 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCascadeServe: Unlocking Model Cascades for Inference Serving
Jun 20, 2024Machine learning (ML) models are increasingly deployed to production, calling for efficient inference serving systems. Efficient inference serving is complicated by two challenges: (i) ML models incur high computational costs, and (ii) the request arrival rates of practical applications have frequent, high, and sudden variations which make it hard to correctly provision hardware. Model cascades are positioned to tackle both of these challenges, as they (i) save work while maintaining accuracy, and (ii) expose a high-resolution trade-off between work and accuracy, allowing for fine-grained adjustments to request arrival rates. Despite their potential, model cascades haven't been used inside an online serving system. This comes with its own set of challenges, including workload adaption, model replication onto hardware, inference scheduling, request batching, and more. In this work, we propose CascadeServe, which automates and optimizes end-to-end inference serving with cascades. CascadeServe operates in an offline and online phase. In the offline phase, the system pre-computes a gear plan that specifies how to serve inferences online. In the online phase, the gear plan allows the system to serve inferences while making near-optimal adaptations to the query load at negligible decision overheads. We find that CascadeServe saves 2-3x in cost across a wide spectrum of the latency-accuracy space when compared to state-of-the-art baselines on different workloads.
Integrating Reward Maximization and Population Estimation: Sequential Decision-Making for Internal Revenue Service Audit Selection
Apr 25, 2022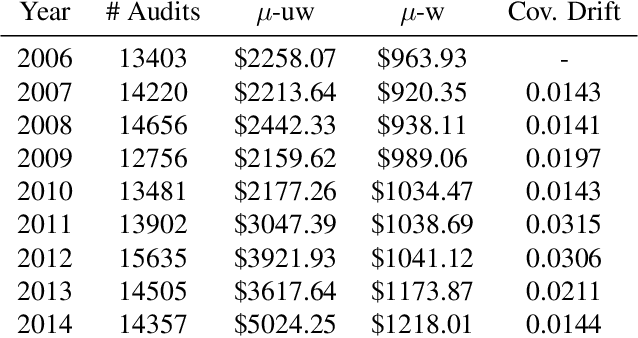
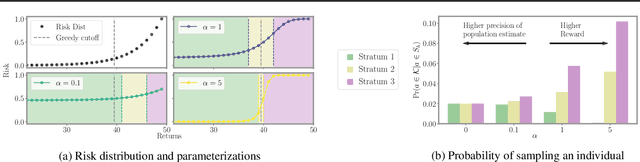
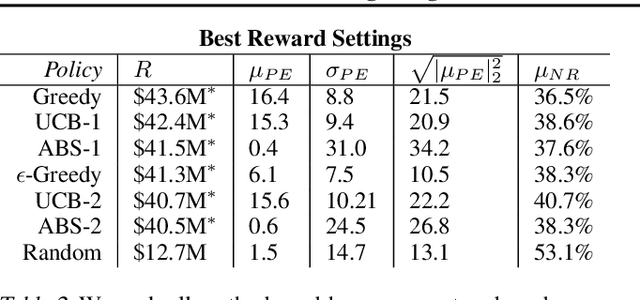
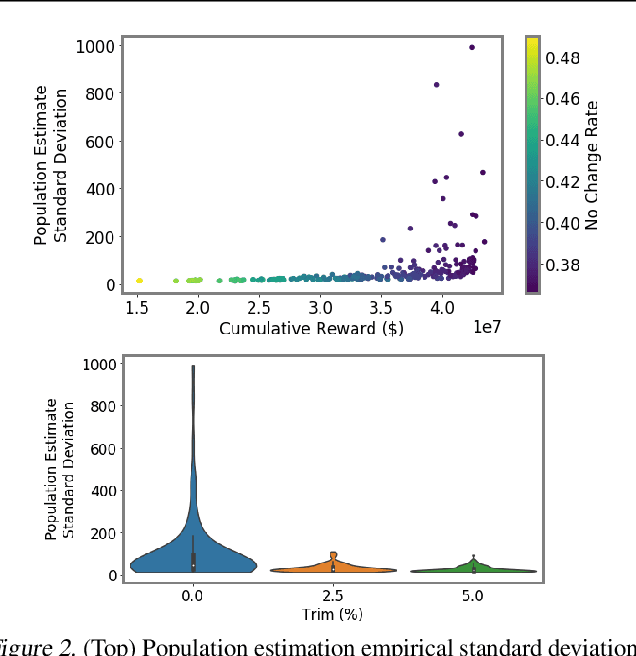
We introduce a new setting, optimize-and-estimate structured bandits. Here, a policy must select a batch of arms, each characterized by its own context, that would allow it to both maximize reward and maintain an accurate (ideally unbiased) population estimate of the reward. This setting is inherent to many public and private sector applications and often requires handling delayed feedback, small data, and distribution shifts. We demonstrate its importance on real data from the United States Internal Revenue Service (IRS). The IRS performs yearly audits of the tax base. Two of its most important objectives are to identify suspected misreporting and to estimate the "tax gap" - the global difference between the amount paid and true amount owed. We cast these two processes as a unified optimize-and-estimate structured bandit. We provide a novel mechanism for unbiased population estimation that achieves rewards comparable to baseline approaches. This approach has the potential to improve audit efficacy, while maintaining policy-relevant estimates of the tax gap. This has important social consequences given that the current tax gap is estimated at nearly half a trillion dollars. We suggest that this problem setting is fertile ground for further research and we highlight its interesting challenges.
Chess AI: Competing Paradigms for Machine Intelligence
Sep 23, 2021
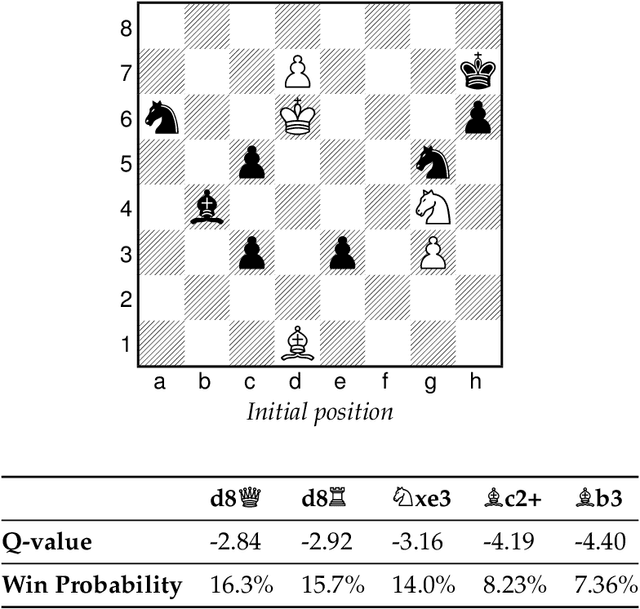


Endgame studies have long served as a tool for testing human creativity and intelligence. We find that they can serve as a tool for testing machine ability as well. Two of the leading chess engines, Stockfish and Leela Chess Zero (LCZero), employ significantly different methods during play. We use Plaskett's Puzzle, a famous endgame study from the late 1970s, to compare the two engines. Our experiments show that Stockfish outperforms LCZero on the puzzle. We examine the algorithmic differences between the engines and use our observations as a basis for carefully interpreting the test results. Drawing inspiration from how humans solve chess problems, we ask whether machines can possess a form of imagination. On the theoretical side, we describe how Bellman's equation may be applied to optimize the probability of winning. To conclude, we discuss the implications of our work on artificial intelligence (AI) and artificial general intelligence (AGI), suggesting possible avenues for future research.