 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHallucination-Free? Assessing the Reliability of Leading AI Legal Research Tools
May 30, 2024



Legal practice has witnessed a sharp rise in products incorporating artificial intelligence (AI). Such tools are designed to assist with a wide range of core legal tasks, from search and summarization of caselaw to document drafting. But the large language models used in these tools are prone to "hallucinate," or make up false information, making their use risky in high-stakes domains. Recently, certain legal research providers have touted methods such as retrieval-augmented generation (RAG) as "eliminating" (Casetext, 2023) or "avoid[ing]" hallucinations (Thomson Reuters, 2023), or guaranteeing "hallucination-free" legal citations (LexisNexis, 2023). Because of the closed nature of these systems, systematically assessing these claims is challenging. In this article, we design and report on the first preregistered empirical evaluation of AI-driven legal research tools. We demonstrate that the providers' claims are overstated. While hallucinations are reduced relative to general-purpose chatbots (GPT-4), we find that the AI research tools made by LexisNexis (Lexis+ AI) and Thomson Reuters (Westlaw AI-Assisted Research and Ask Practical Law AI) each hallucinate between 17% and 33% of the time. We also document substantial differences between systems in responsiveness and accuracy. Our article makes four key contributions. It is the first to assess and report the performance of RAG-based proprietary legal AI tools. Second, it introduces a comprehensive, preregistered dataset for identifying and understanding vulnerabilities in these systems. Third, it proposes a clear typology for differentiating between hallucinations and accurate legal responses. Last, it provides evidence to inform the responsibilities of legal professionals in supervising and verifying AI outputs, which remains a central open question for the responsible integration of AI into law.
LegalBench: A Collaboratively Built Benchmark for Measuring Legal Reasoning in Large Language Models
Aug 20, 2023
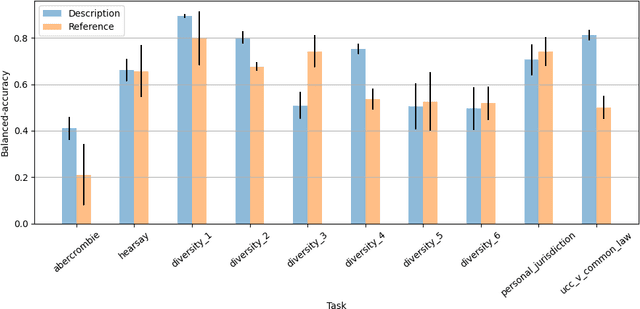
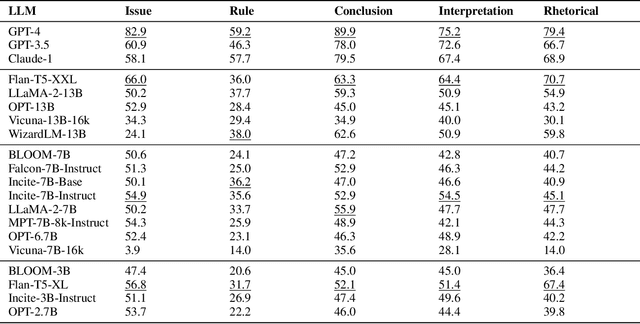
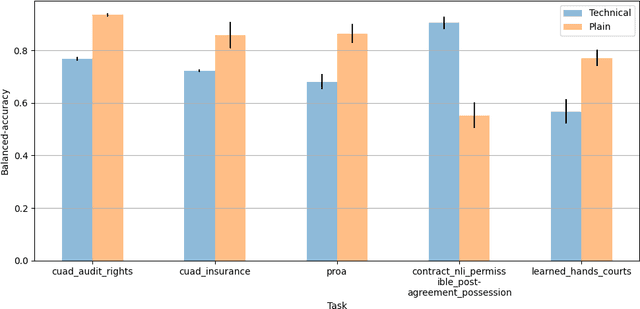
The advent of large language models (LLMs) and their adoption by the legal community has given rise to the question: what types of legal reasoning can LLMs perform? To enable greater study of this question, we present LegalBench: a collaboratively constructed legal reasoning benchmark consisting of 162 tasks covering six different types of legal reasoning. LegalBench was built through an interdisciplinary process, in which we collected tasks designed and hand-crafted by legal professionals. Because these subject matter experts took a leading role in construction, tasks either measure legal reasoning capabilities that are practically useful, or measure reasoning skills that lawyers find interesting. To enable cross-disciplinary conversations about LLMs in the law, we additionally show how popular legal frameworks for describing legal reasoning -- which distinguish between its many forms -- correspond to LegalBench tasks, thus giving lawyers and LLM developers a common vocabulary. This paper describes LegalBench, presents an empirical evaluation of 20 open-source and commercial LLMs, and illustrates the types of research explorations LegalBench enables.
PRESTO: A Multilingual Dataset for Parsing Realistic Task-Oriented Dialogs
Mar 17, 2023



Research interest in task-oriented dialogs has increased as systems such as Google Assistant, Alexa and Siri have become ubiquitous in everyday life. However, the impact of academic research in this area has been limited by the lack of datasets that realistically capture the wide array of user pain points. To enable research on some of the more challenging aspects of parsing realistic conversations, we introduce PRESTO, a public dataset of over 550K contextual multilingual conversations between humans and virtual assistants. PRESTO contains a diverse array of challenges that occur in real-world NLU tasks such as disfluencies, code-switching, and revisions. It is the only large scale human generated conversational parsing dataset that provides structured context such as a user's contacts and lists for each example. Our mT5 model based baselines demonstrate that the conversational phenomenon present in PRESTO are challenging to model, which is further pronounced in a low-resource setup.