 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Evaluation in Retrieval-Augmented Personalized Dialogue: A Cognitive and Linguistic Perspective
Mar 15, 2026In cognitive science and linguistic theory, dialogue is not seen as a chain of independent utterances but rather as a joint activity sustained by coherence, consistency, and shared understanding. However, many systems for open-domain and personalized dialogue use surface-level similarity metrics (e.g., BLEU, ROUGE, F1) as one of their main reporting measures, which fail to capture these deeper aspects of conversational quality. We re-examine a notable retrieval-augmented framework for personalized dialogue, LAPDOG, as a case study for evaluation methodology. Using both human and LLM-based judges, we identify limitations in current evaluation practices, including corrupted dialogue histories, contradictions between retrieved stories and persona, and incoherent response generation. Our results show that human and LLM judgments align closely but diverge from lexical similarity metrics, underscoring the need for cognitively grounded evaluation methods. Broadly, this work charts a path toward more reliable assessment frameworks for retrieval-augmented dialogue systems that better reflect the principles of natural human communication.
* Accepted to LREC 2026
Human-Robot Dialogue Annotation for Multi-Modal Common Ground
Nov 19, 2024In this paper, we describe the development of symbolic representations annotated on human-robot dialogue data to make dimensions of meaning accessible to autonomous systems participating in collaborative, natural language dialogue, and to enable common ground with human partners. A particular challenge for establishing common ground arises in remote dialogue (occurring in disaster relief or search-and-rescue tasks), where a human and robot are engaged in a joint navigation and exploration task of an unfamiliar environment, but where the robot cannot immediately share high quality visual information due to limited communication constraints. Engaging in a dialogue provides an effective way to communicate, while on-demand or lower-quality visual information can be supplemented for establishing common ground. Within this paradigm, we capture propositional semantics and the illocutionary force of a single utterance within the dialogue through our Dialogue-AMR annotation, an augmentation of Abstract Meaning Representation. We then capture patterns in how different utterances within and across speaker floors relate to one another in our development of a multi-floor Dialogue Structure annotation schema. Finally, we begin to annotate and analyze the ways in which the visual modalities provide contextual information to the dialogue for overcoming disparities in the collaborators' understanding of the environment. We conclude by discussing the use-cases, architectures, and systems we have implemented from our annotations that enable physical robots to autonomously engage with humans in bi-directional dialogue and navigation.
* 52 pages, 14 figures
SCOUT: A Situated and Multi-Modal Human-Robot Dialogue Corpus
Nov 19, 2024



We introduce the Situated Corpus Of Understanding Transactions (SCOUT), a multi-modal collection of human-robot dialogue in the task domain of collaborative exploration. The corpus was constructed from multiple Wizard-of-Oz experiments where human participants gave verbal instructions to a remotely-located robot to move and gather information about its surroundings. SCOUT contains 89,056 utterances and 310,095 words from 278 dialogues averaging 320 utterances per dialogue. The dialogues are aligned with the multi-modal data streams available during the experiments: 5,785 images and 30 maps. The corpus has been annotated with Abstract Meaning Representation and Dialogue-AMR to identify the speaker's intent and meaning within an utterance, and with Transactional Units and Relations to track relationships between utterances to reveal patterns of the Dialogue Structure. We describe how the corpus and its annotations have been used to develop autonomous human-robot systems and enable research in open questions of how humans speak to robots. We release this corpus to accelerate progress in autonomous, situated, human-robot dialogue, especially in the context of navigation tasks where details about the environment need to be discovered.
* 14 pages, 7 figures
TwoStep: Multi-agent Task Planning using Classical Planners and Large Language Models
Mar 25, 2024
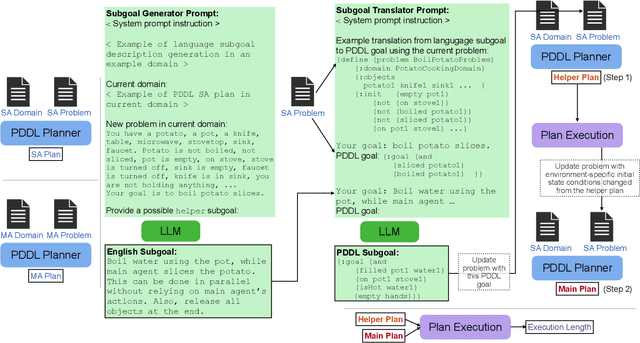


Classical planning formulations like the Planning Domain Definition Language (PDDL) admit action sequences guaranteed to achieve a goal state given an initial state if any are possible. However, reasoning problems defined in PDDL do not capture temporal aspects of action taking, for example that two agents in the domain can execute an action simultaneously if postconditions of each do not interfere with preconditions of the other. A human expert can decompose a goal into largely independent constituent parts and assign each agent to one of these subgoals to take advantage of simultaneous actions for faster execution of plan steps, each using only single agent planning. By contrast, large language models (LLMs) used for directly inferring plan steps do not guarantee execution success, but do leverage commonsense reasoning to assemble action sequences. We combine the strengths of classical planning and LLMs by approximating human intuitions for two-agent planning goal decomposition. We demonstrate that LLM-based goal decomposition leads to faster planning times than solving multi-agent PDDL problems directly while simultaneously achieving fewer plan execution steps than a single agent plan alone and preserving execution success. Additionally, we find that LLM-based approximations of subgoals can achieve similar multi-agent execution steps than those specified by human experts. Website and resources at https://glamor-usc.github.io/twostep
Navigating to Success in Multi-Modal Human-Robot Collaboration: Analysis and Corpus Release
Oct 26, 2023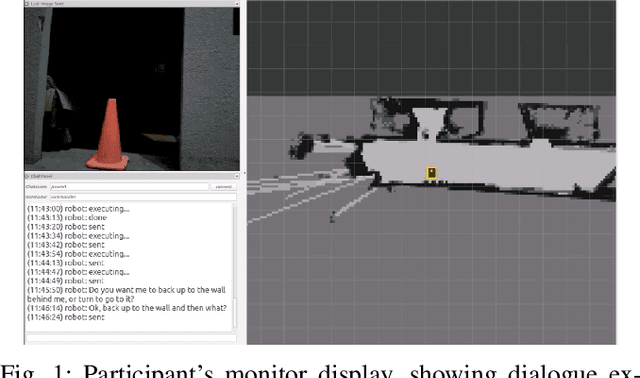
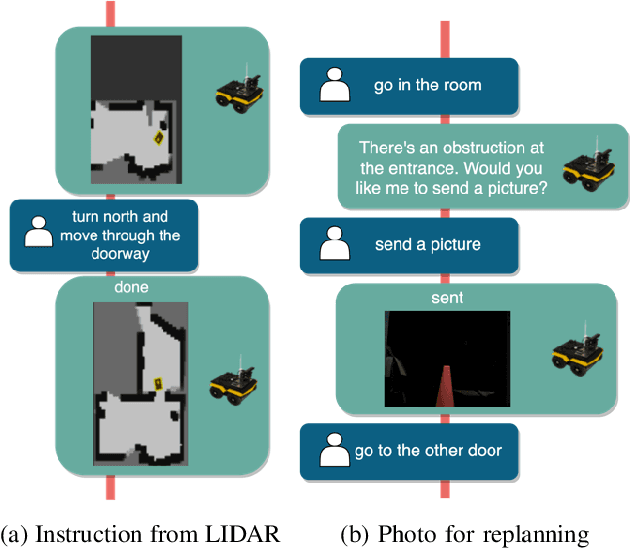
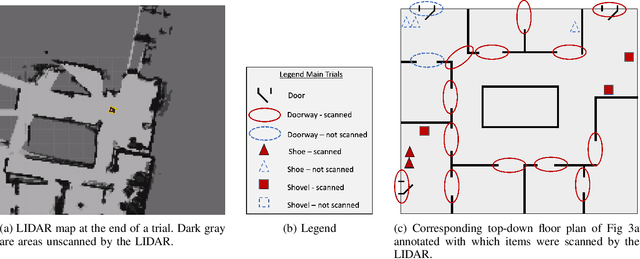
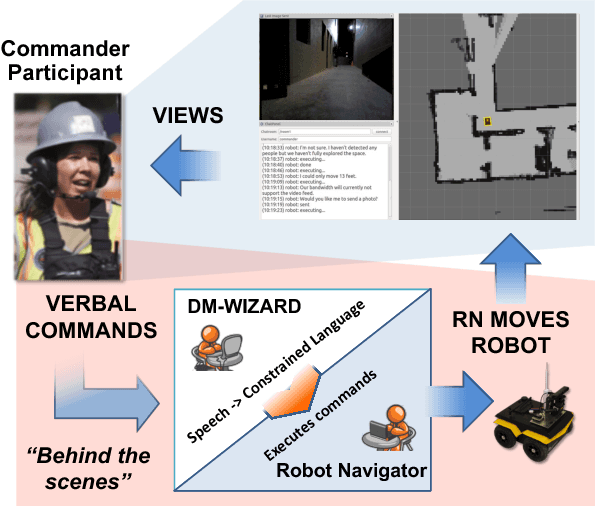
Human-guided robotic exploration is a useful approach to gathering information at remote locations, especially those that might be too risky, inhospitable, or inaccessible for humans. Maintaining common ground between the remotely-located partners is a challenge, one that can be facilitated by multi-modal communication. In this paper, we explore how participants utilized multiple modalities to investigate a remote location with the help of a robotic partner. Participants issued spoken natural language instructions and received from the robot: text-based feedback, continuous 2D LIDAR mapping, and upon-request static photographs. We noticed that different strategies were adopted in terms of use of the modalities, and hypothesize that these differences may be correlated with success at several exploration sub-tasks. We found that requesting photos may have improved the identification and counting of some key entities (doorways in particular) and that this strategy did not hinder the amount of overall area exploration. Future work with larger samples may reveal the effects of more nuanced photo and dialogue strategies, which can inform the training of robotic agents. Additionally, we announce the release of our unique multi-modal corpus of human-robot communication in an exploration context: SCOUT, the Situated Corpus on Understanding Transactions.
* 7 pages, 3 figures
Interactive Evaluation of Dialog Track at DSTC9
Jul 28, 2022
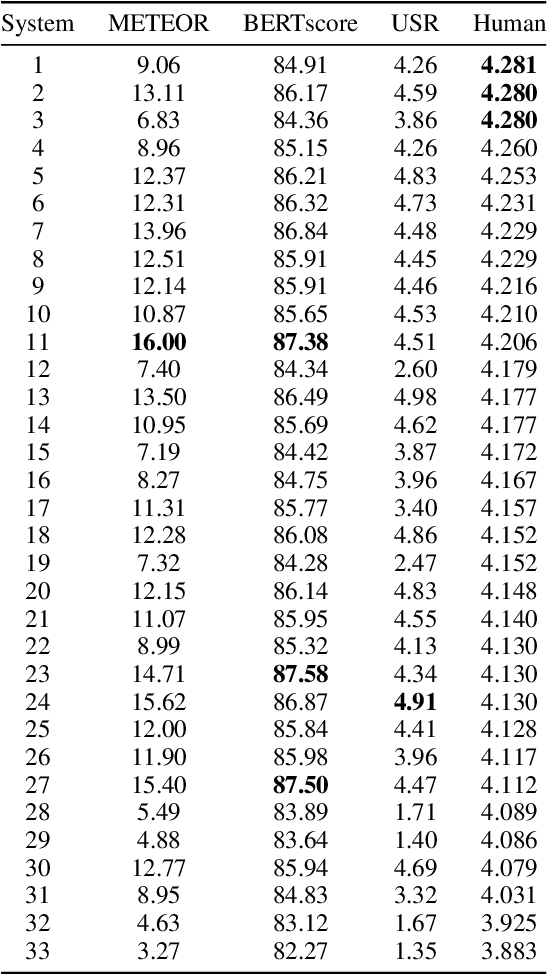
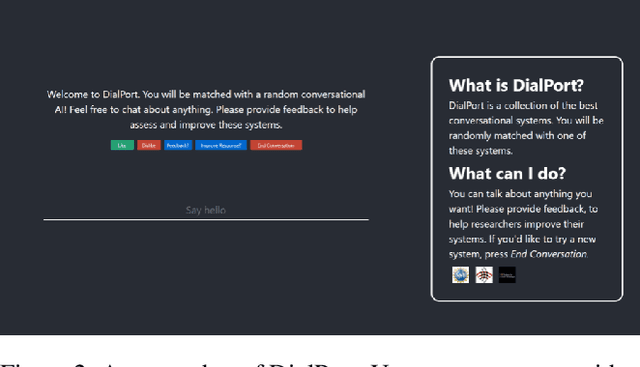
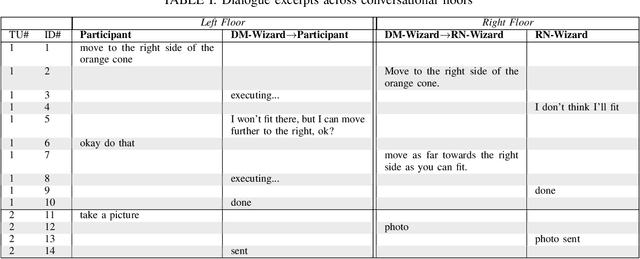
The ultimate goal of dialog research is to develop systems that can be effectively used in interactive settings by real users. To this end, we introduced the Interactive Evaluation of Dialog Track at the 9th Dialog System Technology Challenge. This track consisted of two sub-tasks. The first sub-task involved building knowledge-grounded response generation models. The second sub-task aimed to extend dialog models beyond static datasets by assessing them in an interactive setting with real users. Our track challenges participants to develop strong response generation models and explore strategies that extend them to back-and-forth interactions with real users. The progression from static corpora to interactive evaluation introduces unique challenges and facilitates a more thorough assessment of open-domain dialog systems. This paper provides an overview of the track, including the methodology and results. Furthermore, it provides insights into how to best evaluate open-domain dialog models
Report from the NSF Future Directions Workshop on Automatic Evaluation of Dialog: Research Directions and Challenges
Mar 18, 2022

This is a report on the NSF Future Directions Workshop on Automatic Evaluation of Dialog. The workshop explored the current state of the art along with its limitations and suggested promising directions for future work in this important and very rapidly changing area of research.
Overview of the Ninth Dialog System Technology Challenge: DSTC9
Nov 12, 2020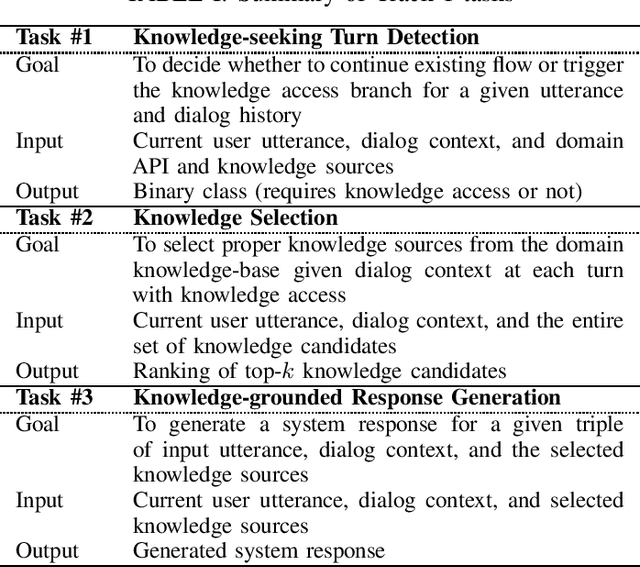

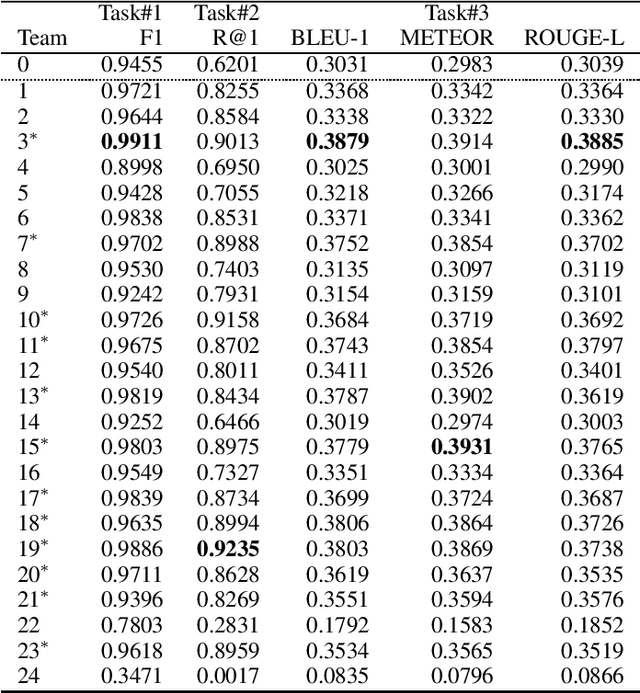
This paper introduces the Ninth Dialog System Technology Challenge (DSTC-9). This edition of the DSTC focuses on applying end-to-end dialog technologies for four distinct tasks in dialog systems, namely, 1. Task-oriented dialog Modeling with unstructured knowledge access, 2. Multi-domain task-oriented dialog, 3. Interactive evaluation of dialog, and 4. Situated interactive multi-modal dialog. This paper describes the task definition, provided datasets, baselines and evaluation set-up for each track. We also summarize the results of the submitted systems to highlight the overall trends of the state-of-the-art technologies for the tasks.
Balancing Efficiency and Coverage in Human-Robot Dialogue Collection
Oct 07, 2018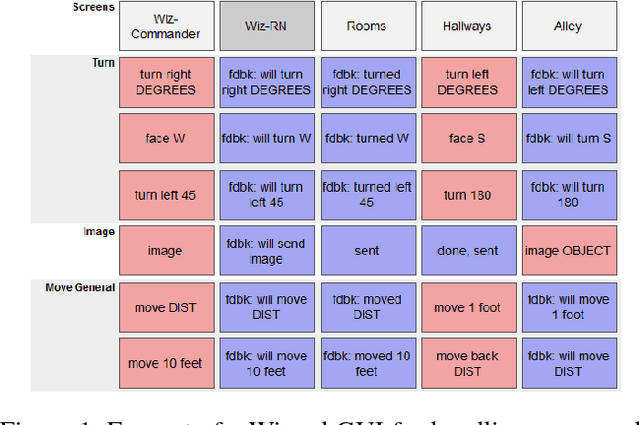
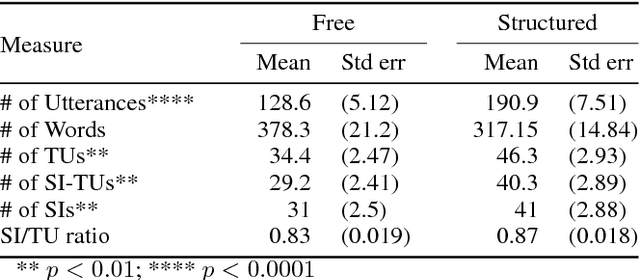
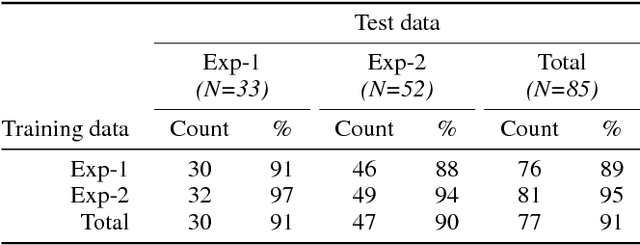
We describe a multi-phased Wizard-of-Oz approach to collecting human-robot dialogue in a collaborative search and navigation task. The data is being used to train an initial automated robot dialogue system to support collaborative exploration tasks. In the first phase, a wizard freely typed robot utterances to human participants. For the second phase, this data was used to design a GUI that includes buttons for the most common communications, and templates for communications with varying parameters. Comparison of the data gathered in these phases show that the GUI enabled a faster pace of dialogue while still maintaining high coverage of suitable responses, enabling more efficient targeted data collection, and improvements in natural language understanding using GUI-collected data. As a promising first step towards interactive learning, this work shows that our approach enables the collection of useful training data for navigation-based HRI tasks.
Consequences and Factors of Stylistic Differences in Human-Robot Dialogue
Jul 21, 2018

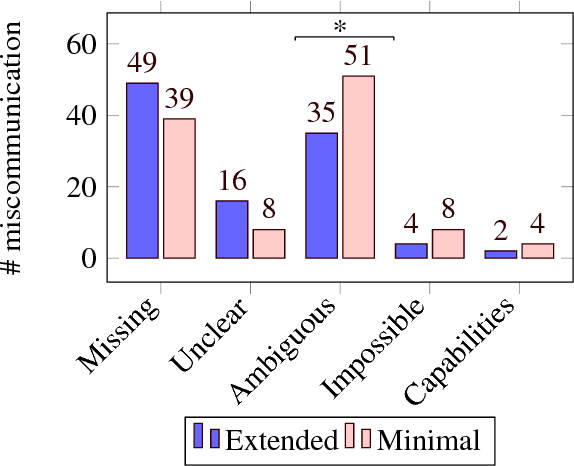
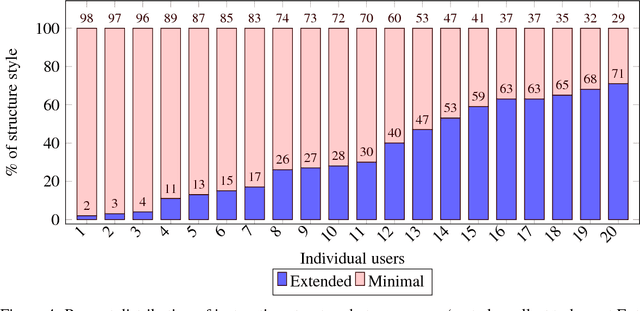
This paper identifies stylistic differences in instruction-giving observed in a corpus of human-robot dialogue. Differences in verbosity and structure (i.e., single-intent vs. multi-intent instructions) arose naturally without restrictions or prior guidance on how users should speak with the robot. Different styles were found to produce different rates of miscommunication, and correlations were found between style differences and individual user variation, trust, and interaction experience with the robot. Understanding potential consequences and factors that influence style can inform design of dialogue systems that are robust to natural variation from human users.