 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding the Effectiveness of Very Large Language Models on Dialog Evaluation
Jan 27, 2023



Language models have steadily increased in size over the past few years. They achieve a high level of performance on various natural language processing (NLP) tasks such as question answering and summarization. Large language models (LLMs) have been used for generation and can now output human-like text. Due to this, there are other downstream tasks in the realm of dialog that can now harness the LLMs' language understanding capabilities. Dialog evaluation is one task that this paper will explore. It concentrates on prompting with LLMs: BLOOM, OPT, GPT-3, Flan-T5, InstructDial and TNLGv2. The paper shows that the choice of datasets used for training a model contributes to how well it performs on a task as well as on how the prompt should be structured. Specifically, the more diverse and relevant the group of datasets that a model is trained on, the better dialog evaluation performs. This paper also investigates how the number of examples in the prompt and the type of example selection used affect the model's performance.
The DialPort tools
Aug 18, 2022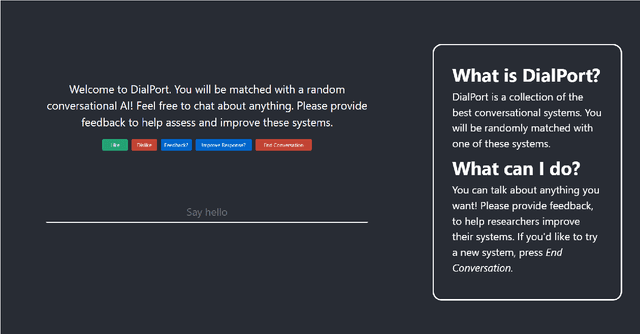
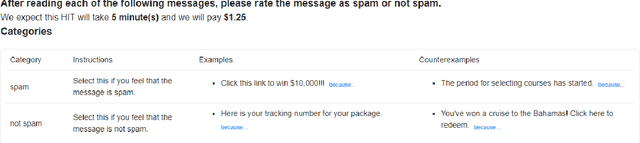
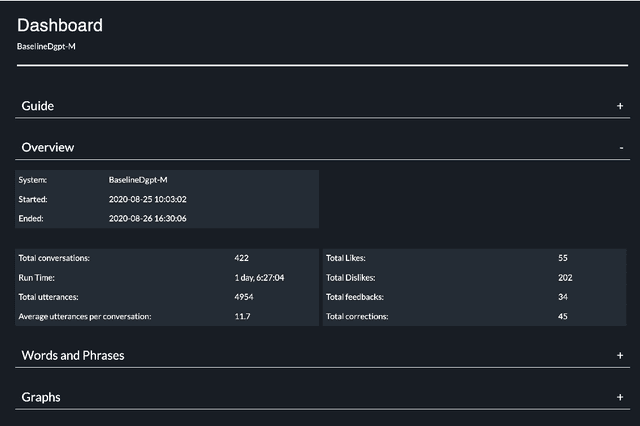
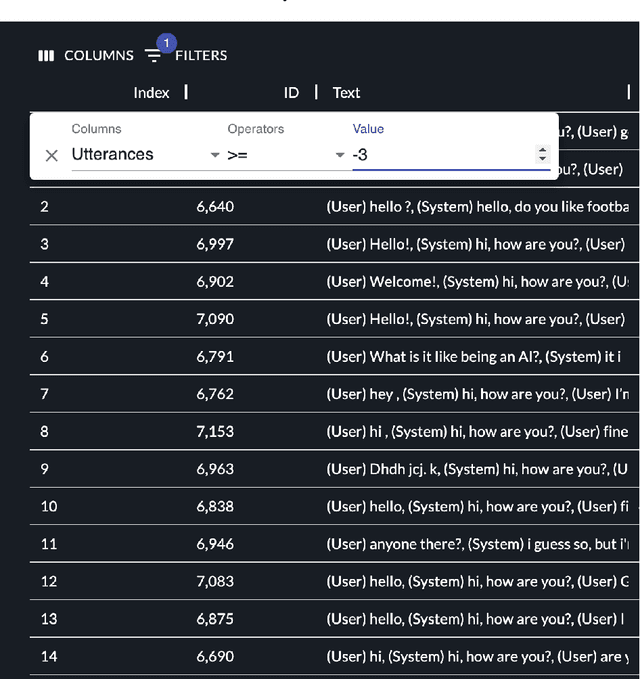
The DialPort project http://dialport.org/, funded by the National Science Foundation (NSF), covers a group of tools and services that aim at fulfilling the needs of the dialog research community. Over the course of six years, several offerings have been created, including the DialPort Portal and DialCrowd. This paper describes these contributions, which will be demoed at SIGDIAL, including implementation, prior studies, corresponding discoveries, and the locations at which the tools will remain freely available to the community going forward.
Interactive Evaluation of Dialog Track at DSTC9
Jul 28, 2022
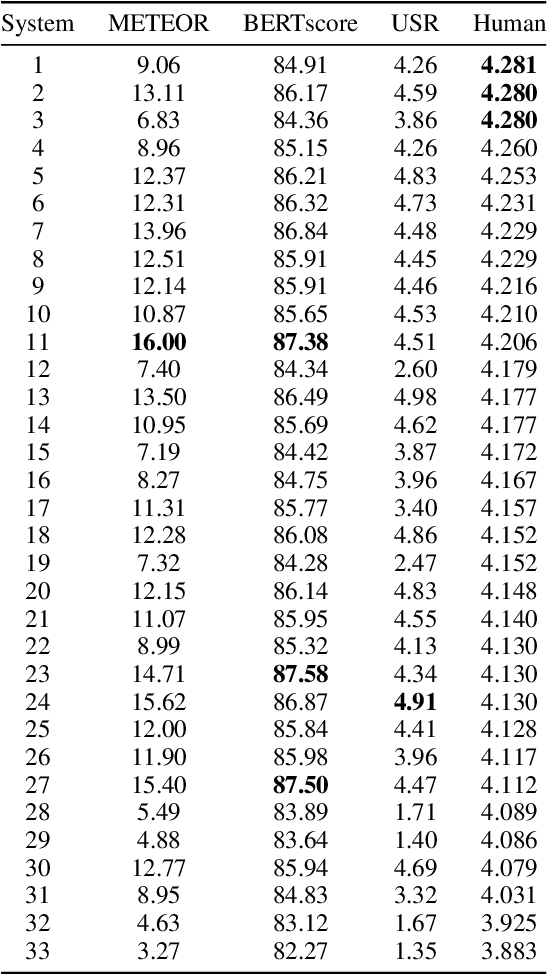
The ultimate goal of dialog research is to develop systems that can be effectively used in interactive settings by real users. To this end, we introduced the Interactive Evaluation of Dialog Track at the 9th Dialog System Technology Challenge. This track consisted of two sub-tasks. The first sub-task involved building knowledge-grounded response generation models. The second sub-task aimed to extend dialog models beyond static datasets by assessing them in an interactive setting with real users. Our track challenges participants to develop strong response generation models and explore strategies that extend them to back-and-forth interactions with real users. The progression from static corpora to interactive evaluation introduces unique challenges and facilitates a more thorough assessment of open-domain dialog systems. This paper provides an overview of the track, including the methodology and results. Furthermore, it provides insights into how to best evaluate open-domain dialog models
LAD: Language Models as Data for Zero-Shot Dialog
Jul 28, 2022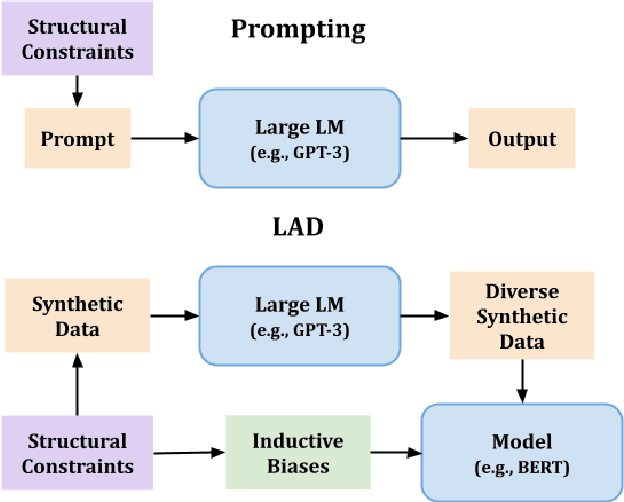
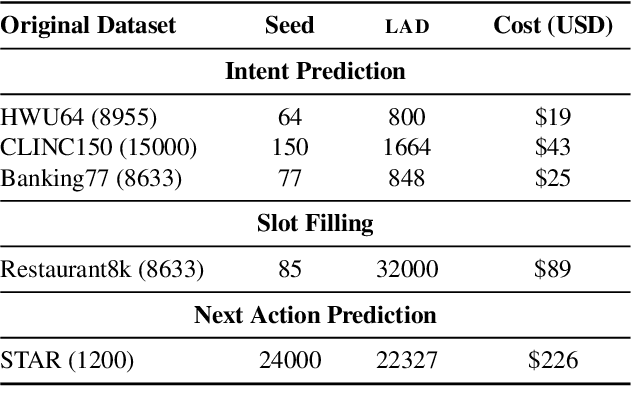
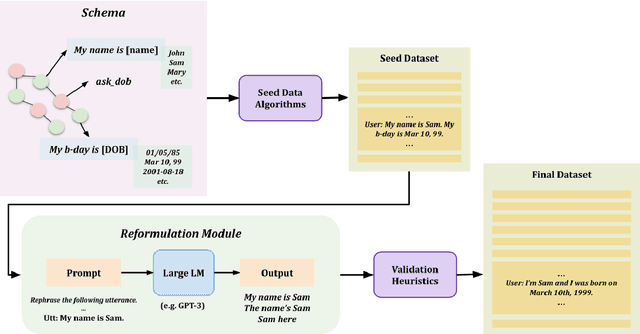

To facilitate zero-shot generalization in taskoriented dialog, this paper proposes Language Models as Data (LAD). LAD is a paradigm for creating diverse and accurate synthetic data which conveys the necessary structural constraints and can be used to train a downstream neural dialog model. LAD leverages GPT-3 to induce linguistic diversity. LAD achieves significant performance gains in zero-shot settings on intent prediction (+15%), slot filling (+31.4 F-1) and next action prediction (+11 F1). Furthermore, an interactive human evaluation shows that training with LAD is competitive with training on human dialogs. LAD is open-sourced, with the code and data available at https://github.com/Shikib/lad.
DialCrowd 2.0: A Quality-Focused Dialog System Crowdsourcing Toolkit
Jul 25, 2022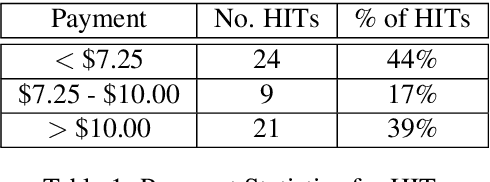
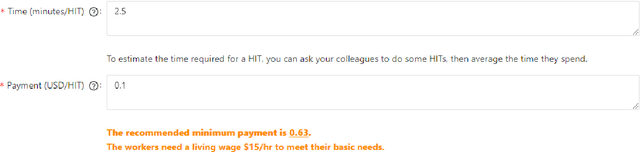
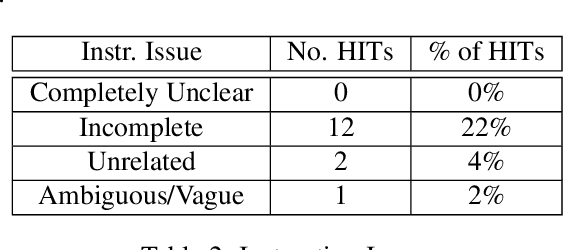
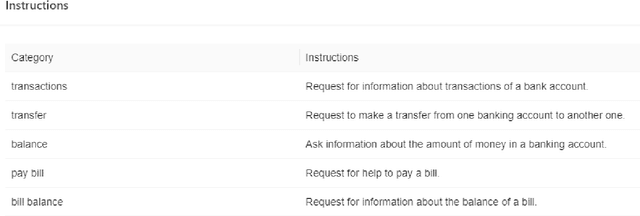
Dialog system developers need high-quality data to train, fine-tune and assess their systems. They often use crowdsourcing for this since it provides large quantities of data from many workers. However, the data may not be of sufficiently good quality. This can be due to the way that the requester presents a task and how they interact with the workers. This paper introduces DialCrowd 2.0 to help requesters obtain higher quality data by, for example, presenting tasks more clearly and facilitating effective communication with workers. DialCrowd 2.0 guides developers in creating improved Human Intelligence Tasks (HITs) and is directly applicable to the workflows used currently by developers and researchers.
Improving Zero and Few-shot Generalization in Dialogue through Instruction Tuning
May 25, 2022
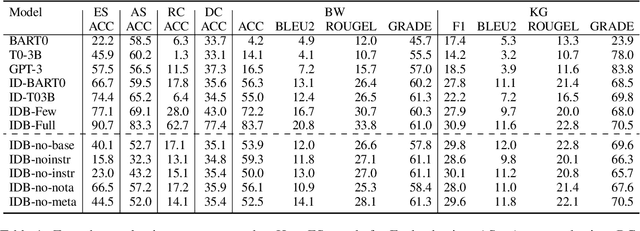
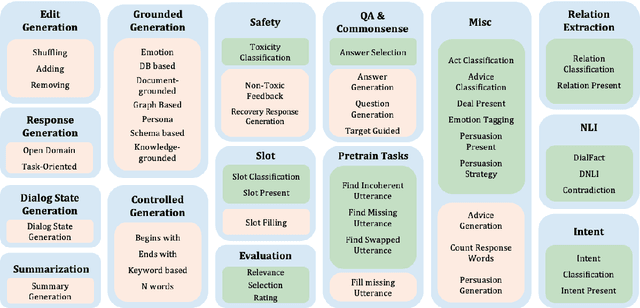
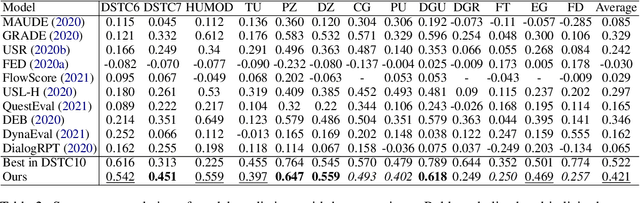
Instruction tuning is an emergent paradigm in NLP wherein natural language instructions are leveraged with language models to induce zero-shot performance on unseen tasks. Instructions have been shown to enable good performance on unseen tasks and datasets in both large and small language models. Dialogue is an especially interesting area to explore instruction tuning because dialogue systems perform multiple kinds of tasks related to language (e.g., natural language understanding and generation, domain-specific interaction), yet instruction tuning has not been systematically explored for dialogue-related tasks. We introduce InstructDial, an instruction tuning framework for dialogue, which consists of a repository of 48 diverse dialogue tasks in a unified text-to-text format created from 59 openly available dialogue datasets. Next, we explore cross-task generalization ability on models tuned on InstructDial across diverse dialogue tasks. Our analysis reveals that InstructDial enables good zero-shot performance on unseen datasets and tasks such as dialogue evaluation and intent detection, and even better performance in a few-shot setting. To ensure that models adhere to instructions, we introduce novel meta-tasks. We establish benchmark zero-shot and few-shot performance of models trained using the proposed framework on multiple dialogue tasks.
Report from the NSF Future Directions Workshop on Automatic Evaluation of Dialog: Research Directions and Challenges
Mar 18, 2022

This is a report on the NSF Future Directions Workshop on Automatic Evaluation of Dialog. The workshop explored the current state of the art along with its limitations and suggested promising directions for future work in this important and very rapidly changing area of research.
A Survey of NLP-Related Crowdsourcing HITs: what works and what does not
Nov 09, 2021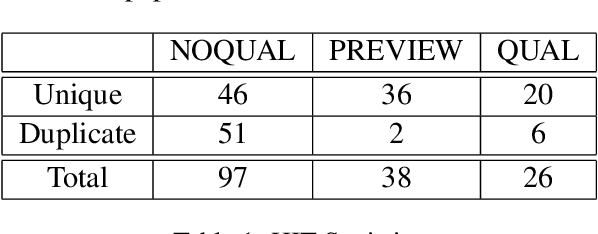
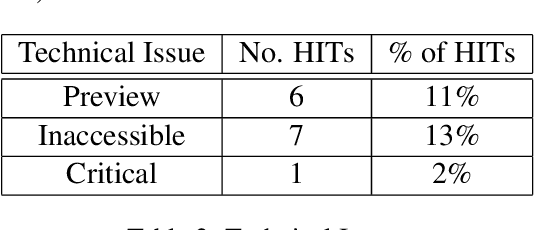

Crowdsourcing requesters on Amazon Mechanical Turk (AMT) have raised questions about the reliability of the workers. The AMT workforce is very diverse and it is not possible to make blanket assumptions about them as a group. Some requesters now reject work en mass when they do not get the results they expect. This has the effect of giving each worker (good or bad) a lower Human Intelligence Task (HIT) approval score, which is unfair to the good workers. It also has the effect of giving the requester a bad reputation on the workers' forums. Some of the issues causing the mass rejections stem from the requesters not taking the time to create a well-formed task with complete instructions and/or not paying a fair wage. To explore this assumption, this paper describes a study that looks at the crowdsourcing HITs on AMT that were available over a given span of time and records information about those HITs. This study also records information from a crowdsourcing forum on the worker perspective on both those HITs and on their corresponding requesters. Results reveal issues in worker payment and presentation issues such as missing instructions or HITs that are not doable.
A Comprehensive Assessment of Dialog Evaluation Metrics
Jun 30, 2021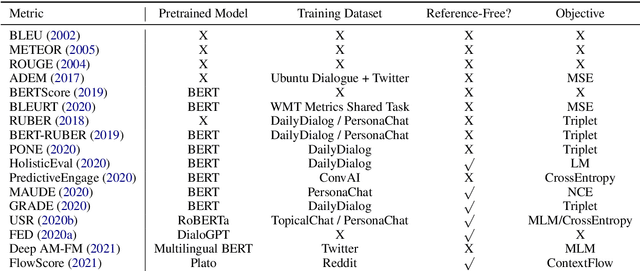
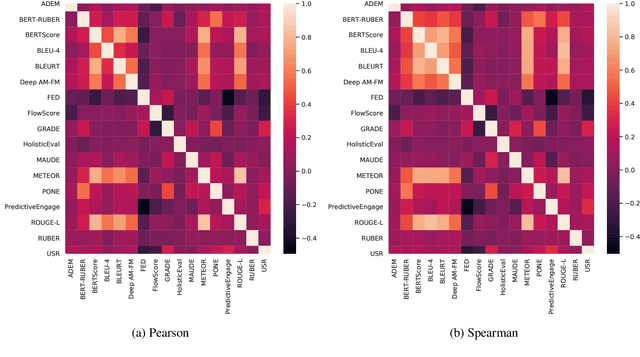

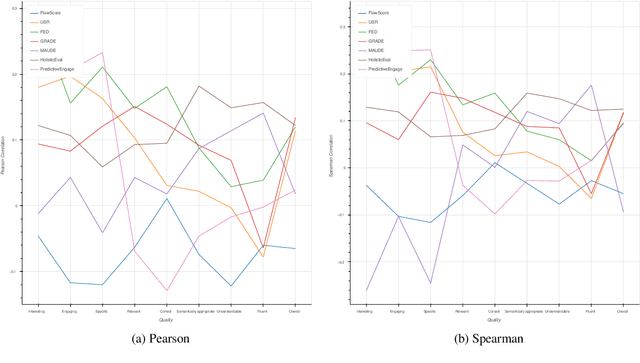
Automatic evaluation metrics are a crucial component of dialog systems research. Standard language evaluation metrics are known to be ineffective for evaluating dialog. As such, recent research has proposed a number of novel, dialog-specific metrics that correlate better with human judgements. Due to the fast pace of research, many of these metrics have been assessed on different datasets and there has as yet been no time for a systematic comparison between them. To this end, this paper provides a comprehensive assessment of recently proposed dialog evaluation metrics on a number of datasets. In this paper, 17 different automatic evaluation metrics are evaluated on 10 different datasets. Furthermore, the metrics are assessed in different settings, to better qualify their respective strengths and weaknesses. Metrics are assessed (1) on both the turn level and the dialog level, (2) for different dialog lengths, (3) for different dialog qualities (e.g., coherence, engaging), (4) for different types of response generation models (i.e., generative, retrieval, simple models and state-of-the-art models), (5) taking into account the similarity of different metrics and (6) exploring combinations of different metrics. This comprehensive assessment offers several takeaways pertaining to dialog evaluation metrics in general. It also suggests how to best assess evaluation metrics and indicates promising directions for future work.
Schema-Guided Paradigm for Zero-Shot Dialog
Jun 13, 2021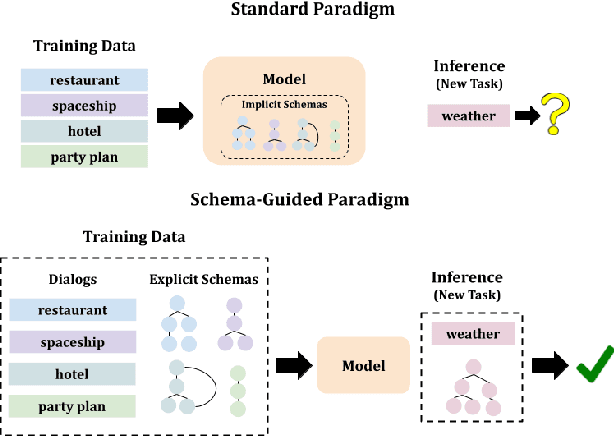



Developing mechanisms that flexibly adapt dialog systems to unseen tasks and domains is a major challenge in dialog research. Neural models implicitly memorize task-specific dialog policies from the training data. We posit that this implicit memorization has precluded zero-shot transfer learning. To this end, we leverage the schema-guided paradigm, wherein the task-specific dialog policy is explicitly provided to the model. We introduce the Schema Attention Model (SAM) and improved schema representations for the STAR corpus. SAM obtains significant improvement in zero-shot settings, with a +22 F1 score improvement over prior work. These results validate the feasibility of zero-shot generalizability in dialog. Ablation experiments are also presented to demonstrate the efficacy of SAM.