 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Accounting Identity for Algorithmic Fairness
Jan 28, 2026We derive an accounting identity for predictive models that links accuracy with common fairness criteria. The identity shows that for globally calibrated models, the weighted sums of miscalibration within groups and error imbalance across groups is equal to a "total unfairness budget." For binary outcomes, this budget is the model's mean-squared error times the difference in group prevalence across outcome classes. The identity nests standard impossibility results as special cases, while also describing inherent tradeoffs when one or more fairness measures are not perfectly satisfied. The results suggest that accuracy and fairness are best viewed as complements in binary prediction tasks: increasing accuracy necessarily shrinks the total unfairness budget and vice-versa. Experiments on benchmark data confirm the theory and show that many fairness interventions largely substitute between fairness violations, and when they reduce accuracy they tend to expand the total unfairness budget. The results extend naturally to prediction tasks with non-binary outcomes, illustrating how additional outcome information can relax fairness incompatibilities and identifying conditions under which the binary-style impossibility does and does not extend to regression tasks.
Near-Exponential Savings for Mean Estimation with Active Learning
Nov 07, 2025We study the problem of efficiently estimating the mean of a $k$-class random variable, $Y$, using a limited number of labels, $N$, in settings where the analyst has access to auxiliary information (i.e.: covariates) $X$ that may be informative about $Y$. We propose an active learning algorithm ("PartiBandits") to estimate $\mathbb{E}[Y]$. The algorithm yields an estimate, $\widehatμ_{\text{PB}}$, such that $\left( \widehatμ_{\text{PB}} - \mathbb{E}[Y]\right)^2$ is $\tilde{\mathcal{O}}\left( \frac{ν+ \exp(c \cdot (-N/\log(N))) }{N} \right)$, where $c > 0$ is a constant and $ν$ is the risk of the Bayes-optimal classifier. PartiBandits is essentially a two-stage algorithm. In the first stage, it learns a partition of the unlabeled data that shrinks the average conditional variance of $Y$. In the second stage it uses a UCB-style subroutine ("WarmStart-UCB") to request labels from each stratum round-by-round. Both the main algorithm's and the subroutine's convergence rates are minimax optimal in classical settings. PartiBandits bridges the UCB and disagreement-based approaches to active learning despite these two approaches being designed to tackle very different tasks. We illustrate our methods through simulation using nationwide electronic health records. Our methods can be implemented using the PartiBandits package in R.
Estimating and Implementing Conventional Fairness Metrics With Probabilistic Protected Features
Oct 02, 2023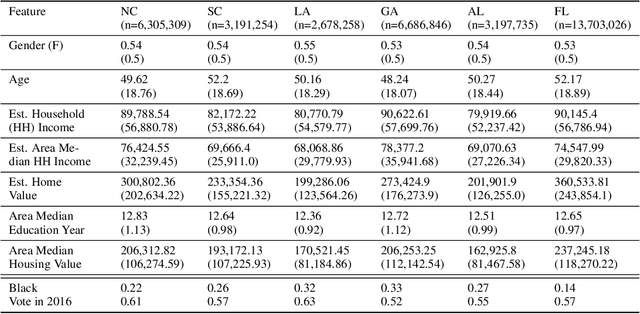
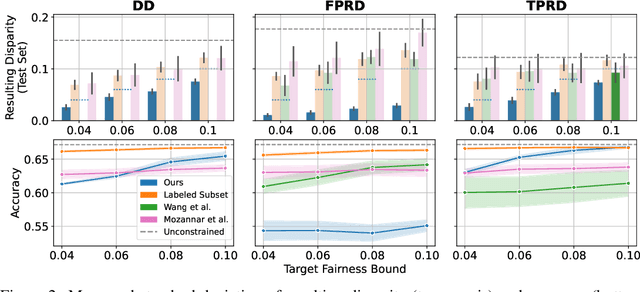
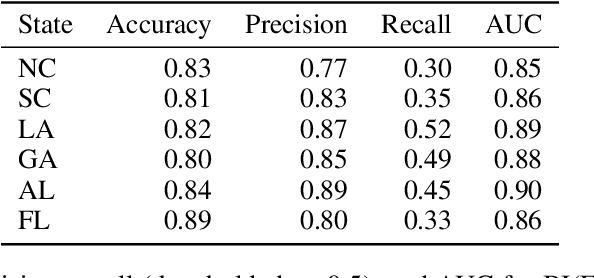
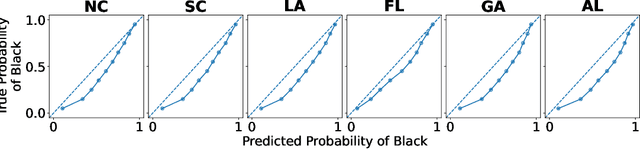
The vast majority of techniques to train fair models require access to the protected attribute (e.g., race, gender), either at train time or in production. However, in many important applications this protected attribute is largely unavailable. In this paper, we develop methods for measuring and reducing fairness violations in a setting with limited access to protected attribute labels. Specifically, we assume access to protected attribute labels on a small subset of the dataset of interest, but only probabilistic estimates of protected attribute labels (e.g., via Bayesian Improved Surname Geocoding) for the rest of the dataset. With this setting in mind, we propose a method to estimate bounds on common fairness metrics for an existing model, as well as a method for training a model to limit fairness violations by solving a constrained non-convex optimization problem. Unlike similar existing approaches, our methods take advantage of contextual information -- specifically, the relationships between a model's predictions and the probabilistic prediction of protected attributes, given the true protected attribute, and vice versa -- to provide tighter bounds on the true disparity. We provide an empirical illustration of our methods using voting data. First, we show our measurement method can bound the true disparity up to 5.5x tighter than previous methods in these applications. Then, we demonstrate that our training technique effectively reduces disparity while incurring lesser fairness-accuracy trade-offs than other fair optimization methods with limited access to protected attributes.
Entropy Regularization for Population Estimation
Aug 24, 2022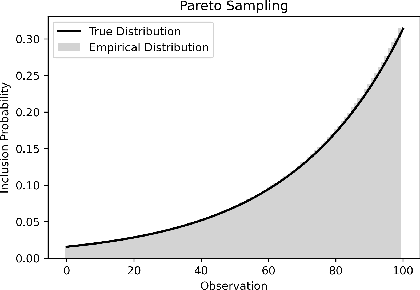
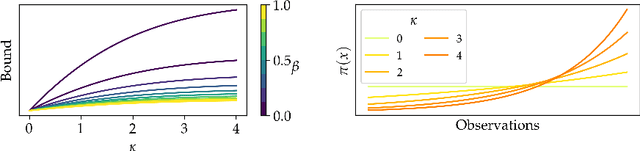
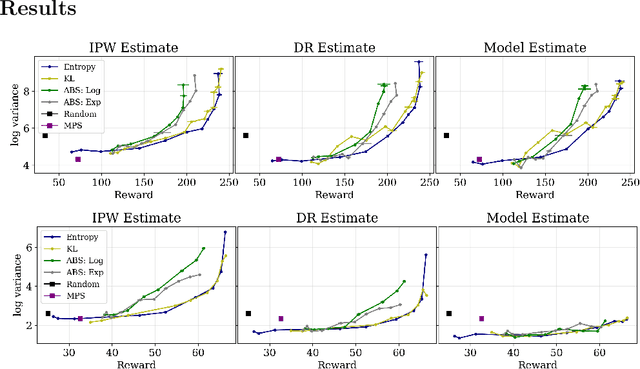
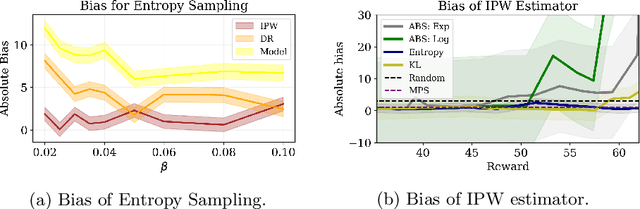
Entropy regularization is known to improve exploration in sequential decision-making problems. We show that this same mechanism can also lead to nearly unbiased and lower-variance estimates of the mean reward in the optimize-and-estimate structured bandit setting. Mean reward estimation (i.e., population estimation) tasks have recently been shown to be essential for public policy settings where legal constraints often require precise estimates of population metrics. We show that leveraging entropy and KL divergence can yield a better trade-off between reward and estimator variance than existing baselines, all while remaining nearly unbiased. These properties of entropy regularization illustrate an exciting potential for bridging the optimal exploration and estimation literatures.
Forecasting Algorithms for Causal Inference with Panel Data
Aug 06, 2022



Conducting causal inference with panel data is a core challenge in social science research. Advances in forecasting methods can facilitate this task by more accurately predicting the counterfactual evolution of a treated unit had treatment not occurred. In this paper, we draw on a newly developed deep neural architecture for time series forecasting (the N-BEATS algorithm). We adapt this method from conventional time series applications by incorporating leading values of control units to predict a "synthetic" untreated version of the treated unit in the post-treatment period. We refer to the estimator derived from this method as SyNBEATS, and find that it significantly outperforms traditional two-way fixed effects and synthetic control methods across a range of settings. We also find that SyNBEATS attains comparable or more accurate performance relative to more recent panel estimation methods such as matrix completion and synthetic difference in differences. Our results highlight how advances in the forecasting literature can be harnessed to improve causal inference in panel settings.
Algorithmic Fairness and Vertical Equity: Income Fairness with IRS Tax Audit Models
Jun 20, 2022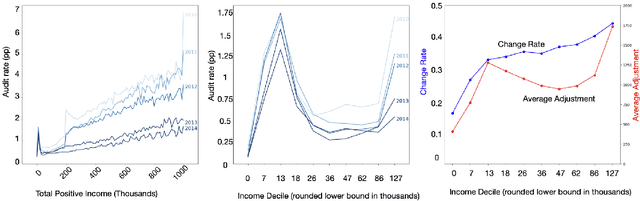
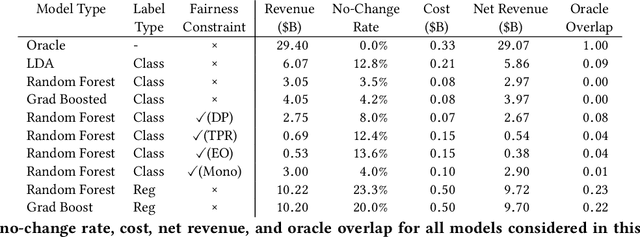
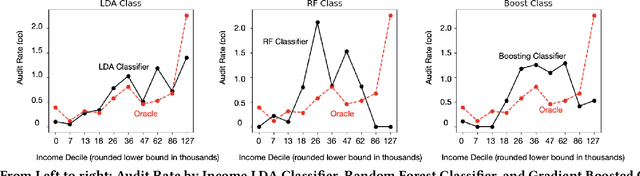
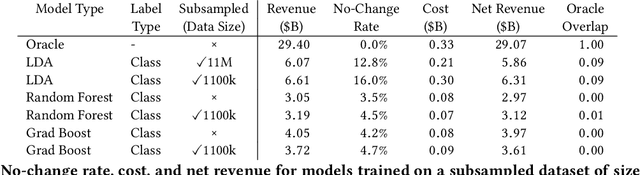
This study examines issues of algorithmic fairness in the context of systems that inform tax audit selection by the United States Internal Revenue Service (IRS). While the field of algorithmic fairness has developed primarily around notions of treating like individuals alike, we instead explore the concept of vertical equity -- appropriately accounting for relevant differences across individuals -- which is a central component of fairness in many public policy settings. Applied to the design of the U.S. individual income tax system, vertical equity relates to the fair allocation of tax and enforcement burdens across taxpayers of different income levels. Through a unique collaboration with the Treasury Department and IRS, we use access to anonymized individual taxpayer microdata, risk-selected audits, and random audits from 2010-14 to study vertical equity in tax administration. In particular, we assess how the use of modern machine learning methods for selecting audits may affect vertical equity. First, we show how the use of more flexible machine learning (classification) methods -- as opposed to simpler models -- shifts audit burdens from high to middle-income taxpayers. Second, we show that while existing algorithmic fairness techniques can mitigate some disparities across income, they can incur a steep cost to performance. Third, we show that the choice of whether to treat risk of underreporting as a classification or regression problem is highly consequential. Moving from classification to regression models to predict underreporting shifts audit burden substantially toward high income individuals, while increasing revenue. Last, we explore the role of differential audit cost in shaping the audit distribution. We show that a narrow focus on return-on-investment can undermine vertical equity. Our results have implications for the design of algorithmic tools across the public sector.
Integrating Reward Maximization and Population Estimation: Sequential Decision-Making for Internal Revenue Service Audit Selection
Apr 25, 2022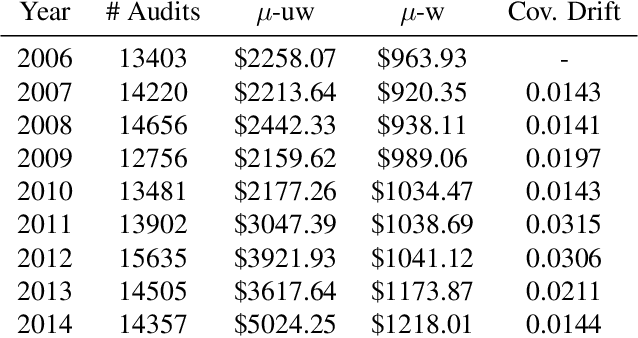
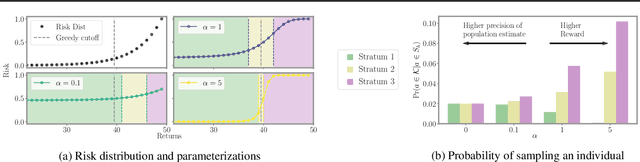
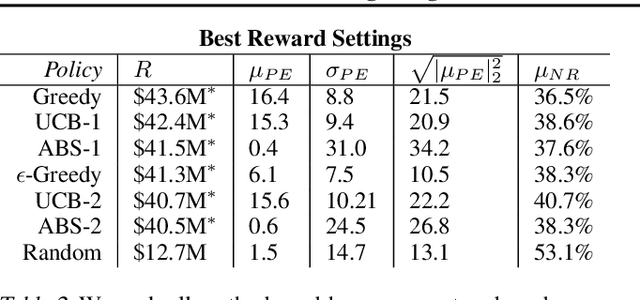
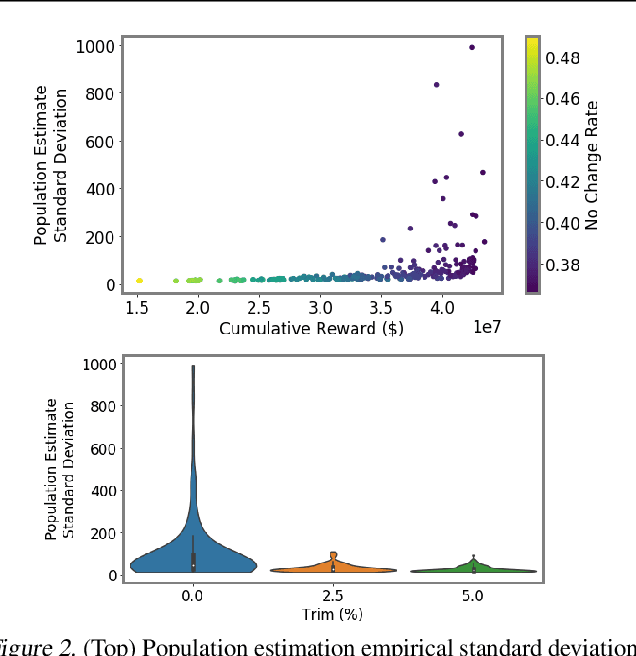
We introduce a new setting, optimize-and-estimate structured bandits. Here, a policy must select a batch of arms, each characterized by its own context, that would allow it to both maximize reward and maintain an accurate (ideally unbiased) population estimate of the reward. This setting is inherent to many public and private sector applications and often requires handling delayed feedback, small data, and distribution shifts. We demonstrate its importance on real data from the United States Internal Revenue Service (IRS). The IRS performs yearly audits of the tax base. Two of its most important objectives are to identify suspected misreporting and to estimate the "tax gap" - the global difference between the amount paid and true amount owed. We cast these two processes as a unified optimize-and-estimate structured bandit. We provide a novel mechanism for unbiased population estimation that achieves rewards comparable to baseline approaches. This approach has the potential to improve audit efficacy, while maintaining policy-relevant estimates of the tax gap. This has important social consequences given that the current tax gap is estimated at nearly half a trillion dollars. We suggest that this problem setting is fertile ground for further research and we highlight its interesting challenges.