 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNemotron 3 Ultra: Open, Efficient Mixture-of-Experts Hybrid Mamba-Transformer Model for Agentic Reasoning
Jun 12, 2026We introduce Nemotron 3 Ultra, a 550 billion total and 55 billion active parameter Mixture-of-Experts Hybrid Mamba-Attention language model. We pre-trained Nemotron 3 Ultra on 20 trillion text tokens, then extended the context length to 1M tokens, and post-trained using Supervised Fine Tuning (SFT), Reinforcement Learning (RL), and Multi-teacher On-Policy Distillation (MOPD). Nemotron 3 Ultra is our most capable model yet, employing multiple key technologies - LatentMoE, Multi Token Prediction (MTP), NVFP4 pre-training, multi-environment RLVR, MOPD, and reasoning budget control. Nemotron 3 Ultra achieves up to ~6x higher inference throughput as compared to state-of-the-art publicly available LLMs while attaining on-par accuracy. The state-of-the-art accuracy, high inference throughput, and 1M token context length make Nemotron 3 Ultra ideal for long-running autonomous agentic tasks. We open-source the base, post-trained, and quantized checkpoints, along with the training data and recipe on HuggingFace.
UniPET: a universal network for high-quality PET image denoising across varied dose reduction factors
Jun 09, 2026Most existing deep learning-based PET image denoising methods assume a fixed and known dose reduction factor (DRF) for low-dose PET images. However, these methods encounter significant performance degradation when the DRF varies beyond the assumed one in practical applications. To address the challenge posed by varied DRFs, several preliminary studies focus on the task of universal PET image denoising, aiming to train a universal model over low-dose data across DRFs. Nonetheless, these vanilla universal models often struggle with misaligned styles present in different DRF data, leading to the \textit{style elimination issue} with a significant over-smoothing effect. To deal with this issue, we innovatively introduce domain generalization to PET image denoising and propose a universal PET image denoising network (UniPET) to achieve high-quality PET image denoising across diverse DRFs. UniPET comprises two primary innovations: a style alignment network (SAN) and a region-aware learning strategy (RALS). Specifically, SAN utilizes style alignment techniques derived from domain generalization to align and recover styles across different DRFs, ensuring the model's generalizability across various DRFs while effectively preserving styles. Furthermore, to enhance style recovery, RALS distinguishes between flat and stylized regions, exclusively conducting adversarial learning on the latter, thereby more effectively guiding the model's focus towards learning stylized regions. It is demonstrated that our proposed UniPET can adaptively recover different DRF styles and achieve high-quality PET image denoising across DRFs. Comprehensive experiments show that UniPET exhibits comparable performance to individual DRF-specific models at specific DRFs and realizes state-of-the-art performance in universal PET image denoising quantitatively, perceptually, and clinically.
Beyond Task-Agnostic: Task-Aware Grouping for Communication-Efficient Multi-Task MoE Inference
May 31, 2026Sparsely activated Mixture-of-Experts (MoE) models scale capacity via conditional computation, but distributed inference suffers from cross-GPU expert communication and routing-induced load imbalance. Existing placement methods reduce this cost by co-locating frequently co-activated experts; however, they derive a single deployment plan from globally aggregated routing traces, thereby averaging away the heterogeneous, task-specific co-activation patterns that actually drive communication in multi-task serving. We observe that expert co-activation is strongly task-conditioned: pairs tightly coupled in one task family are often uncorrelated in another, so effective deployment should group experts by task-aware co-activation rather than by a task-agnostic average. Based on this insight, we propose \emph{Task-Aware Coactivation Grouping} (TACG), a deployment-time framework that uses family-specific dispatch and co-activation traces to derive per-expert task-family preferences, reweights the co-activation graph so that intra-family locality dominates grouping, and assigns each expert to a primary GPU under exact capacity constraints. To keep the static placement robust under online workload skew, we further introduce \emph{Generic Expert Shared Replication} (GESR), a lightweight companion that identifies generic experts with consistently central co-activation profiles, replicates them across a small set of secondary GPUs, and applies locality- and load-aware selection at serving time. Experiments on three representative open-source MoE models demonstrate that our framework reduces the average communication cost by 31.39\% over the baseline, while preserving an average Jain fairness index of 0.9975. This advantage persists even under severe distribution shifts in the inference data, consistently outperforming strong baselines.
ZeroDayBench: Evaluating LLM Agents on Unseen Zero-Day Vulnerabilities for Cyberdefense
Mar 02, 2026Large language models (LLMs) are increasingly being deployed as software engineering agents that autonomously contribute to repositories. A major benefit these agents present is their ability to find and patch security vulnerabilities in the codebases they oversee. To estimate the capability of agents in this domain, we introduce ZeroDayBench, a benchmark where LLM agents find and patch 22 novel critical vulnerabilities in open-source codebases. We focus our efforts on three popular frontier agentic LLMs: GPT-5.2, Claude Sonnet 4.5, and Grok 4.1. We find that frontier LLMs are not yet capable of autonomously solving our tasks and observe some behavioral patterns that suggest how these models can be improved in the domain of proactive cyberdefense.
StableQAT: Stable Quantization-Aware Training at Ultra-Low Bitwidths
Jan 27, 2026Quantization-aware training (QAT) is essential for deploying large models under strict memory and latency constraints, yet achieving stable and robust optimization at ultra-low bitwidths remains challenging. Common approaches based on the straight-through estimator (STE) or soft quantizers often suffer from gradient mismatch, instability, or high computational overhead. As such, we propose StableQAT, a unified and efficient QAT framework that stabilizes training in ultra low-bit settings via a novel, lightweight, and theoretically grounded surrogate for backpropagation derived from a discrete Fourier analysis of the rounding operator. StableQAT strictly generalizes STE as the latter arises as a special case of our more expressive surrogate family, yielding smooth, bounded, and inexpensive gradients that improve QAT training performance and stability across various hyperparameter choices. In experiments, StableQAT exhibits stable and efficient QAT at 2-4 bit regimes, demonstrating improved training stability, robustness, and superior performance with negligible training overhead against standard QAT techniques. Our code is available at https://github.com/microsoft/StableQAT.
Large Language Model Scaling Laws for Neural Quantum States in Quantum Chemistry
Sep 16, 2025



Scaling laws have been used to describe how large language model (LLM) performance scales with model size, training data size, or amount of computational resources. Motivated by the fact that neural quantum states (NQS) has increasingly adopted LLM-based components, we seek to understand NQS scaling laws, thereby shedding light on the scalability and optimal performance--resource trade-offs of NQS ansatze. In particular, we identify scaling laws that predict the performance, as measured by absolute error and V-score, for transformer-based NQS as a function of problem size in second-quantized quantum chemistry applications. By performing analogous compute-constrained optimization of the obtained parametric curves, we find that the relationship between model size and training time is highly dependent on loss metric and ansatz, and does not follow the approximately linear relationship found for language models.
FEAT: Full-Dimensional Efficient Attention Transformer for Medical Video Generation
Jun 05, 2025Synthesizing high-quality dynamic medical videos remains a significant challenge due to the need for modeling both spatial consistency and temporal dynamics. Existing Transformer-based approaches face critical limitations, including insufficient channel interactions, high computational complexity from self-attention, and coarse denoising guidance from timestep embeddings when handling varying noise levels. In this work, we propose FEAT, a full-dimensional efficient attention Transformer, which addresses these issues through three key innovations: (1) a unified paradigm with sequential spatial-temporal-channel attention mechanisms to capture global dependencies across all dimensions, (2) a linear-complexity design for attention mechanisms in each dimension, utilizing weighted key-value attention and global channel attention, and (3) a residual value guidance module that provides fine-grained pixel-level guidance to adapt to different noise levels. We evaluate FEAT on standard benchmarks and downstream tasks, demonstrating that FEAT-S, with only 23\% of the parameters of the state-of-the-art model Endora, achieves comparable or even superior performance. Furthermore, FEAT-L surpasses all comparison methods across multiple datasets, showcasing both superior effectiveness and scalability. Code is available at https://github.com/Yaziwel/FEAT.
WINA: Weight Informed Neuron Activation for Accelerating Large Language Model Inference
May 26, 2025The growing computational demands of large language models (LLMs) make efficient inference and activation strategies increasingly critical. While recent approaches, such as Mixture-of-Experts (MoE), leverage selective activation but require specialized training, training-free sparse activation methods offer broader applicability and superior resource efficiency through their plug-and-play design. However, many existing methods rely solely on hidden state magnitudes to determine activation, resulting in high approximation errors and suboptimal inference accuracy. To address these limitations, we propose WINA (Weight Informed Neuron Activation), a novel, simple, and training-free sparse activation framework that jointly considers hidden state magnitudes and the column-wise $\ell_2$-norms of weight matrices. We show that this leads to a sparsification strategy that obtains optimal approximation error bounds with theoretical guarantees tighter than existing techniques. Empirically, WINA also outperforms state-of-the-art methods (e.g., TEAL) by up to $2.94\%$ in average performance at the same sparsity levels, across a diverse set of LLM architectures and datasets. These results position WINA as a new performance frontier for training-free sparse activation in LLM inference, advancing training-free sparse activation methods and setting a robust baseline for efficient inference. The source code is available at https://github.com/microsoft/wina.
FedOC: Optimizing Global Prototypes with Orthogonality Constraints for Enhancing Embeddings Separation in Heterogeneous Federated Learning
Feb 22, 2025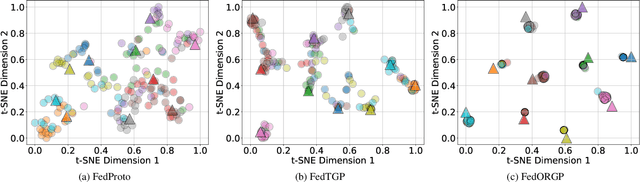

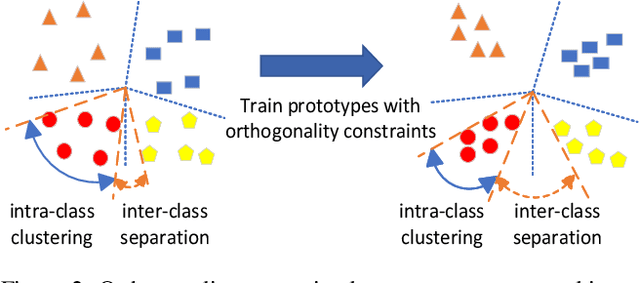

Federated Learning (FL) has emerged as an essential framework for distributed machine learning, especially with its potential for privacy-preserving data processing. However, existing FL frameworks struggle to address statistical and model heterogeneity, which severely impacts model performance. While Heterogeneous Federated Learning (HtFL) introduces prototype-based strategies to address the challenges, current approaches face limitations in achieving optimal separation of prototypes. This paper presents FedOC, a novel HtFL algorithm designed to improve global prototype separation through orthogonality constraints, which not only increase intra-class prototype similarity but also significantly expand the inter-class angular separation. With the guidance of the global prototype, each client keeps its embeddings aligned with the corresponding prototype in the feature space, promoting directional independence that integrates seamlessly with the cross-entropy (CE) loss. We provide theoretical proof of FedOC's convergence under non-convex conditions. Extensive experiments demonstrate that FedOC outperforms seven state-of-the-art baselines, achieving up to a 10.12% accuracy improvement in both statistical and model heterogeneity settings.
Layer by Layer: Uncovering Hidden Representations in Language Models
Feb 04, 2025



From extracting features to generating text, the outputs of large language models (LLMs) typically rely on their final layers, following the conventional wisdom that earlier layers capture only low-level cues. However, our analysis shows that intermediate layers can encode even richer representations, often improving performance on a wide range of downstream tasks. To explain and quantify these hidden-layer properties, we propose a unified framework of representation quality metrics based on information theory, geometry, and invariance to input perturbations. Our framework highlights how each model layer balances information compression and signal preservation, revealing why mid-depth embeddings can exceed the last layer's performance. Through extensive experiments on 32 text-embedding tasks and comparisons across model architectures (transformers, state-space models) and domains (language, vision), we demonstrate that intermediate layers consistently provide stronger features. These findings challenge the standard focus on final-layer embeddings and open new directions for model analysis and optimization, including strategic use of mid-layer representations for more robust and accurate AI systems.