse approximations to the true complexity of language processing. As such, no single technique will be best for all problem instances. Many researchers are examining ensemble methods that combine the output of successful, separately developed modules to create more accurate solutions. This paper examines three merging rules for combining probability distributions: the well known mixture rule, the logarithmic rule, and a novel product rule. These rules were applied with state-of-the-art results to two problems commonly used to assess human mastery of lexical semantics -- synonym questions and analogy questions. All three merging rules result in ensembles that are more accurate than any of their component modules. The differences among the three rules are not statistically significant, but it is suggestive that the popular mixture rule is not the best rule for either of the two problems.
* 8 pages, related work available at http://www.cs.rutgers.edu/~mlittman/ and http://purl.org/peter.turney/