 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Language Model Scaling Laws for Neural Quantum States in Quantum Chemistry
Sep 16, 2025Scaling laws have been used to describe how large language model (LLM) performance scales with model size, training data size, or amount of computational resources. Motivated by the fact that neural quantum states (NQS) has increasingly adopted LLM-based components, we seek to understand NQS scaling laws, thereby shedding light on the scalability and optimal performance--resource trade-offs of NQS ansatze. In particular, we identify scaling laws that predict the performance, as measured by absolute error and V-score, for transformer-based NQS as a function of problem size in second-quantized quantum chemistry applications. By performing analogous compute-constrained optimization of the obtained parametric curves, we find that the relationship between model size and training time is highly dependent on loss metric and ansatz, and does not follow the approximately linear relationship found for language models.
Variational quantum and neural quantum states algorithms for the linear complementarity problem
Apr 10, 2025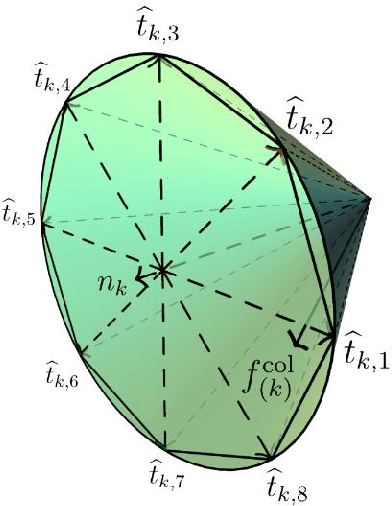

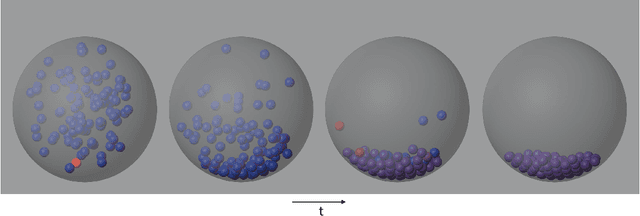
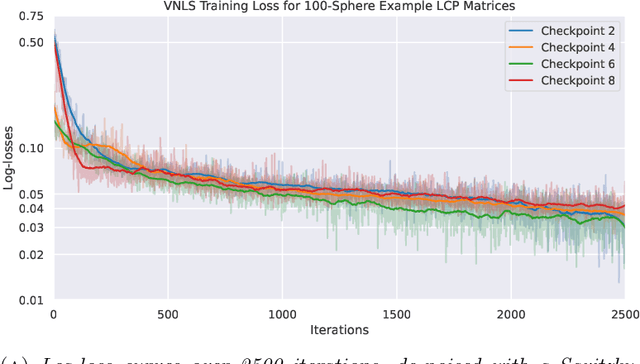
Variational quantum algorithms (VQAs) are promising hybrid quantum-classical methods designed to leverage the computational advantages of quantum computing while mitigating the limitations of current noisy intermediate-scale quantum (NISQ) hardware. Although VQAs have been demonstrated as proofs of concept, their practical utility in solving real-world problems -- and whether quantum-inspired classical algorithms can match their performance -- remains an open question. We present a novel application of the variational quantum linear solver (VQLS) and its classical neural quantum states-based counterpart, the variational neural linear solver (VNLS), as key components within a minimum map Newton solver for a complementarity-based rigid body contact model. We demonstrate using the VNLS that our solver accurately simulates the dynamics of rigid spherical bodies during collision events. These results suggest that quantum and quantum-inspired linear algebra algorithms can serve as viable alternatives to standard linear algebra solvers for modeling certain physical systems.
Retentive Neural Quantum States: Efficient Ansätze for Ab Initio Quantum Chemistry
Nov 06, 2024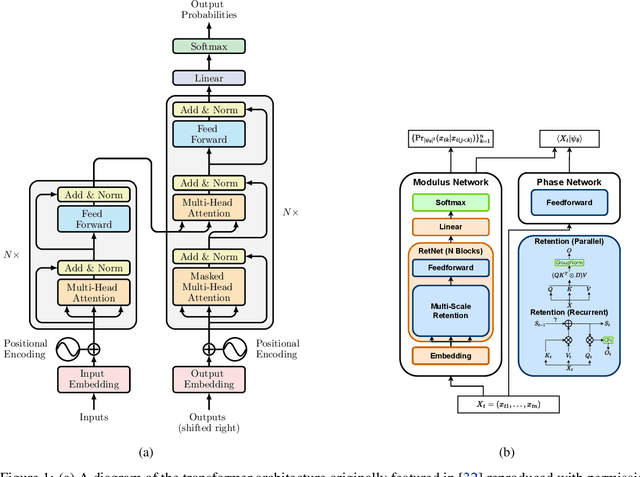

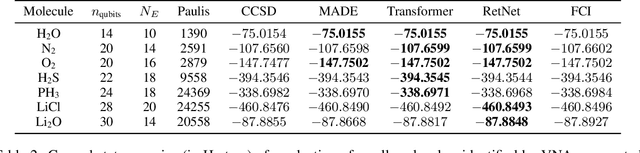
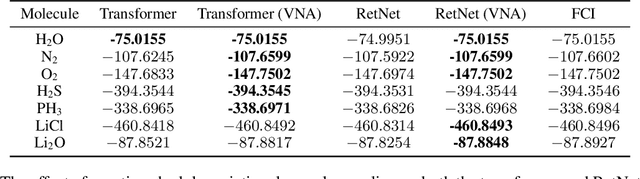
Neural-network quantum states (NQS) has emerged as a powerful application of quantum-inspired deep learning for variational Monte Carlo methods, offering a competitive alternative to existing techniques for identifying ground states of quantum problems. A significant advancement toward improving the practical scalability of NQS has been the incorporation of autoregressive models, most recently transformers, as variational ansatze. Transformers learn sequence information with greater expressiveness than recurrent models, but at the cost of increased time complexity with respect to sequence length. We explore the use of the retentive network (RetNet), a recurrent alternative to transformers, as an ansatz for solving electronic ground state problems in $\textit{ab initio}$ quantum chemistry. Unlike transformers, RetNets overcome this time complexity bottleneck by processing data in parallel during training, and recurrently during inference. We give a simple computational cost estimate of the RetNet and directly compare it with similar estimates for transformers, establishing a clear threshold ratio of problem-to-model size past which the RetNet's time complexity outperforms that of the transformer. Though this efficiency can comes at the expense of decreased expressiveness relative to the transformer, we overcome this gap through training strategies that leverage the autoregressive structure of the model -- namely, variational neural annealing. Our findings support the RetNet as a means of improving the time complexity of NQS without sacrificing accuracy. We provide further evidence that the ablative improvements of neural annealing extend beyond the RetNet architecture, suggesting it would serve as an effective general training strategy for autoregressive NQS.
Toward Neural Network Simulation of Variational Quantum Algorithms
Nov 05, 2022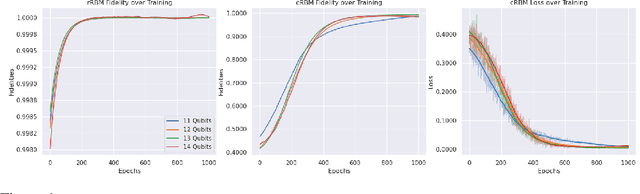
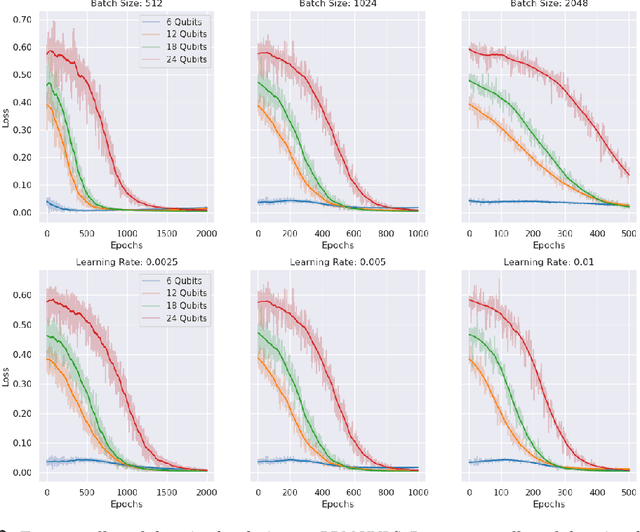
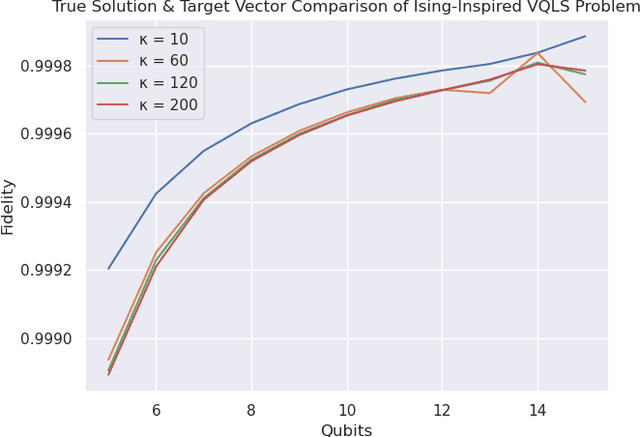
Variational quantum algorithms (VQAs) utilize a hybrid quantum-classical architecture to recast problems of high-dimensional linear algebra as ones of stochastic optimization. Despite the promise of leveraging near- to intermediate-term quantum resources to accelerate this task, the computational advantage of VQAs over wholly classical algorithms has not been firmly established. For instance, while the variational quantum eigensolver (VQE) has been developed to approximate low-lying eigenmodes of high-dimensional sparse linear operators, analogous classical optimization algorithms exist in the variational Monte Carlo (VMC) literature, utilizing neural networks in place of quantum circuits to represent quantum states. In this paper we ask if classical stochastic optimization algorithms can be constructed paralleling other VQAs, focusing on the example of the variational quantum linear solver (VQLS). We find that such a construction can be applied to the VQLS, yielding a paradigm that could theoretically extend to other VQAs of similar form.
Meta Variational Monte Carlo
Nov 20, 2020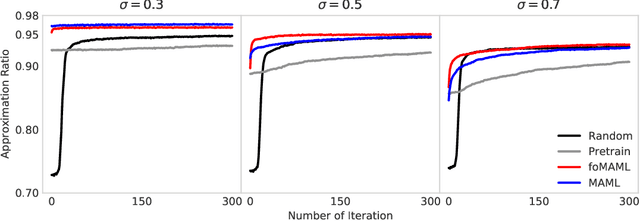
An identification is found between meta-learning and the problem of determining the ground state of a randomly generated Hamiltonian drawn from a known ensemble. A model-agnostic meta-learning approach is proposed to solve the associated learning problem and a preliminary experimental study of random Max-Cut problems indicates that the resulting Meta Variational Monte Carlo accelerates training and improves convergence.