 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePEEK: Context Map as an Orientation Cache for Long-Context LLM Agents
May 19, 2026Large language model (LLM) agents increasingly operate over long and recurring external contexts, like document corpora and code repositories. Across invocations, existing approaches preserve either the agent's trajectory, passive access to raw material, or task-level strategies. None of them preserves what we argue is most needed for repeated same-context workloads: reusable orientation knowledge (e.g., what the context contains, how it is organized, and which entities, constants, and schemas have historically been useful) about the recurring context itself. We introduce PEEK, a system that caches and maintains this orientation knowledge as a context map: a small, constant-sized artifact in the agent's prompt that gives it a persistent peek into the external context. The map is maintained by a programmable cache policy with three modules: a Distiller that extracts transferable knowledge from inference-time signals, a Cartographer that translates it into structured edits, and a priority-based Evictor that enforces a fixed token budget. On long-context reasoning and information aggregation, PEEK improves over strong baselines by 6.3-34.0% while using 93-145 fewer iterations and incurring 1.7-5.8x lower cost than the state-of-the-art prompt-learning framework, ACE. On context learning, PEEK improves solving rate and rubric accuracy by 6.0-14.0% and 7.8-12.1%, respectively, at 1.4x lower cost than ACE. These gains generalize across LMs and agent architectures, including OpenAI Codex, a production-grade coding agent. Together, these results show that a context map helps long-context LLM agents interact with recurring external contexts more accurately and efficiently.
CONCUR: A Framework for Continual Constrained and Unconstrained Routing
Dec 10, 2025AI tasks differ in complexity and are best addressed with different computation strategies (e.g., combinations of models and decoding methods). Hence, an effective routing system that maps tasks to the appropriate strategies is crucial. Most prior methods build the routing framework by training a single model across all strategies, which demands full retraining whenever new strategies appear and leads to high overhead. Attempts at such continual routing, however, often face difficulties with generalization. Prior models also typically use a single input representation, limiting their ability to capture the full complexity of the routing problem and leading to sub-optimal routing decisions. To address these gaps, we propose CONCUR, a continual routing framework that supports both constrained and unconstrained routing (i.e., routing with or without a budget). Our modular design trains a separate predictor model for each strategy, enabling seamless incorporation of new strategies with low additional training cost. Our predictors also leverage multiple representations of both tasks and computation strategies to better capture overall problem complexity. Experiments on both in-distribution and out-of-distribution, knowledge- and reasoning-intensive tasks show that our method outperforms the best single strategy and strong existing routing techniques with higher end-to-end accuracy and lower inference cost in both continual and non-continual settings, while also reducing training cost in the continual setting.
DejaVid: Encoder-Agnostic Learned Temporal Matching for Video Classification
Jun 14, 2025In recent years, large transformer-based video encoder models have greatly advanced state-of-the-art performance on video classification tasks. However, these large models typically process videos by averaging embedding outputs from multiple clips over time to produce fixed-length representations. This approach fails to account for a variety of time-related features, such as variable video durations, chronological order of events, and temporal variance in feature significance. While methods for temporal modeling do exist, they often require significant architectural changes and expensive retraining, making them impractical for off-the-shelf, fine-tuned large encoders. To overcome these limitations, we propose DejaVid, an encoder-agnostic method that enhances model performance without the need for retraining or altering the architecture. Our framework converts a video into a variable-length temporal sequence of embeddings, which we call a multivariate time series (MTS). An MTS naturally preserves temporal order and accommodates variable video durations. We then learn per-timestep, per-feature weights over the encoded MTS frames, allowing us to account for variations in feature importance over time. We introduce a new neural network architecture inspired by traditional time series alignment algorithms for this learning task. Our evaluation demonstrates that DejaVid substantially improves the performance of a state-of-the-art large encoder, achieving leading Top-1 accuracy of 77.2% on Something-Something V2, 89.1% on Kinetics-400, and 88.6% on HMDB51, while adding fewer than 1.8% additional learnable parameters and requiring less than 3 hours of training time. Our code is available at https://github.com/darrylho/DejaVid.
KramaBench: A Benchmark for AI Systems on Data-to-Insight Pipelines over Data Lakes
Jun 06, 2025Constructing real-world data-to-insight pipelines often involves data extraction from data lakes, data integration across heterogeneous data sources, and diverse operations from data cleaning to analysis. The design and implementation of data science pipelines require domain knowledge, technical expertise, and even project-specific insights. AI systems have shown remarkable reasoning, coding, and understanding capabilities. However, it remains unclear to what extent these capabilities translate into successful design and execution of such complex pipelines. We introduce KRAMABENCH: a benchmark composed of 104 manually-curated real-world data science pipelines spanning 1700 data files from 24 data sources in 6 different domains. We show that these pipelines test the end-to-end capabilities of AI systems on data processing, requiring data discovery, wrangling and cleaning, efficient processing, statistical reasoning, and orchestrating data processing steps given a high-level task. Our evaluation tests 5 general models and 3 code generation models using our reference framework, DS-GURU, which instructs the AI model to decompose a question into a sequence of subtasks, reason through each step, and synthesize Python code that implements the proposed design. Our results on KRAMABENCH show that, although the models are sufficiently capable of solving well-specified data science code generation tasks, when extensive data processing and domain knowledge are required to construct real-world data science pipelines, existing out-of-box models fall short. Progress on KramaBench represents crucial steps towards developing autonomous data science agents for real-world applications. Our code, reference framework, and data are available at https://github.com/mitdbg/KramaBench.
Abacus: A Cost-Based Optimizer for Semantic Operator Systems
May 20, 2025LLMs enable an exciting new class of data processing applications over large collections of unstructured documents. Several new programming frameworks have enabled developers to build these applications by composing them out of semantic operators: a declarative set of AI-powered data transformations with natural language specifications. These include LLM-powered maps, filters, joins, etc. used for document processing tasks such as information extraction, summarization, and more. While systems of semantic operators have achieved strong performance on benchmarks, they can be difficult to optimize. An optimizer for this setting must determine how to physically implement each semantic operator in a way that optimizes the system globally. Existing optimizers are limited in the number of optimizations they can apply, and most (if not all) cannot optimize system quality, cost, or latency subject to constraint(s) on the other dimensions. In this paper we present Abacus, an extensible, cost-based optimizer which searches for the best implementation of a semantic operator system given a (possibly constrained) optimization objective. Abacus estimates operator performance by leveraging a minimal set of validation examples and, if available, prior beliefs about operator performance. We evaluate Abacus on document processing workloads in the biomedical and legal domains (BioDEX; CUAD) and multi-modal question answering (MMQA). We demonstrate that systems optimized by Abacus achieve 18.7%-39.2% better quality and up to 23.6x lower cost and 4.2x lower latency than the next best system.
Log-Augmented Generation: Scaling Test-Time Reasoning with Reusable Computation
May 20, 2025While humans naturally learn and adapt from past experiences, large language models (LLMs) and their agentic counterparts struggle to retain reasoning from previous tasks and apply them in future contexts. To address this limitation, we propose a novel framework, log-augmented generation (LAG) that directly reuses prior computation and reasoning from past logs at test time to enhance model's ability to learn from previous tasks and perform better on new, unseen challenges, all while keeping the system efficient and scalable. Specifically, our system represents task logs using key-value (KV) caches, encoding the full reasoning context of prior tasks while storing KV caches for only a selected subset of tokens. When a new task arises, LAG retrieves the KV values from relevant logs to augment generation. Our approach differs from reflection-based memory mechanisms by directly reusing prior reasoning and computations without requiring additional steps for knowledge extraction or distillation. Our method also goes beyond existing KV caching techniques, which primarily target efficiency gains rather than improving accuracy. Experiments on knowledge- and reasoning-intensive datasets demonstrate that our method significantly outperforms standard agentic systems that do not utilize logs, as well as existing solutions based on reflection and KV cache techniques.
Improving DBMS Scheduling Decisions with Fine-grained Performance Prediction on Concurrent Queries -- Extended
Jan 27, 2025Query scheduling is a critical task that directly impacts query performance in database management systems (DBMS). Deeply integrated schedulers, which require changes to DBMS internals, are usually customized for a specific engine and can take months to implement. In contrast, non-intrusive schedulers make coarse-grained decisions, such as controlling query admission and re-ordering query execution, without requiring modifications to DBMS internals. They require much less engineering effort and can be applied across a wide range of DBMS engines, offering immediate benefits to end users. However, most existing non-intrusive scheduling systems rely on simplified cost models and heuristics that cannot accurately model query interactions under concurrency and different system states, possibly leading to suboptimal scheduling decisions. This work introduces IconqSched, a new, principled non-intrusive scheduler that optimizes the execution order and timing of queries to enhance total end-to-end runtime as experienced by the user query queuing time plus system runtime. Unlike previous approaches, IconqSched features a novel fine-grained predictor, Iconq, which treats the DBMS as a black box and accurately estimates the system runtime of concurrently executed queries under different system states. Using these predictions, IconqSched is able to capture system runtime variations across different query mixes and system loads. It then employs a greedy scheduling algorithm to effectively determine which queries to submit and when to submit them. We compare IconqSched to other schedulers in terms of end-to-end runtime using real workload traces. On Postgres, IconqSched reduces end-to-end runtime by 16.2%-28.2% on average and 33.6%-38.9% in the tail. Similarly, on Redshift, it reduces end-to-end runtime by 10.3%-14.1% on average and 14.9%-22.2% in the tail.
Is the GPU Half-Empty or Half-Full? Practical Scheduling Techniques for LLMs
Oct 23, 2024



Serving systems for Large Language Models (LLMs) improve throughput by processing several requests concurrently. However, multiplexing hardware resources between concurrent requests involves non-trivial scheduling decisions. Practical serving systems typically implement these decisions at two levels: First, a load balancer routes requests to different servers which each hold a replica of the LLM. Then, on each server, an engine-level scheduler decides when to run a request, or when to queue or preempt it. Improved scheduling policies may benefit a wide range of LLM deployments and can often be implemented as "drop-in replacements" to a system's current policy. In this work, we survey scheduling techniques from the literature and from practical serving systems. We find that schedulers from the literature often achieve good performance but introduce significant complexity. In contrast, schedulers in practical deployments often leave easy performance gains on the table but are easy to implement, deploy and configure. This finding motivates us to introduce two new scheduling techniques, which are both easy to implement, and outperform current techniques on production workload traces.
CascadeServe: Unlocking Model Cascades for Inference Serving
Jun 20, 2024Machine learning (ML) models are increasingly deployed to production, calling for efficient inference serving systems. Efficient inference serving is complicated by two challenges: (i) ML models incur high computational costs, and (ii) the request arrival rates of practical applications have frequent, high, and sudden variations which make it hard to correctly provision hardware. Model cascades are positioned to tackle both of these challenges, as they (i) save work while maintaining accuracy, and (ii) expose a high-resolution trade-off between work and accuracy, allowing for fine-grained adjustments to request arrival rates. Despite their potential, model cascades haven't been used inside an online serving system. This comes with its own set of challenges, including workload adaption, model replication onto hardware, inference scheduling, request batching, and more. In this work, we propose CascadeServe, which automates and optimizes end-to-end inference serving with cascades. CascadeServe operates in an offline and online phase. In the offline phase, the system pre-computes a gear plan that specifies how to serve inferences online. In the online phase, the gear plan allows the system to serve inferences while making near-optimal adaptations to the query load at negligible decision overheads. We find that CascadeServe saves 2-3x in cost across a wide spectrum of the latency-accuracy space when compared to state-of-the-art baselines on different workloads.
A Declarative System for Optimizing AI Workloads
May 23, 2024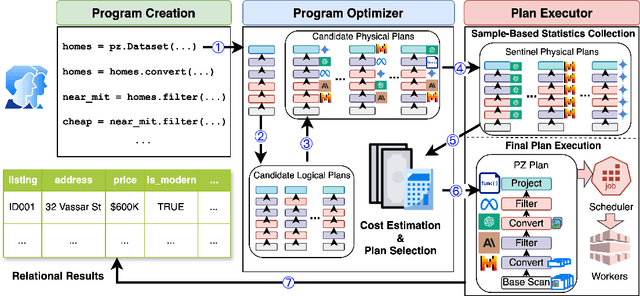
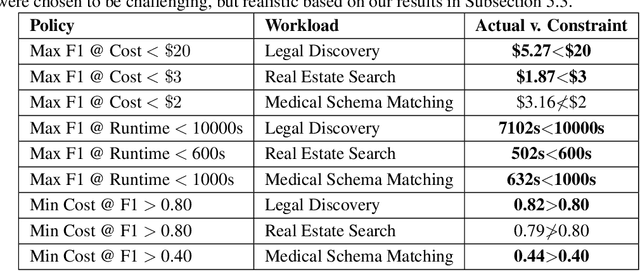
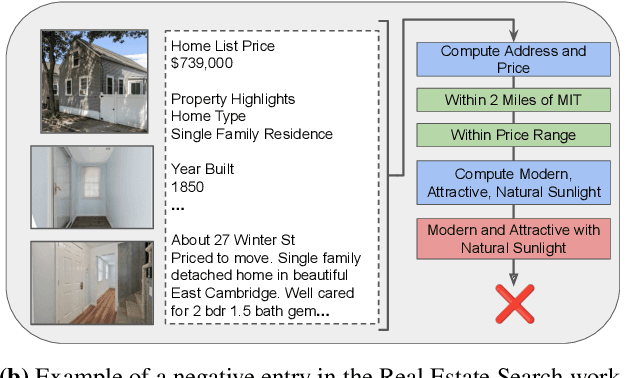
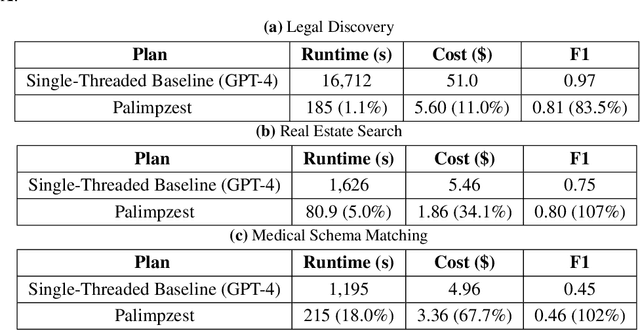
Modern AI models provide the key to a long-standing dream: processing analytical queries about almost any kind of data. Until recently, it was difficult and expensive to extract facts from company documents, data from scientific papers, or insights from image and video corpora. Today's models can accomplish these tasks with high accuracy. However, a programmer who wants to answer a substantive AI-powered query must orchestrate large numbers of models, prompts, and data operations. For even a single query, the programmer has to make a vast number of decisions such as the choice of model, the right inference method, the most cost-effective inference hardware, the ideal prompt design, and so on. The optimal set of decisions can change as the query changes and as the rapidly-evolving technical landscape shifts. In this paper we present Palimpzest, a system that enables anyone to process AI-powered analytical queries simply by defining them in a declarative language. The system uses its cost optimization framework -- which explores the search space of AI models, prompting techniques, and related foundation model optimizations -- to implement the query with the best trade-offs between runtime, financial cost, and output data quality. We describe the workload of AI-powered analytics tasks, the optimization methods that Palimpzest uses, and the prototype system itself. We evaluate Palimpzest on tasks in Legal Discovery, Real Estate Search, and Medical Schema Matching. We show that even our simple prototype offers a range of appealing plans, including one that is 3.3x faster, 2.9x cheaper, and offers better data quality than the baseline method. With parallelism enabled, Palimpzest can produce plans with up to a 90.3x speedup at 9.1x lower cost relative to a single-threaded GPT-4 baseline, while obtaining an F1-score within 83.5% of the baseline. These require no additional work by the user.