 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIs the GPU Half-Empty or Half-Full? Practical Scheduling Techniques for LLMs
Oct 23, 2024



Serving systems for Large Language Models (LLMs) improve throughput by processing several requests concurrently. However, multiplexing hardware resources between concurrent requests involves non-trivial scheduling decisions. Practical serving systems typically implement these decisions at two levels: First, a load balancer routes requests to different servers which each hold a replica of the LLM. Then, on each server, an engine-level scheduler decides when to run a request, or when to queue or preempt it. Improved scheduling policies may benefit a wide range of LLM deployments and can often be implemented as "drop-in replacements" to a system's current policy. In this work, we survey scheduling techniques from the literature and from practical serving systems. We find that schedulers from the literature often achieve good performance but introduce significant complexity. In contrast, schedulers in practical deployments often leave easy performance gains on the table but are easy to implement, deploy and configure. This finding motivates us to introduce two new scheduling techniques, which are both easy to implement, and outperform current techniques on production workload traces.
TensorNetwork: A Library for Physics and Machine Learning
May 03, 2019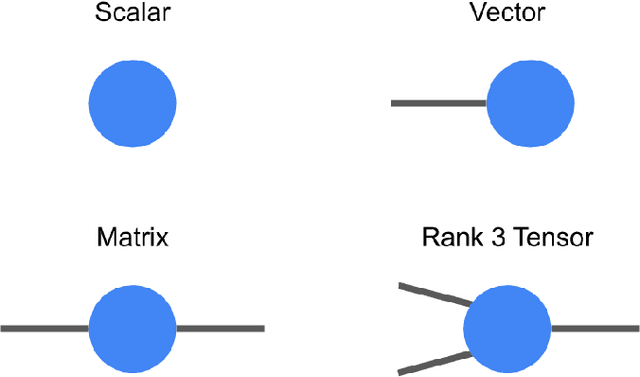
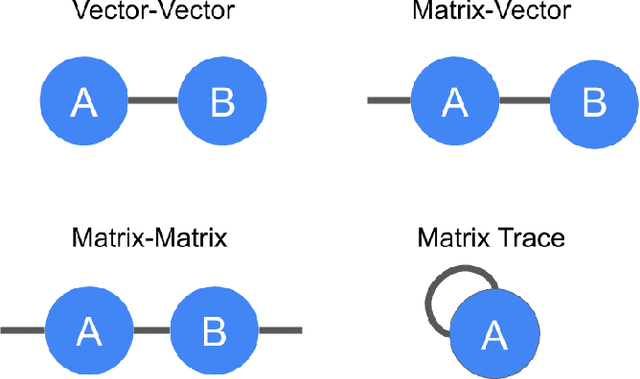
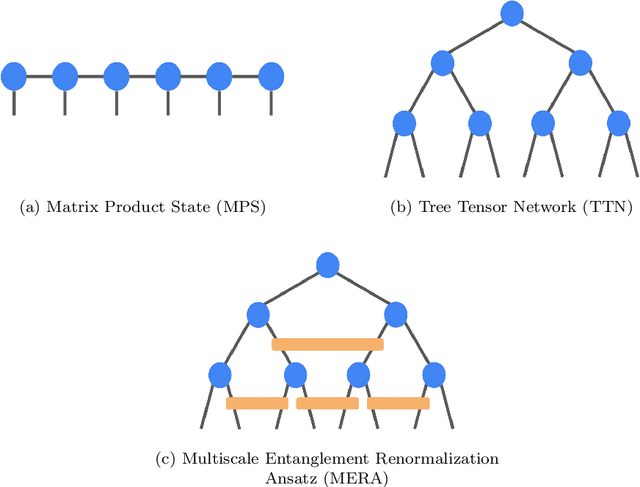
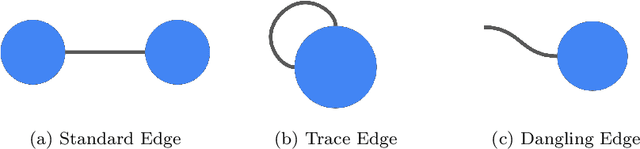
TensorNetwork is an open source library for implementing tensor network algorithms. Tensor networks are sparse data structures originally designed for simulating quantum many-body physics, but are currently also applied in a number of other research areas, including machine learning. We demonstrate the use of the API with applications both physics and machine learning, with details appearing in companion papers.