 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Language Model Scaling Laws for Neural Quantum States in Quantum Chemistry
Sep 16, 2025



Scaling laws have been used to describe how large language model (LLM) performance scales with model size, training data size, or amount of computational resources. Motivated by the fact that neural quantum states (NQS) has increasingly adopted LLM-based components, we seek to understand NQS scaling laws, thereby shedding light on the scalability and optimal performance--resource trade-offs of NQS ansatze. In particular, we identify scaling laws that predict the performance, as measured by absolute error and V-score, for transformer-based NQS as a function of problem size in second-quantized quantum chemistry applications. By performing analogous compute-constrained optimization of the obtained parametric curves, we find that the relationship between model size and training time is highly dependent on loss metric and ansatz, and does not follow the approximately linear relationship found for language models.
Retentive Neural Quantum States: Efficient Ansätze for Ab Initio Quantum Chemistry
Nov 06, 2024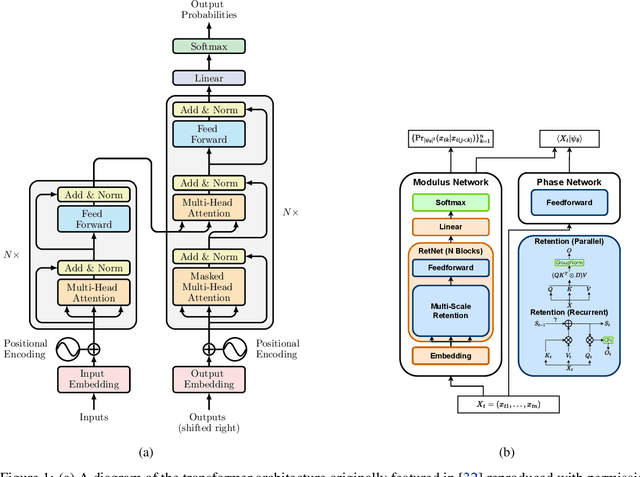

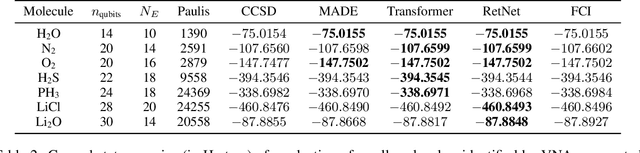
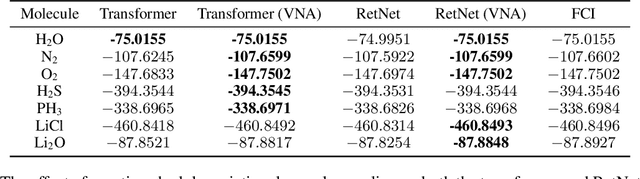
Neural-network quantum states (NQS) has emerged as a powerful application of quantum-inspired deep learning for variational Monte Carlo methods, offering a competitive alternative to existing techniques for identifying ground states of quantum problems. A significant advancement toward improving the practical scalability of NQS has been the incorporation of autoregressive models, most recently transformers, as variational ansatze. Transformers learn sequence information with greater expressiveness than recurrent models, but at the cost of increased time complexity with respect to sequence length. We explore the use of the retentive network (RetNet), a recurrent alternative to transformers, as an ansatz for solving electronic ground state problems in $\textit{ab initio}$ quantum chemistry. Unlike transformers, RetNets overcome this time complexity bottleneck by processing data in parallel during training, and recurrently during inference. We give a simple computational cost estimate of the RetNet and directly compare it with similar estimates for transformers, establishing a clear threshold ratio of problem-to-model size past which the RetNet's time complexity outperforms that of the transformer. Though this efficiency can comes at the expense of decreased expressiveness relative to the transformer, we overcome this gap through training strategies that leverage the autoregressive structure of the model -- namely, variational neural annealing. Our findings support the RetNet as a means of improving the time complexity of NQS without sacrificing accuracy. We provide further evidence that the ablative improvements of neural annealing extend beyond the RetNet architecture, suggesting it would serve as an effective general training strategy for autoregressive NQS.
Entanglement and Tensor Networks for Supervised Image Classification
Jul 12, 2020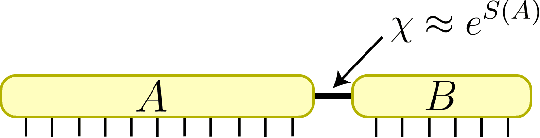
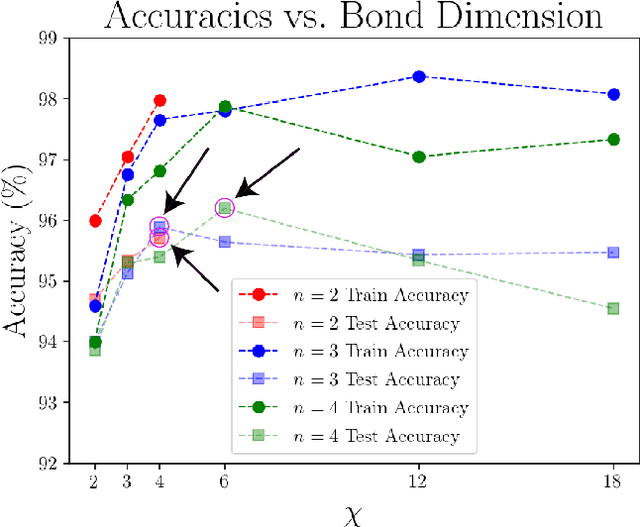
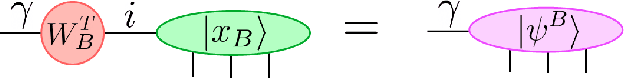
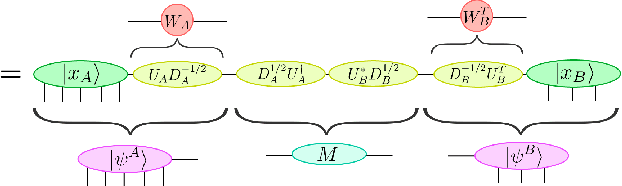
Tensor networks, originally designed to address computational problems in quantum many-body physics, have recently been applied to machine learning tasks. However, compared to quantum physics, where the reasons for the success of tensor network approaches over the last 30 years is well understood, very little is yet known about why these techniques work for machine learning. The goal of this paper is to investigate entanglement properties of tensor network models in a current machine learning application, in order to uncover general principles that may guide future developments. We revisit the use of tensor networks for supervised image classification using the MNIST data set of handwritten digits, as pioneered by Stoudenmire and Schwab [Adv. in Neur. Inform. Proc. Sys. 29, 4799 (2016)]. Firstly we hypothesize about which state the tensor network might be learning during training. For that purpose, we propose a plausible candidate state $|\Sigma_{\ell}\rangle$ (built as a superposition of product states corresponding to images in the training set) and investigate its entanglement properties. We conclude that $|\Sigma_{\ell}\rangle$ is so robustly entangled that it cannot be approximated by the tensor network used in that work, which must therefore be representing a very different state. Secondly, we use tensor networks with a block product structure, in which entanglement is restricted within small blocks of $n \times n$ pixels/qubits. We find that these states are extremely expressive (e.g. training accuracy of $99.97 \%$ already for $n=2$), suggesting that long-range entanglement may not be essential for image classification. However, in our current implementation, optimization leads to over-fitting, resulting in test accuracies that are not competitive with other current approaches.
Anomaly Detection with Tensor Networks
Jun 16, 2020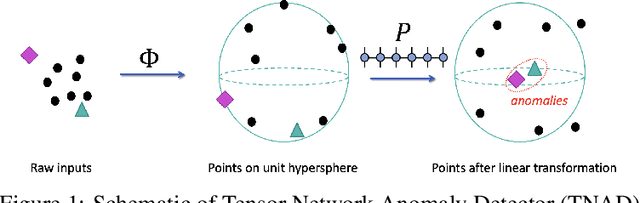
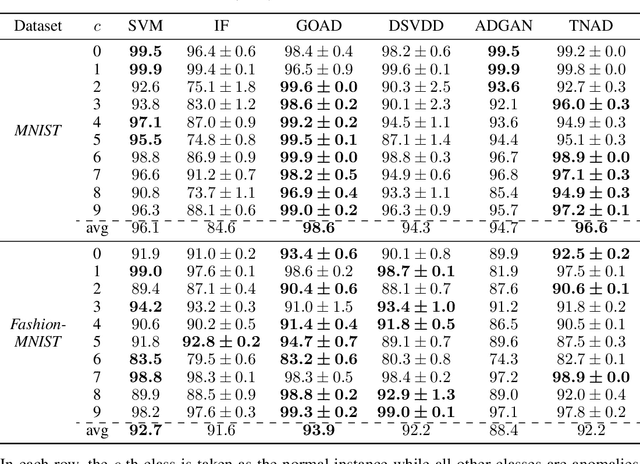
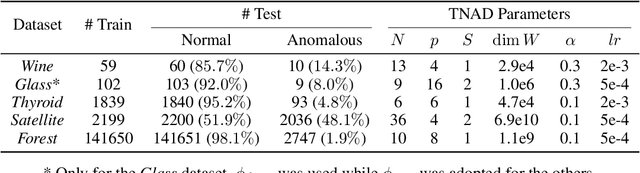
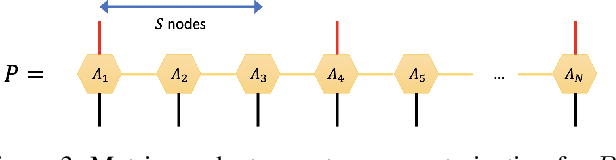
Originating from condensed matter physics, tensor networks are compact representations of high-dimensional tensors. In this paper, the prowess of tensor networks is demonstrated on the particular task of one-class anomaly detection. We exploit the memory and computational efficiency of tensor networks to learn a linear transformation over a space with dimension exponential in the number of original features. The linearity of our model enables us to ensure a tight fit around training instances by penalizing the model's global tendency to a predict normality via its Frobenius norm---a task that is infeasible for most deep learning models. Our method outperforms deep and classical algorithms on tabular datasets and produces competitive results on image datasets, despite not exploiting the locality of images.
Quantum Hamiltonian-Based Models and the Variational Quantum Thermalizer Algorithm
Oct 04, 2019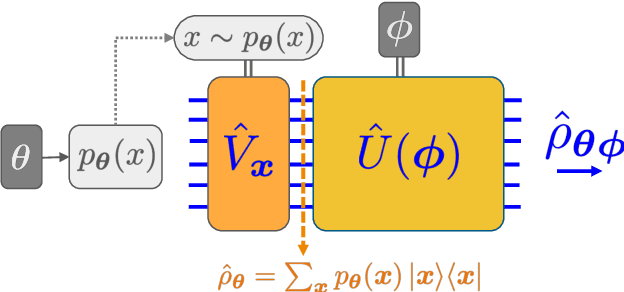
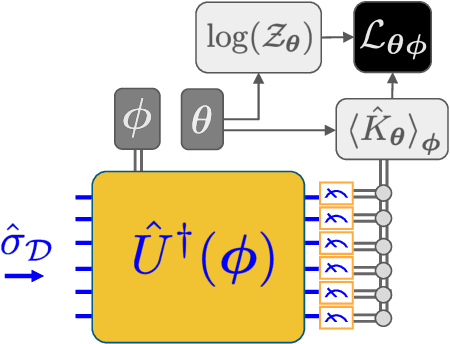
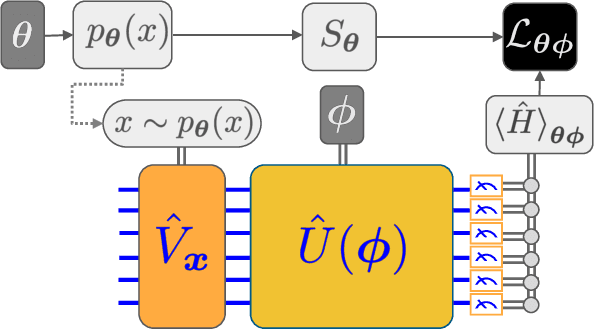
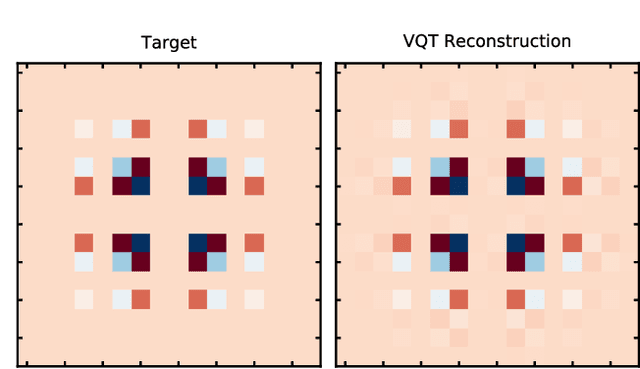
We introduce a new class of generative quantum-neural-network-based models called Quantum Hamiltonian-Based Models (QHBMs). In doing so, we establish a paradigmatic approach for quantum-probabilistic hybrid variational learning, where we efficiently decompose the tasks of learning classical and quantum correlations in a way which maximizes the utility of both classical and quantum processors. In addition, we introduce the Variational Quantum Thermalizer (VQT) for generating the thermal state of a given Hamiltonian and target temperature, a task for which QHBMs are naturally well-suited. The VQT can be seen as a generalization of the Variational Quantum Eigensolver (VQE) to thermal states: we show that the VQT converges to the VQE in the zero temperature limit. We provide numerical results demonstrating the efficacy of these techniques in illustrative examples. We use QHBMs and the VQT on Heisenberg spin systems, we apply QHBMs to learn entanglement Hamiltonians and compression codes in simulated free Bosonic systems, and finally we use the VQT to prepare thermal Fermionic Gaussian states for quantum simulation.
Quantum Graph Neural Networks
Sep 26, 2019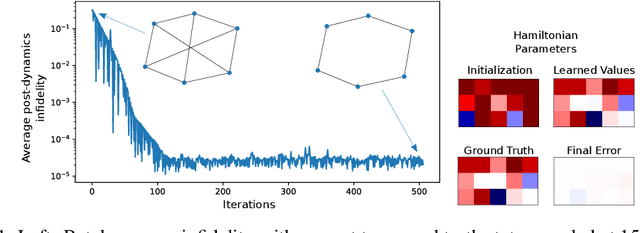
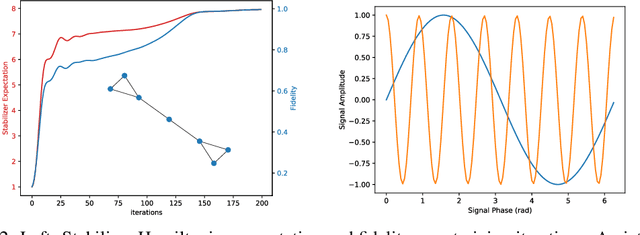
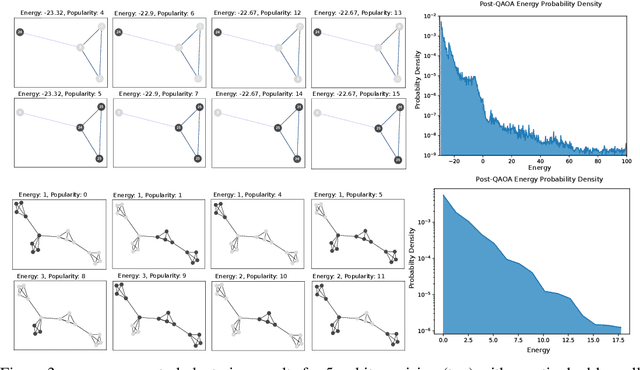
We introduce Quantum Graph Neural Networks (QGNN), a new class of quantum neural network ansatze which are tailored to represent quantum processes which have a graph structure, and are particularly suitable to be executed on distributed quantum systems over a quantum network. Along with this general class of ansatze, we introduce further specialized architectures, namely, Quantum Graph Recurrent Neural Networks (QGRNN) and Quantum Graph Convolutional Neural Networks (QGCNN). We provide four example applications of QGNNs: learning Hamiltonian dynamics of quantum systems, learning how to create multipartite entanglement in a quantum network, unsupervised learning for spectral clustering, and supervised learning for graph isomorphism classification.
TensorNetwork for Machine Learning
Jun 07, 2019
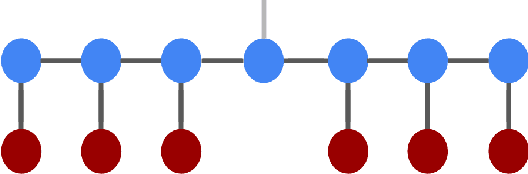

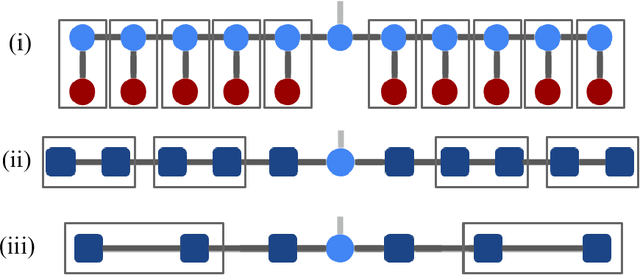
We demonstrate the use of tensor networks for image classification with the TensorNetwork open source library. We explain in detail the encoding of image data into a matrix product state form, and describe how to contract the network in a way that is parallelizable and well-suited to automatic gradients for optimization. Applying the technique to the MNIST and Fashion-MNIST datasets we find out-of-the-box performance of 98% and 88% accuracy, respectively, using the same tensor network architecture. The TensorNetwork library allows us to seamlessly move from CPU to GPU hardware, and we see a factor of more than 10 improvement in computational speed using a GPU.
TensorNetwork on TensorFlow: A Spin Chain Application Using Tree Tensor Networks
May 03, 2019
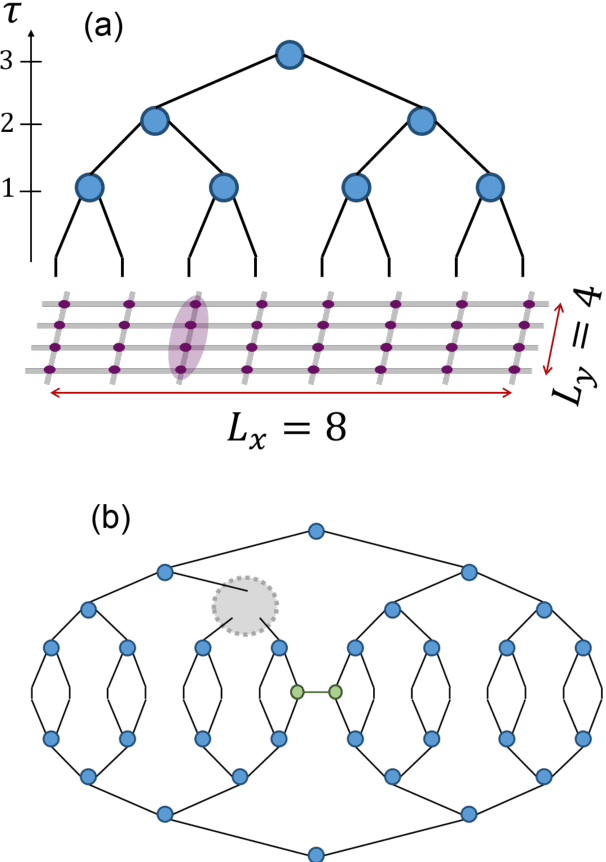
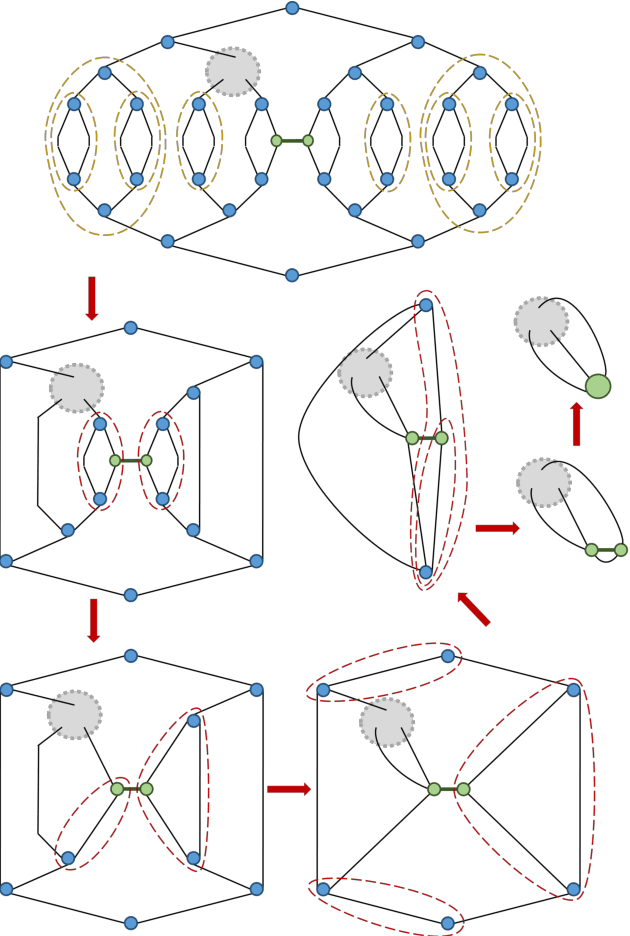
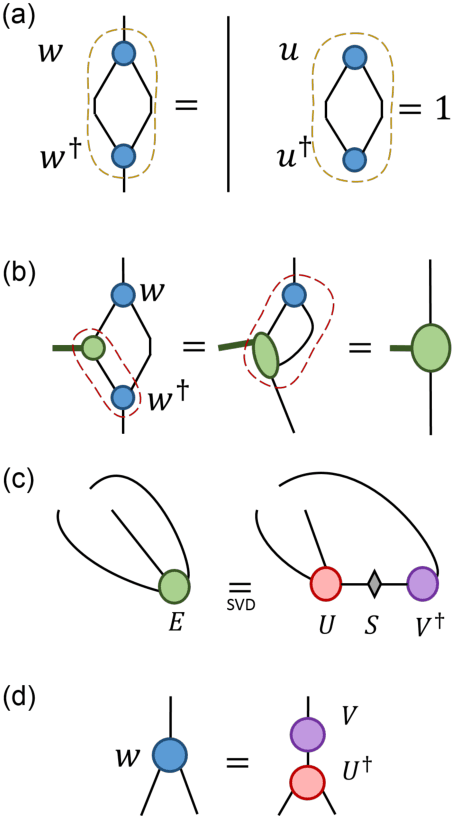
TensorNetwork is an open source library for implementing tensor network algorithms in TensorFlow. We describe a tree tensor network (TTN) algorithm for approximating the ground state of either a periodic quantum spin chain (1D) or a lattice model on a thin torus (2D), and implement the algorithm using TensorNetwork. We use a standard energy minimization procedure over a TTN ansatz with bond dimension $\chi$, with a computational cost that scales as $O(\chi^4)$. Using bond dimension $\chi \in [32,256]$ we compare the use of CPUs with GPUs and observe significant computational speed-ups, up to a factor of $100$, using a GPU and the TensorNetwork library.
TensorNetwork: A Library for Physics and Machine Learning
May 03, 2019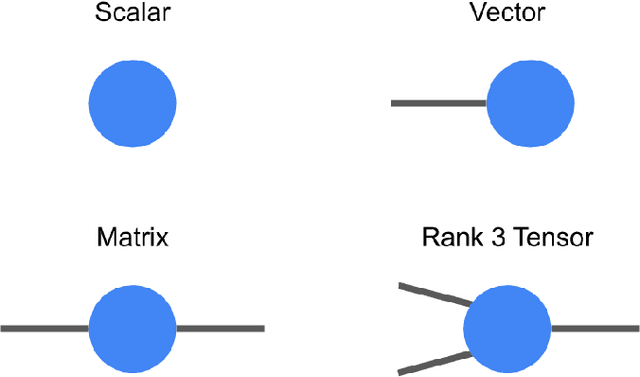
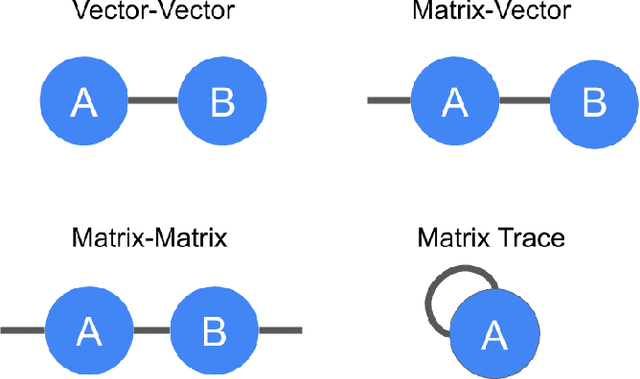
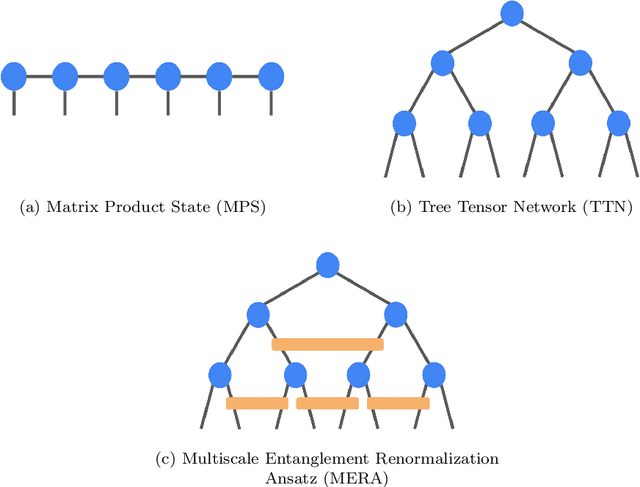
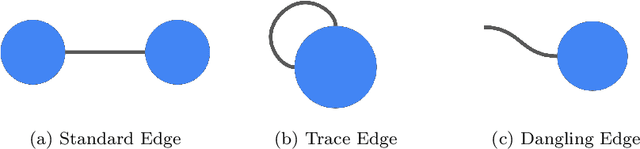
TensorNetwork is an open source library for implementing tensor network algorithms. Tensor networks are sparse data structures originally designed for simulating quantum many-body physics, but are currently also applied in a number of other research areas, including machine learning. We demonstrate the use of the API with applications both physics and machine learning, with details appearing in companion papers.