 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJudgmentBench: Comparing Rubric and Preference Evaluation for Quality Assessment
May 24, 2026Two methodologies dominate current practices of benchmarking: rubric-based scoring evaluates items against predefined criteria, whereas comparative judgment elicits pairwise preferences between outputs. Although both methodologies are widely used, the choice between them is rarely justified. We release JudgmentBench, a benchmark of 30 real-world legal tasks, paired with 1,539 rubric scores and 1,530 pairwise preference judgments collected from practicing attorneys--including at major U.S. law firms--with substantial experience. The annotations constitute the first publicly available dataset in a high-expertise domain in which both supervision signals are elicited from the same experts on the same items. Using LLM-generated outputs at three constructed quality levels, we provide an initial empirical comparison: comparative judgments recover the intended quality ordering substantially better than rubrics (mean Spearman's rank correlation of 0.908 vs. 0.150, estimated difference = 0.758 [0.494, 1.021]) while requiring less than half the annotation time. The patterns hold for human annotators and LLM autograders. Beyond this initial comparison, the paired structure of the dataset supports a broader research agenda on how expert judgment should be elicited, aggregated, and used as supervision in domains without verifiable ground truth.
Identifying Emerging Concepts in Large Corpora
Feb 28, 2025We introduce a new method to identify emerging concepts in large text corpora. By analyzing changes in the heatmaps of the underlying embedding space, we are able to detect these concepts with high accuracy shortly after they originate, in turn outperforming common alternatives. We further demonstrate the utility of our approach by analyzing speeches in the U.S. Senate from 1941 to 2015. Our results suggest that the minority party is more active in introducing new concepts into the Senate discourse. We also identify specific concepts that closely correlate with the Senators' racial, ethnic, and gender identities. An implementation of our method is publicly available.
Breaking Down Bias: On The Limits of Generalizable Pruning Strategies
Feb 11, 2025We employ model pruning to examine how LLMs conceptualize racial biases, and whether a generalizable mitigation strategy for such biases appears feasible. Our analysis yields several novel insights. We find that pruning can be an effective method to reduce bias without significantly increasing anomalous model behavior. Neuron-based pruning strategies generally yield better results than approaches pruning entire attention heads. However, our results also show that the effectiveness of either approach quickly deteriorates as pruning strategies become more generalized. For instance, a model that is trained on removing racial biases in the context of financial decision-making poorly generalizes to biases in commercial transactions. Overall, our analysis suggests that racial biases are only partially represented as a general concept within language models. The other part of these biases is highly context-specific, suggesting that generalizable mitigation strategies may be of limited effectiveness. Our findings have important implications for legal frameworks surrounding AI. In particular, they suggest that an effective mitigation strategy should include the allocation of legal responsibility on those that deploy models in a specific use case.
What's in a Name? Auditing Large Language Models for Race and Gender Bias
Feb 29, 2024



We employ an audit design to investigate biases in state-of-the-art large language models, including GPT-4. In our study, we prompt the models for advice involving a named individual across a variety of scenarios, such as during car purchase negotiations or election outcome predictions. We find that the advice systematically disadvantages names that are commonly associated with racial minorities and women. Names associated with Black women receive the least advantageous outcomes. The biases are consistent across 42 prompt templates and several models, indicating a systemic issue rather than isolated incidents. While providing numerical, decision-relevant anchors in the prompt can successfully counteract the biases, qualitative details have inconsistent effects and may even increase disparities. Our findings underscore the importance of conducting audits at the point of LLM deployment and implementation to mitigate their potential for harm against marginalized communities.
LegalBench: A Collaboratively Built Benchmark for Measuring Legal Reasoning in Large Language Models
Aug 20, 2023
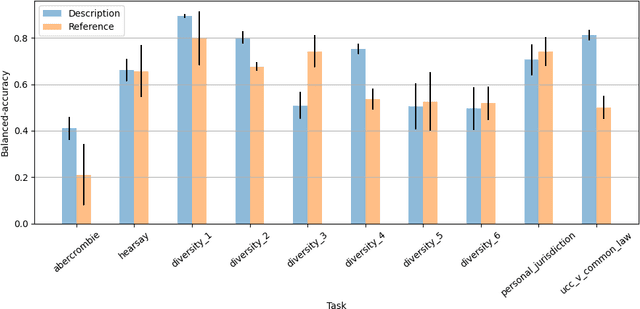
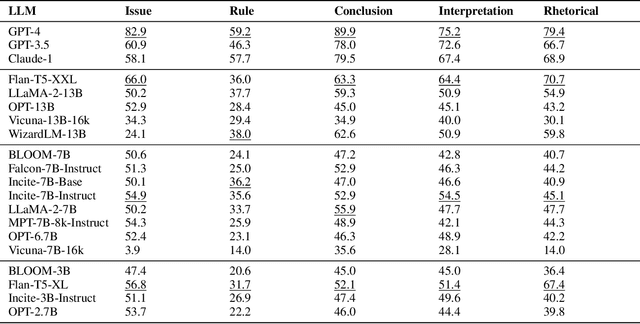
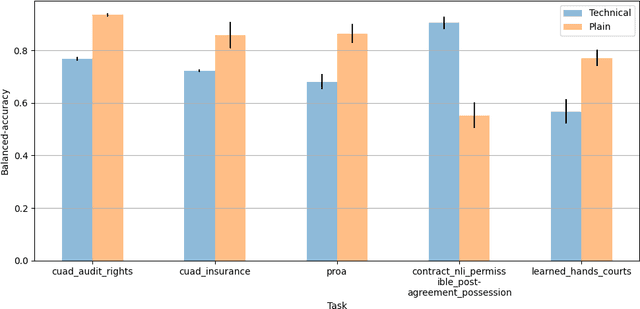
The advent of large language models (LLMs) and their adoption by the legal community has given rise to the question: what types of legal reasoning can LLMs perform? To enable greater study of this question, we present LegalBench: a collaboratively constructed legal reasoning benchmark consisting of 162 tasks covering six different types of legal reasoning. LegalBench was built through an interdisciplinary process, in which we collected tasks designed and hand-crafted by legal professionals. Because these subject matter experts took a leading role in construction, tasks either measure legal reasoning capabilities that are practically useful, or measure reasoning skills that lawyers find interesting. To enable cross-disciplinary conversations about LLMs in the law, we additionally show how popular legal frameworks for describing legal reasoning -- which distinguish between its many forms -- correspond to LegalBench tasks, thus giving lawyers and LLM developers a common vocabulary. This paper describes LegalBench, presents an empirical evaluation of 20 open-source and commercial LLMs, and illustrates the types of research explorations LegalBench enables.
Designing Equitable Algorithms
Feb 17, 2023Predictive algorithms are now used to help distribute a large share of our society's resources and sanctions, such as healthcare, loans, criminal detentions, and tax audits. Under the right circumstances, these algorithms can improve the efficiency and equity of decision-making. At the same time, there is a danger that the algorithms themselves could entrench and exacerbate disparities, particularly along racial, ethnic, and gender lines. To help ensure their fairness, many researchers suggest that algorithms be subject to at least one of three constraints: (1) no use of legally protected features, such as race, ethnicity, and gender; (2) equal rates of "positive" decisions across groups; and (3) equal error rates across groups. Here we show that these constraints, while intuitively appealing, often worsen outcomes for individuals in marginalized groups, and can even leave all groups worse off. The inherent trade-off we identify between formal fairness constraints and welfare improvements -- particularly for the marginalized -- highlights the need for a more robust discussion on what it means for an algorithm to be "fair". We illustrate these ideas with examples from healthcare and the criminal-legal system, and make several proposals to help practitioners design more equitable algorithms.
LegalBench: Prototyping a Collaborative Benchmark for Legal Reasoning
Sep 13, 2022


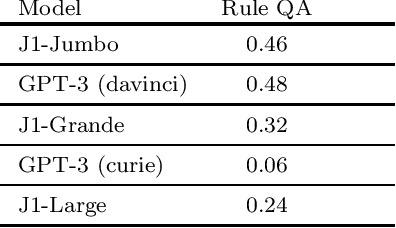
Can foundation models be guided to execute tasks involving legal reasoning? We believe that building a benchmark to answer this question will require sustained collaborative efforts between the computer science and legal communities. To that end, this short paper serves three purposes. First, we describe how IRAC-a framework legal scholars use to distinguish different types of legal reasoning-can guide the construction of a Foundation Model oriented benchmark. Second, we present a seed set of 44 tasks built according to this framework. We discuss initial findings, and highlight directions for new tasks. Finally-inspired by the Open Science movement-we make a call for the legal and computer science communities to join our efforts by contributing new tasks. This work is ongoing, and our progress can be tracked here: https://github.com/HazyResearch/legalbench.
Forecasting Algorithms for Causal Inference with Panel Data
Aug 06, 2022



Conducting causal inference with panel data is a core challenge in social science research. Advances in forecasting methods can facilitate this task by more accurately predicting the counterfactual evolution of a treated unit had treatment not occurred. In this paper, we draw on a newly developed deep neural architecture for time series forecasting (the N-BEATS algorithm). We adapt this method from conventional time series applications by incorporating leading values of control units to predict a "synthetic" untreated version of the treated unit in the post-treatment period. We refer to the estimator derived from this method as SyNBEATS, and find that it significantly outperforms traditional two-way fixed effects and synthetic control methods across a range of settings. We also find that SyNBEATS attains comparable or more accurate performance relative to more recent panel estimation methods such as matrix completion and synthetic difference in differences. Our results highlight how advances in the forecasting literature can be harnessed to improve causal inference in panel settings.
On the Opportunities and Risks of Foundation Models
Aug 18, 2021



AI is undergoing a paradigm shift with the rise of models (e.g., BERT, DALL-E, GPT-3) that are trained on broad data at scale and are adaptable to a wide range of downstream tasks. We call these models foundation models to underscore their critically central yet incomplete character. This report provides a thorough account of the opportunities and risks of foundation models, ranging from their capabilities (e.g., language, vision, robotics, reasoning, human interaction) and technical principles(e.g., model architectures, training procedures, data, systems, security, evaluation, theory) to their applications (e.g., law, healthcare, education) and societal impact (e.g., inequity, misuse, economic and environmental impact, legal and ethical considerations). Though foundation models are based on standard deep learning and transfer learning, their scale results in new emergent capabilities,and their effectiveness across so many tasks incentivizes homogenization. Homogenization provides powerful leverage but demands caution, as the defects of the foundation model are inherited by all the adapted models downstream. Despite the impending widespread deployment of foundation models, we currently lack a clear understanding of how they work, when they fail, and what they are even capable of due to their emergent properties. To tackle these questions, we believe much of the critical research on foundation models will require deep interdisciplinary collaboration commensurate with their fundamentally sociotechnical nature.