 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Sentence Knowledge Selection in Open-Domain Dialogue
Mar 01, 2022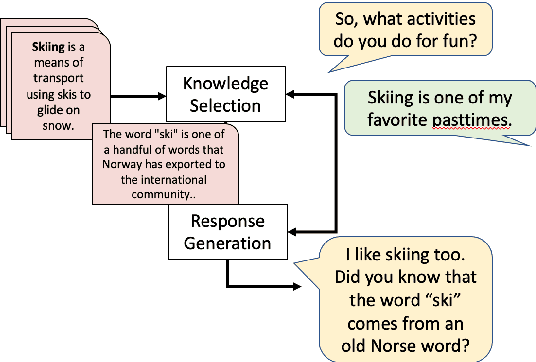



Incorporating external knowledge sources effectively in conversations is a longstanding problem in open-domain dialogue research. The existing literature on open-domain knowledge selection is limited and makes certain brittle assumptions on knowledge sources to simplify the overall task (Dinan et al., 2019), such as the existence of a single relevant knowledge sentence per context. In this work, we evaluate the existing state of open-domain conversation knowledge selection, showing where the existing methodologies regarding data and evaluation are flawed. We then improve on them by proposing a new framework for collecting relevant knowledge, and create an augmented dataset based on the Wizard of Wikipedia (WOW) corpus, which we call WOW++. WOW++ averages 8 relevant knowledge sentences per dialogue context, embracing the inherent ambiguity of open-domain dialogue knowledge selection. We then benchmark various knowledge ranking algorithms on this augmented dataset with both intrinsic evaluation and extrinsic measures of response quality, showing that neural rerankers that use WOW++ can outperform rankers trained on standard datasets.
Beyond Domain APIs: Task-oriented Conversational Modeling with Unstructured Knowledge Access Track in DSTC9
Feb 04, 2021
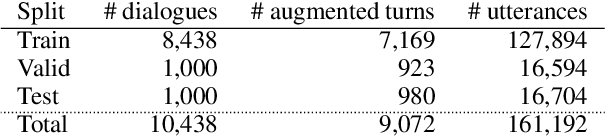
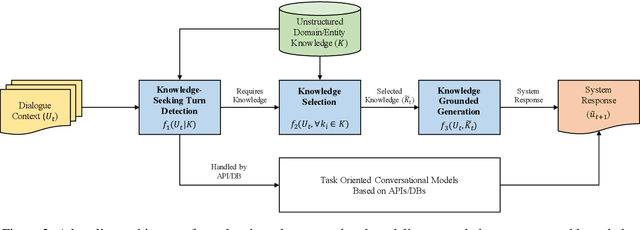

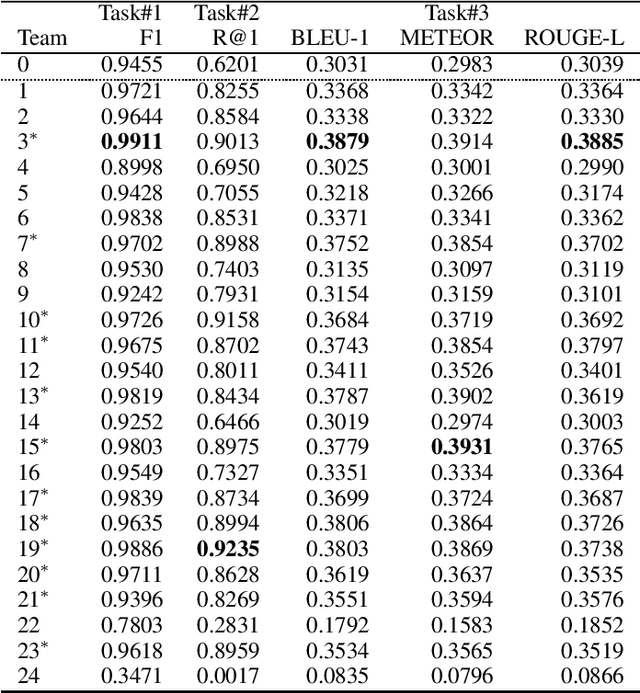
Most prior work on task-oriented dialogue systems are restricted to a limited coverage of domain APIs, while users oftentimes have domain related requests that are not covered by the APIs. This challenge track aims to expand the coverage of task-oriented dialogue systems by incorporating external unstructured knowledge sources. We define three tasks: knowledge-seeking turn detection, knowledge selection, and knowledge-grounded response generation. We introduce the data sets and the neural baseline models for three tasks. The challenge track received a total of 105 entries from 24 participating teams. In the evaluation results, the ensemble methods with different large-scale pretrained language models achieved high performances with improved knowledge selection capability and better generalization into unseen data.
Overview of the Ninth Dialog System Technology Challenge: DSTC9
Nov 12, 2020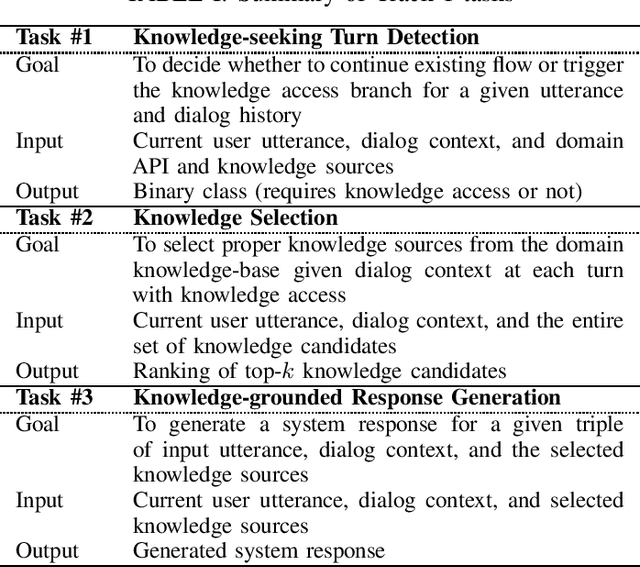
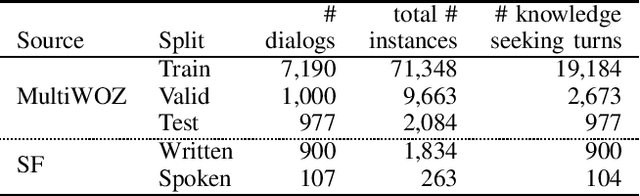

This paper introduces the Ninth Dialog System Technology Challenge (DSTC-9). This edition of the DSTC focuses on applying end-to-end dialog technologies for four distinct tasks in dialog systems, namely, 1. Task-oriented dialog Modeling with unstructured knowledge access, 2. Multi-domain task-oriented dialog, 3. Interactive evaluation of dialog, and 4. Situated interactive multi-modal dialog. This paper describes the task definition, provided datasets, baselines and evaluation set-up for each track. We also summarize the results of the submitted systems to highlight the overall trends of the state-of-the-art technologies for the tasks.
Example-Driven Intent Prediction with Observers
Oct 17, 2020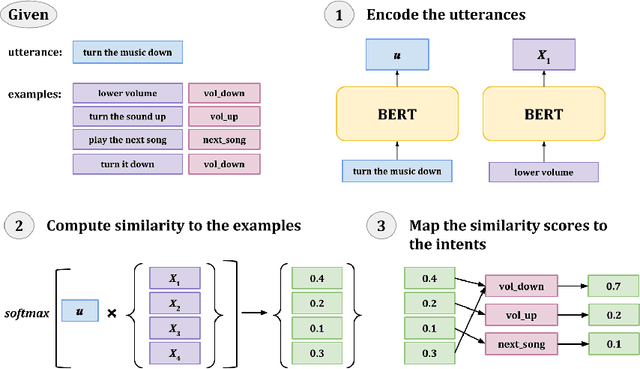
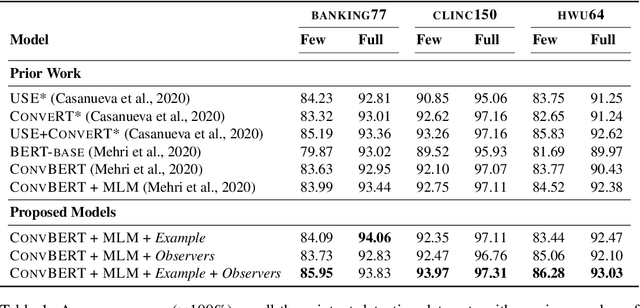
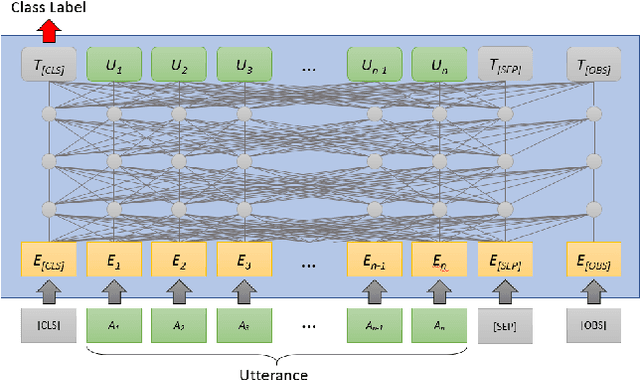

A key challenge of dialog systems research is to effectively and efficiently adapt to new domains. A scalable paradigm for adaptation necessitates the development of generalizable models that perform well in few-shot settings. In this paper, we focus on the intent classification problem which aims to identify user intents given utterances addressed to the dialog system. We propose two approaches for improving the generalizability of utterance classification models: (1) example-driven training and (2) observers. Example-driven training learns to classify utterances by comparing to examples, thereby using the underlying encoder as a sentence similarity model. Prior work has shown that BERT-like models tend to attribute a significant amount of attention to the [CLS] token, which we hypothesize results in diluted representations. Observers are tokens that are not attended to, and are an alternative to the [CLS] token. The proposed methods attain state-of-the-art results on three intent prediction datasets (Banking, Clinc}, and HWU) in both the full data and few-shot (10 examples per intent) settings. Furthermore, we demonstrate that the proposed approach can transfer to new intents and across datasets without any additional training.
DialoGLUE: A Natural Language Understanding Benchmark for Task-Oriented Dialogue
Oct 01, 2020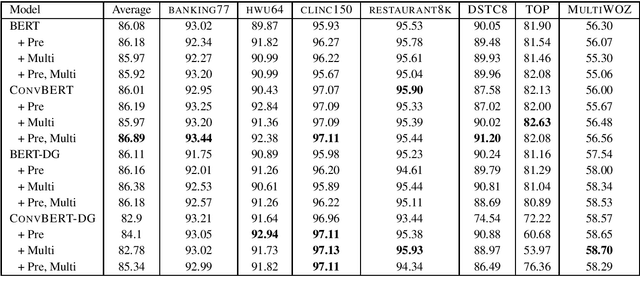
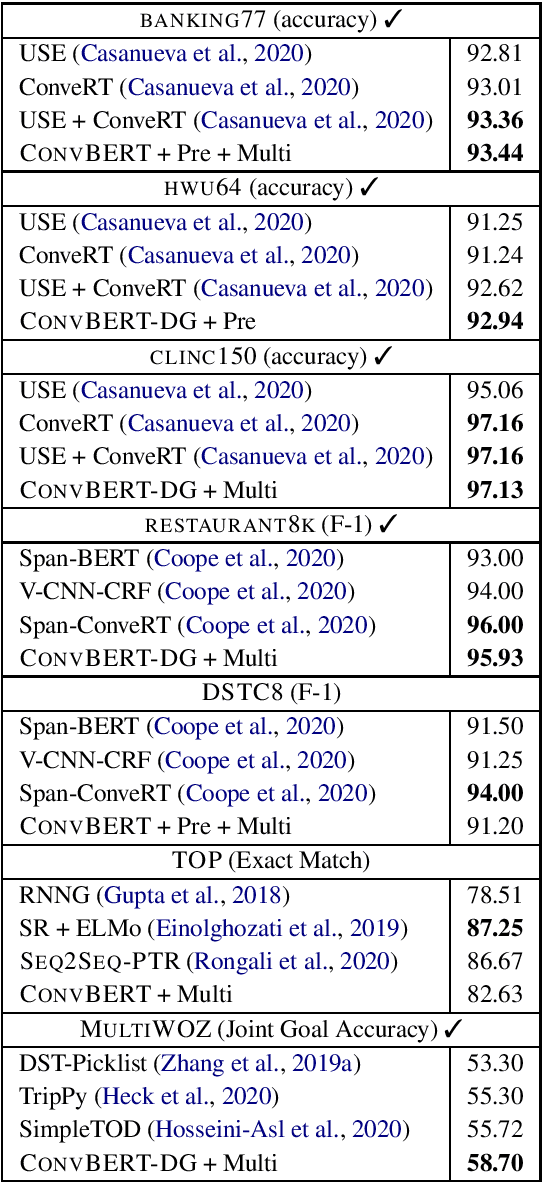
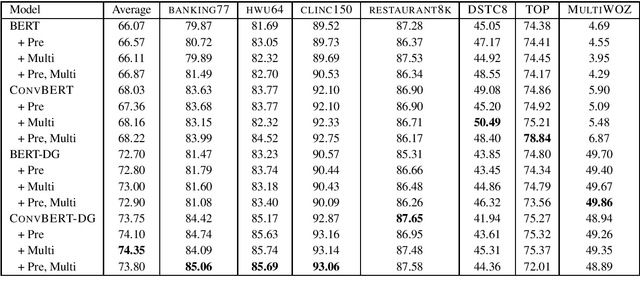
A long-standing goal of task-oriented dialogue research is the ability to flexibly adapt dialogue models to new domains. To progress research in this direction, we introduce DialoGLUE (Dialogue Language Understanding Evaluation), a public benchmark consisting of 7 task-oriented dialogue datasets covering 4 distinct natural language understanding tasks, designed to encourage dialogue research in representation-based transfer, domain adaptation, and sample-efficient task learning. We release several strong baseline models, demonstrating performance improvements over a vanilla BERT architecture and state-of-the-art results on 5 out of 7 tasks, by pre-training on a large open-domain dialogue corpus and task-adaptive self-supervised training. Through the DialoGLUE benchmark, the baseline methods, and our evaluation scripts, we hope to facilitate progress towards the goal of developing more general task-oriented dialogue models.
Policy-Driven Neural Response Generation for Knowledge-Grounded Dialogue Systems
Jun 09, 2020
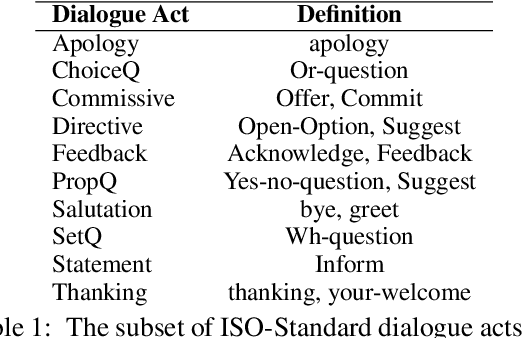
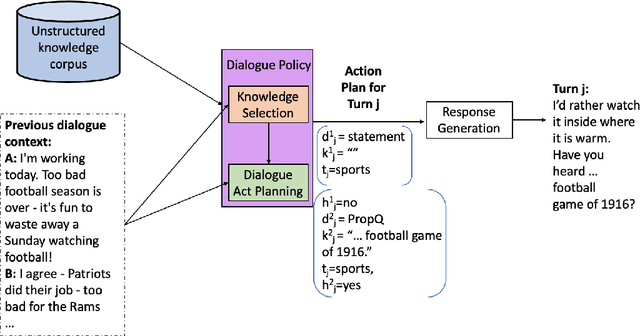
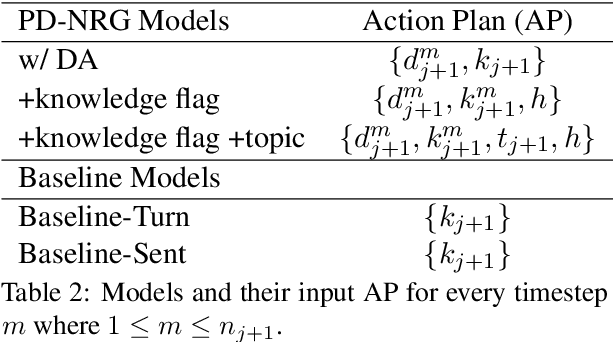
Open-domain dialogue systems aim to generate relevant, informative and engaging responses. Seq2seq neural response generation approaches do not have explicit mechanisms to control the content or style of the generated response, and frequently result in uninformative utterances. In this paper, we propose using a dialogue policy to plan the content and style of target responses in the form of an action plan, which includes knowledge sentences related to the dialogue context, targeted dialogue acts, topic information, etc. The attributes within the action plan are obtained by automatically annotating the publicly released Topical-Chat dataset. We condition neural response generators on the action plan which is then realized as target utterances at the turn and sentence levels. We also investigate different dialogue policy models to predict an action plan given the dialogue context. Through automated and human evaluation, we measure the appropriateness of the generated responses and check if the generation models indeed learn to realize the given action plans. We demonstrate that a basic dialogue policy that operates at the sentence level generates better responses in comparison to turn level generation as well as baseline models with no action plan. Additionally the basic dialogue policy has the added effect of controllability.
Beyond Domain APIs: Task-oriented Conversational Modeling with Unstructured Knowledge Access
Jun 05, 2020Most prior work on task-oriented dialogue systems are restricted to a limited coverage of domain APIs, while users oftentimes have domain related requests that are not covered by the APIs. In this paper, we propose to expand coverage of task-oriented dialogue systems by incorporating external unstructured knowledge sources. We define three sub-tasks: knowledge-seeking turn detection, knowledge selection, and knowledge-grounded response generation, which can be modeled individually or jointly. We introduce an augmented version of MultiWOZ 2.1, which includes new out-of-API-coverage turns and responses grounded on external knowledge sources. We present baselines for each sub-task using both conventional and neural approaches. Our experimental results demonstrate the need for further research in this direction to enable more informative conversational systems.
Just Ask:An Interactive Learning Framework for Vision and Language Navigation
Dec 02, 2019
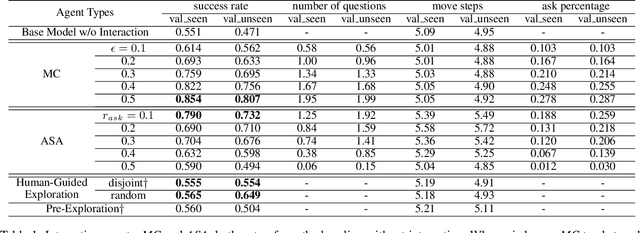
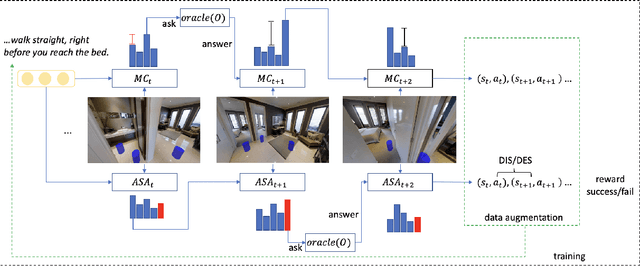

In the vision and language navigation task, the agent may encounter ambiguous situations that are hard to interpret by just relying on visual information and natural language instructions. We propose an interactive learning framework to endow the agent with the ability to ask for users' help in such situations. As part of this framework, we investigate multiple learning approaches for the agent with different levels of complexity. The simplest model-confusion-based method lets the agent ask questions based on its confusion, relying on the predefined confidence threshold of a next action prediction model. To build on this confusion-based method, the agent is expected to demonstrate more sophisticated reasoning such that it discovers the timing and locations to interact with a human. We achieve this goal using reinforcement learning (RL) with a proposed reward shaping term, which enables the agent to ask questions only when necessary. The success rate can be boosted by at least 15% with only one question asked on average during the navigation. Furthermore, we show that the RL agent is capable of adjusting dynamically to noisy human responses. Finally, we design a continual learning strategy, which can be viewed as a data augmentation method, for the agent to improve further utilizing its interaction history with a human. We demonstrate the proposed strategy is substantially more realistic and data-efficient compared to previously proposed pre-exploration techniques.
MultiWOZ 2.1: Multi-Domain Dialogue State Corrections and State Tracking Baselines
Jul 02, 2019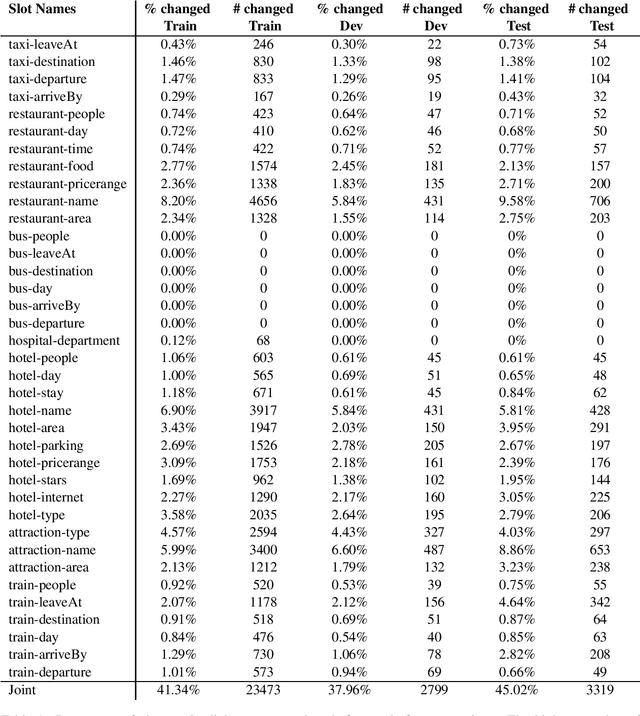

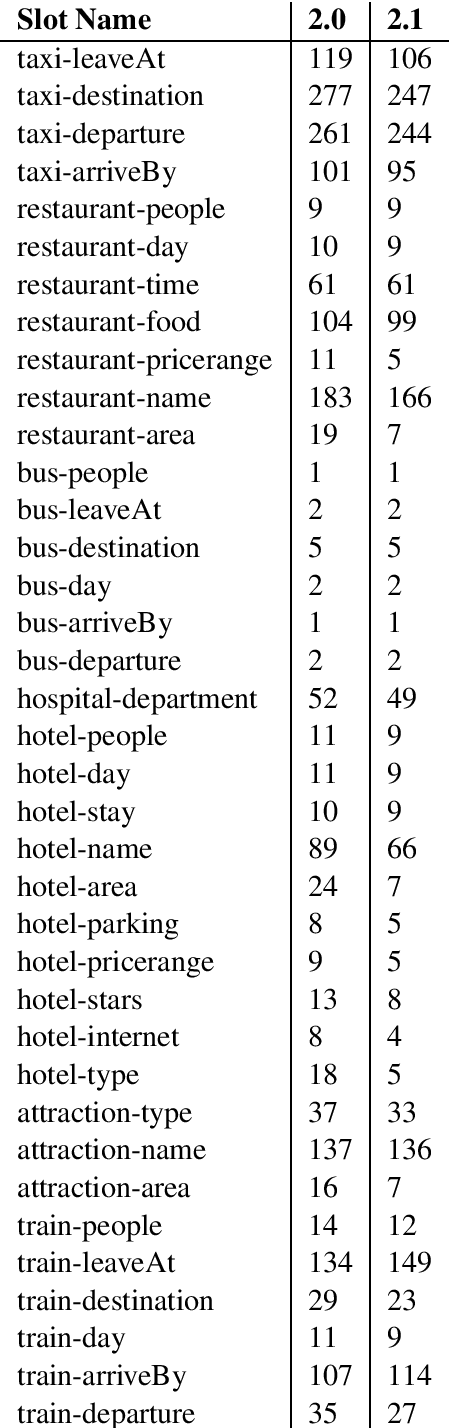
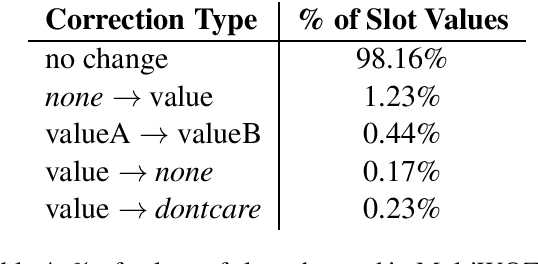
MultiWOZ is a recently-released multidomain dialogue dataset spanning 7 distinct domains and containing over 10000 dialogues, one of the largest resources of its kind to-date. Though an immensely useful resource, while building different classes of dialogue state tracking models using MultiWOZ, we detected substantial errors in the state annotations and dialogue utterances which negatively impacted the performance of our models. In order to alleviate this problem, we use crowdsourced workers to fix the state annotations and utterances in the original version of the data. Our correction process results in changes to over 32% of state annotations across 40% of the dialogue turns. In addition, we fix 146 dialogue utterances throughout the dataset focusing in particular on addressing slot value errors represented within the conversations. We then benchmark a number of state-of-the-art dialogue state tracking models on this new MultiWOZ 2.1 dataset and show joint state tracking performance on the corrected state annotations. We are publicly releasing MultiWOZ 2.1 to the community, hoping that this dataset resource will allow for more effective dialogue state tracking models to be built in the future.
The Pragmatics of Indirect Commands in Collaborative Discourse
Sep 04, 2017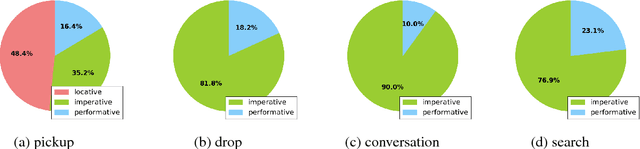

Today's artificial assistants are typically prompted to perform tasks through direct, imperative commands such as \emph{Set a timer} or \emph{Pick up the box}. However, to progress toward more natural exchanges between humans and these assistants, it is important to understand the way non-imperative utterances can indirectly elicit action of an addressee. In this paper, we investigate command types in the setting of a grounded, collaborative game. We focus on a less understood family of utterances for eliciting agent action, locatives like \emph{The chair is in the other room}, and demonstrate how these utterances indirectly command in specific game state contexts. Our work shows that models with domain-specific grounding can effectively realize the pragmatic reasoning that is necessary for more robust natural language interaction.