 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePRESTO: A Multilingual Dataset for Parsing Realistic Task-Oriented Dialogs
Mar 17, 2023



Research interest in task-oriented dialogs has increased as systems such as Google Assistant, Alexa and Siri have become ubiquitous in everyday life. However, the impact of academic research in this area has been limited by the lack of datasets that realistically capture the wide array of user pain points. To enable research on some of the more challenging aspects of parsing realistic conversations, we introduce PRESTO, a public dataset of over 550K contextual multilingual conversations between humans and virtual assistants. PRESTO contains a diverse array of challenges that occur in real-world NLU tasks such as disfluencies, code-switching, and revisions. It is the only large scale human generated conversational parsing dataset that provides structured context such as a user's contacts and lists for each example. Our mT5 model based baselines demonstrate that the conversational phenomenon present in PRESTO are challenging to model, which is further pronounced in a low-resource setup.
Improving Top-K Decoding for Non-Autoregressive Semantic Parsing via Intent Conditioning
Apr 14, 2022
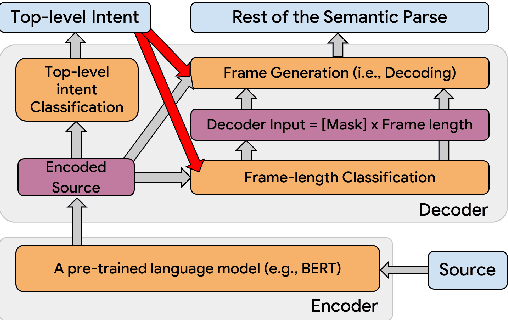

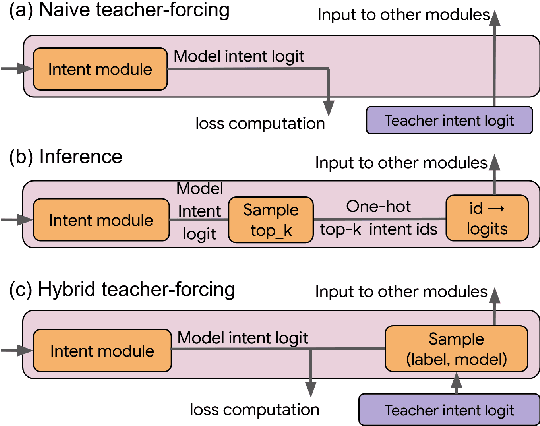
Semantic parsing (SP) is a core component of modern virtual assistants like Google Assistant and Amazon Alexa. While sequence-to-sequence-based auto-regressive (AR) approaches are common for conversational semantic parsing, recent studies employ non-autoregressive (NAR) decoders and reduce inference latency while maintaining competitive parsing quality. However, a major drawback of NAR decoders is the difficulty of generating top-k (i.e., k-best) outputs with approaches such as beam search. To address this challenge, we propose a novel NAR semantic parser that introduces intent conditioning on the decoder. Inspired by the traditional intent and slot tagging parsers, we decouple the top-level intent prediction from the rest of a parse. As the top-level intent largely governs the syntax and semantics of a parse, the intent conditioning allows the model to better control beam search and improves the quality and diversity of top-k outputs. We introduce a hybrid teacher-forcing approach to avoid training and inference mismatch. We evaluate the proposed NAR on conversational SP datasets, TOP & TOPv2. Like the existing NAR models, we maintain the O(1) decoding time complexity while generating more diverse outputs and improving the top-3 exact match (EM) by 2.4 points. In comparison with AR models, our model speeds up beam search inference by 6.7 times on CPU with competitive top-k EM.
TableFormer: Robust Transformer Modeling for Table-Text Encoding
Mar 01, 2022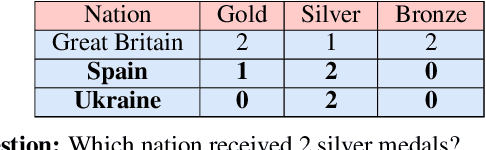
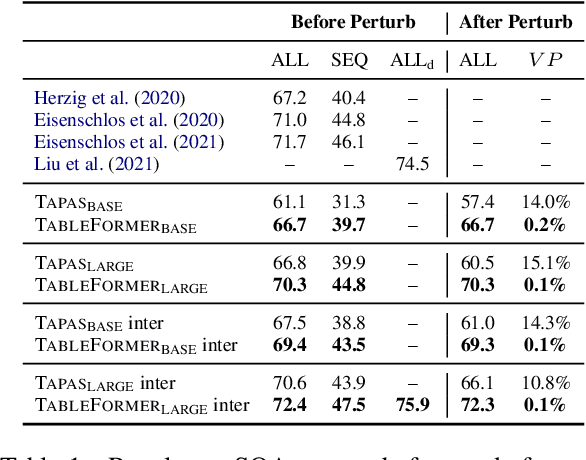


Understanding tables is an important aspect of natural language understanding. Existing models for table understanding require linearization of the table structure, where row or column order is encoded as an unwanted bias. Such spurious biases make the model vulnerable to row and column order perturbations. Additionally, prior work has not thoroughly modeled the table structures or table-text alignments, hindering the table-text understanding ability. In this work, we propose a robust and structurally aware table-text encoding architecture TableFormer, where tabular structural biases are incorporated completely through learnable attention biases. TableFormer is (1) strictly invariant to row and column orders, and, (2) could understand tables better due to its tabular inductive biases. Our evaluations showed that TableFormer outperforms strong baselines in all settings on SQA, WTQ and TabFact table reasoning datasets, and achieves state-of-the-art performance on SQA, especially when facing answer-invariant row and column order perturbations (6% improvement over the best baseline), because previous SOTA models' performance drops by 4% - 6% when facing such perturbations while TableFormer is not affected.
Alexa Conversations: An Extensible Data-driven Approach for Building Task-oriented Dialogue Systems
Apr 19, 2021
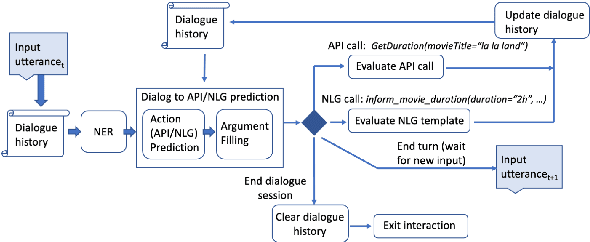

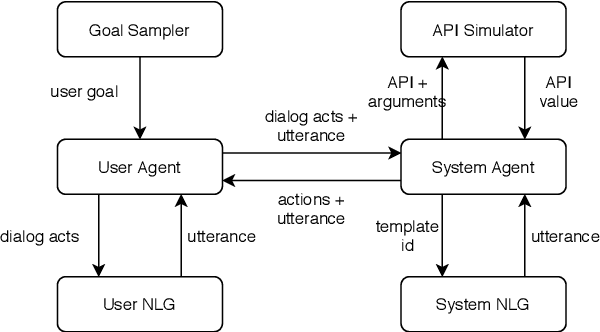
Traditional goal-oriented dialogue systems rely on various components such as natural language understanding, dialogue state tracking, policy learning and response generation. Training each component requires annotations which are hard to obtain for every new domain, limiting scalability of such systems. Similarly, rule-based dialogue systems require extensive writing and maintenance of rules and do not scale either. End-to-End dialogue systems, on the other hand, do not require module-specific annotations but need a large amount of data for training. To overcome these problems, in this demo, we present Alexa Conversations, a new approach for building goal-oriented dialogue systems that is scalable, extensible as well as data efficient. The components of this system are trained in a data-driven manner, but instead of collecting annotated conversations for training, we generate them using a novel dialogue simulator based on a few seed dialogues and specifications of APIs and entities provided by the developer. Our approach provides out-of-the-box support for natural conversational phenomena like entity sharing across turns or users changing their mind during conversation without requiring developers to provide any such dialogue flows. We exemplify our approach using a simple pizza ordering task and showcase its value in reducing the developer burden for creating a robust experience. Finally, we evaluate our system using a typical movie ticket booking task and show that the dialogue simulator is an essential component of the system that leads to over $50\%$ improvement in turn-level action signature prediction accuracy.
Towards Universal Dialogue Act Tagging for Task-Oriented Dialogues
Jul 05, 2019

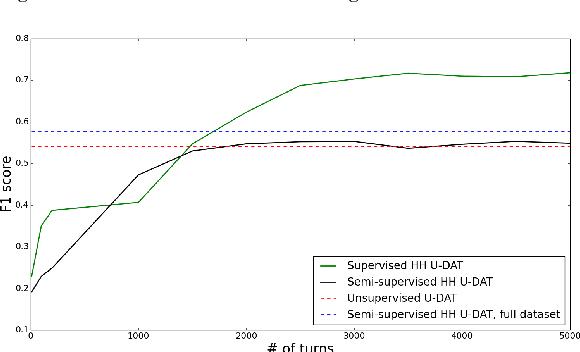
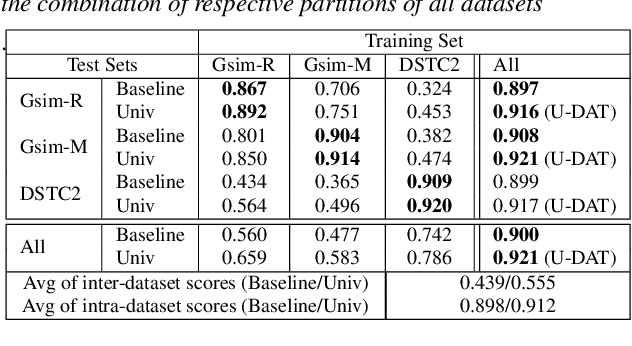
Machine learning approaches for building task-oriented dialogue systems require large conversational datasets with labels to train on. We are interested in building task-oriented dialogue systems from human-human conversations, which may be available in ample amounts in existing customer care center logs or can be collected from crowd workers. Annotating these datasets can be prohibitively expensive. Recently multiple annotated task-oriented human-machine dialogue datasets have been released, however their annotation schema varies across different collections, even for well-defined categories such as dialogue acts (DAs). We propose a Universal DA schema for task-oriented dialogues and align existing annotated datasets with our schema. Our aim is to train a Universal DA tagger (U-DAT) for task-oriented dialogues and use it for tagging human-human conversations. We investigate multiple datasets, propose manual and automated approaches for aligning the different schema, and present results on a target corpus of human-human dialogues. In unsupervised learning experiments we achieve an F1 score of 54.1% on system turns in human-human dialogues. In a semi-supervised setup, the F1 score increases to 57.7% which would otherwise require at least 1.7K manually annotated turns. For new domains, we show further improvements when unlabeled or labeled target domain data is available.
MultiWOZ 2.1: Multi-Domain Dialogue State Corrections and State Tracking Baselines
Jul 02, 2019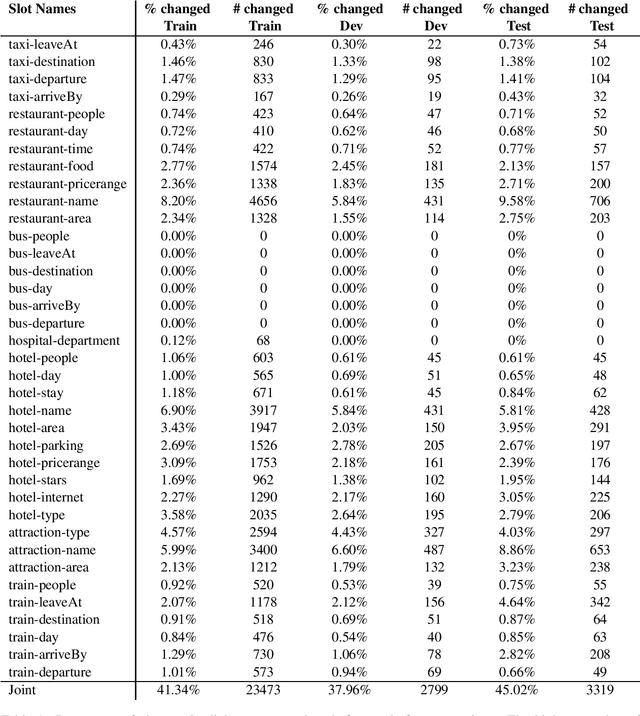

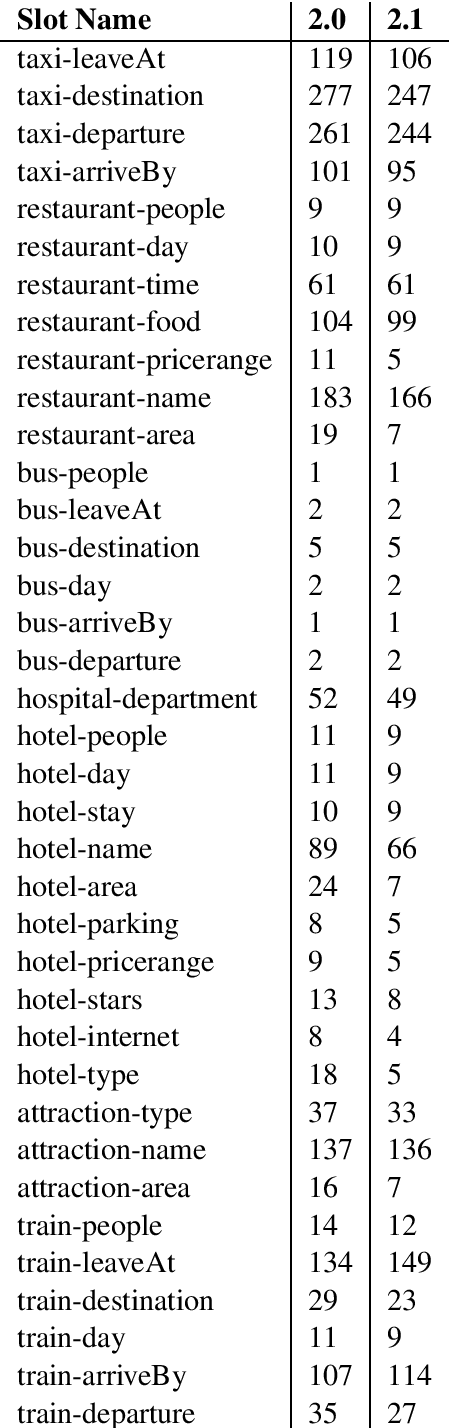
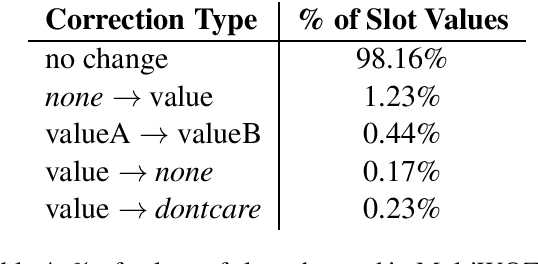
MultiWOZ is a recently-released multidomain dialogue dataset spanning 7 distinct domains and containing over 10000 dialogues, one of the largest resources of its kind to-date. Though an immensely useful resource, while building different classes of dialogue state tracking models using MultiWOZ, we detected substantial errors in the state annotations and dialogue utterances which negatively impacted the performance of our models. In order to alleviate this problem, we use crowdsourced workers to fix the state annotations and utterances in the original version of the data. Our correction process results in changes to over 32% of state annotations across 40% of the dialogue turns. In addition, we fix 146 dialogue utterances throughout the dataset focusing in particular on addressing slot value errors represented within the conversations. We then benchmark a number of state-of-the-art dialogue state tracking models on this new MultiWOZ 2.1 dataset and show joint state tracking performance on the corrected state annotations. We are publicly releasing MultiWOZ 2.1 to the community, hoping that this dataset resource will allow for more effective dialogue state tracking models to be built in the future.
HyST: A Hybrid Approach for Flexible and Accurate Dialogue State Tracking
Jul 01, 2019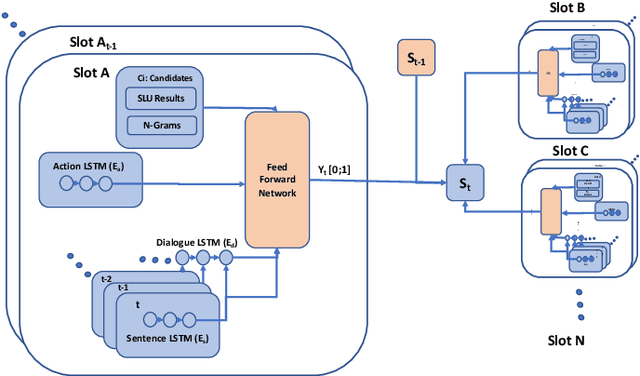
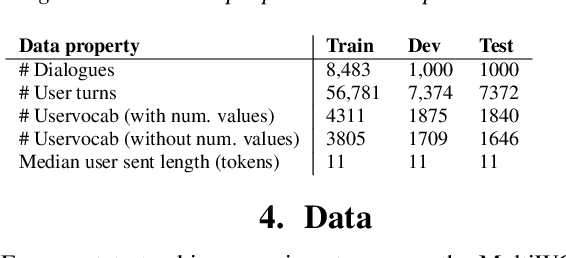
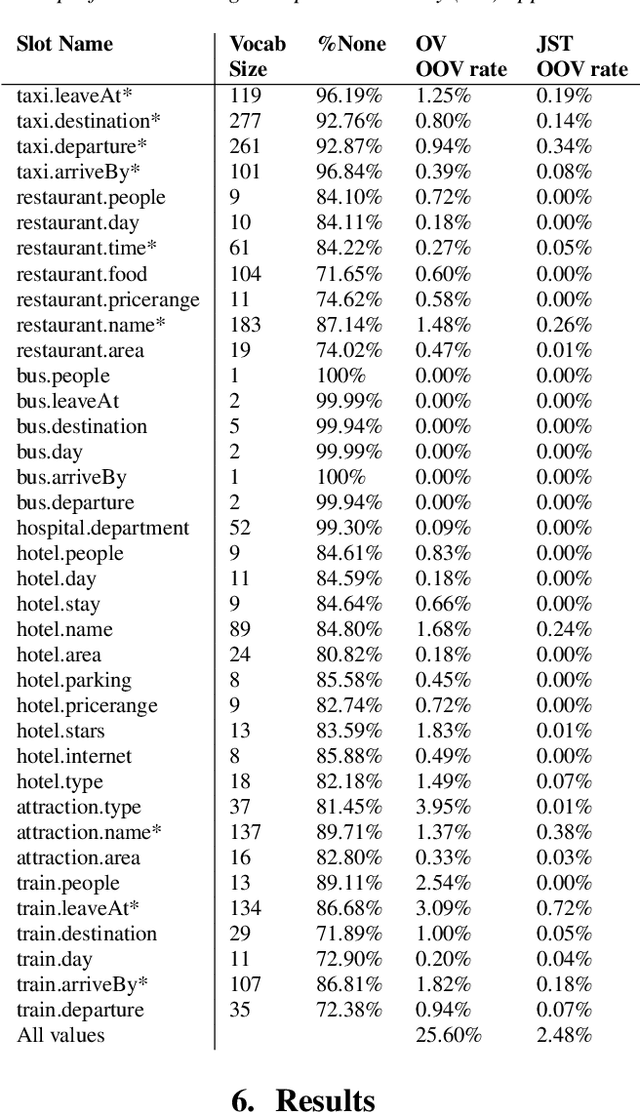
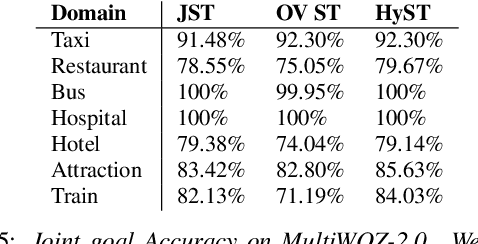
Recent works on end-to-end trainable neural network based approaches have demonstrated state-of-the-art results on dialogue state tracking. The best performing approaches estimate a probability distribution over all possible slot values. However, these approaches do not scale for large value sets commonly present in real-life applications and are not ideal for tracking slot values that were not observed in the training set. To tackle these issues, candidate-generation-based approaches have been proposed. These approaches estimate a set of values that are possible at each turn based on the conversation history and/or language understanding outputs, and hence enable state tracking over unseen values and large value sets however, they fall short in terms of performance in comparison to the first group. In this work, we analyze the performance of these two alternative dialogue state tracking methods, and present a hybrid approach (HyST) which learns the appropriate method for each slot type. To demonstrate the effectiveness of HyST on a rich-set of slot types, we experiment with the recently released MultiWOZ-2.0 multi-domain, task-oriented dialogue-dataset. Our experiments show that HyST scales to multi-domain applications. Our best performing model results in a relative improvement of 24% and 10% over the previous SOTA and our best baseline respectively.
Flexible and Scalable State Tracking Framework for Goal-Oriented Dialogue Systems
Nov 30, 2018


Goal-oriented dialogue systems typically rely on components specifically developed for a single task or domain. This limits such systems in two different ways: If there is an update in the task domain, the dialogue system usually needs to be updated or completely re-trained. It is also harder to extend such dialogue systems to different and multiple domains. The dialogue state tracker in conventional dialogue systems is one such component - it is usually designed to fit a well-defined application domain. For example, it is common for a state variable to be a categorical distribution over a manually-predefined set of entities (Henderson et al., 2013), resulting in an inflexible and hard-to-extend dialogue system. In this paper, we propose a new approach for dialogue state tracking that can generalize well over multiple domains without incorporating any domain-specific knowledge. Under this framework, discrete dialogue state variables are learned independently and the information of a predefined set of possible values for dialogue state variables is not required. Furthermore, it enables adding arbitrary dialogue context as features and allows for multiple values to be associated with a single state variable. These characteristics make it much easier to expand the dialogue state space. We evaluate our framework using the widely used dialogue state tracking challenge data set (DSTC2) and show that our framework yields competitive results with other state-of-the-art results despite incorporating little domain knowledge. We also show that this framework can benefit from widely available external resources such as pre-trained word embeddings.