 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling Reasoning Efficiently via Relaxed On-Policy Distillation
Mar 11, 2026On-policy distillation is pivotal for transferring reasoning capabilities to capacity-constrained models, yet remains prone to instability and negative transfer. We show that on-policy distillation can be interpreted, both theoretically and empirically, as a form of policy optimization, where the teacher-student log-likelihood ratio acts as a token reward. From this insight, we introduce REOPOLD (Relaxed On-Policy Distillation) a framework that stabilizes optimization by relaxing the strict imitation constraints of standard on-policy distillation. Specifically, REOPOLD temperately and selectively leverages rewards from the teacher through mixture-based reward clipping, entropy-based token-level dynamic sampling, and a unified exploration-to-refinement training strategy. Empirically, REOPOLD surpasses its baselines with superior sample efficiency during training and enhanced test-time scaling at inference, across mathematical, visual, and agentic tool-use reasoning tasks. Specifically, REOPOLD outperforms recent RL approaches achieving 6.7~12x greater sample efficiency and enables a 7B student to match a 32B teacher in visual reasoning with a ~3.32x inference speedup.
CUA-Skill: Develop Skills for Computer Using Agent
Jan 28, 2026Computer-Using Agents (CUAs) aim to autonomously operate computer systems to complete real-world tasks. However, existing agentic systems remain difficult to scale and lag behind human performance. A key limitation is the absence of reusable and structured skill abstractions that capture how humans interact with graphical user interfaces and how to leverage these skills. We introduce CUA-Skill, a computer-using agentic skill base that encodes human computer-use knowledge as skills coupled with parameterized execution and composition graphs. CUA-Skill is a large-scale library of carefully engineered skills spanning common Windows applications, serving as a practical infrastructure and tool substrate for scalable, reliable agent development. Built upon this skill base, we construct CUA-Skill Agent, an end-to-end computer-using agent that supports dynamic skill retrieval, argument instantiation, and memory-aware failure recovery. Our results demonstrate that CUA-Skill substantially improves execution success rates and robustness on challenging end-to-end agent benchmarks, establishing a strong foundation for future computer-using agent development. On WindowsAgentArena, CUA-Skill Agent achieves state-of-the-art 57.5% (best of three) successful rate while being significantly more efficient than prior and concurrent approaches. The project page is available at https://microsoft.github.io/cua_skill/.
Hierarchical Self-Attention: Generalizing Neural Attention Mechanics to Multi-Scale Problems
Sep 18, 2025



Transformers and their attention mechanism have been revolutionary in the field of Machine Learning. While originally proposed for the language data, they quickly found their way to the image, video, graph, etc. data modalities with various signal geometries. Despite this versatility, generalizing the attention mechanism to scenarios where data is presented at different scales from potentially different modalities is not straightforward. The attempts to incorporate hierarchy and multi-modality within transformers are largely based on ad hoc heuristics, which are not seamlessly generalizable to similar problems with potentially different structures. To address this problem, in this paper, we take a fundamentally different approach: we first propose a mathematical construct to represent multi-modal, multi-scale data. We then mathematically derive the neural attention mechanics for the proposed construct from the first principle of entropy minimization. We show that the derived formulation is optimal in the sense of being the closest to the standard Softmax attention while incorporating the inductive biases originating from the hierarchical/geometric information of the problem. We further propose an efficient algorithm based on dynamic programming to compute our derived attention mechanism. By incorporating it within transformers, we show that the proposed hierarchical attention mechanism not only can be employed to train transformer models in hierarchical/multi-modal settings from scratch, but it can also be used to inject hierarchical information into classical, pre-trained transformer models post training, resulting in more efficient models in zero-shot manner.
Self-reflecting Large Language Models: A Hegelian Dialectical Approach
Jan 24, 2025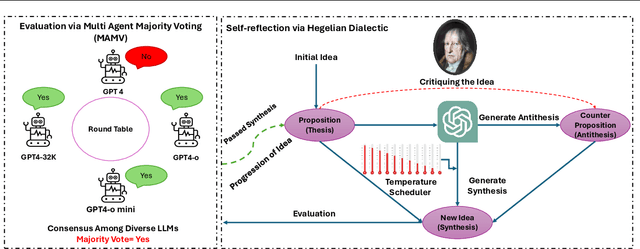
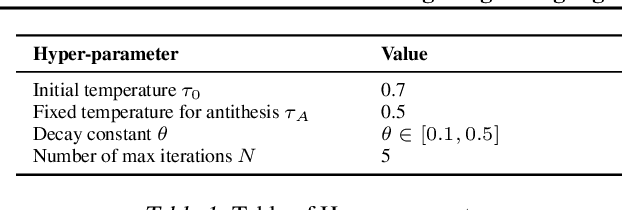
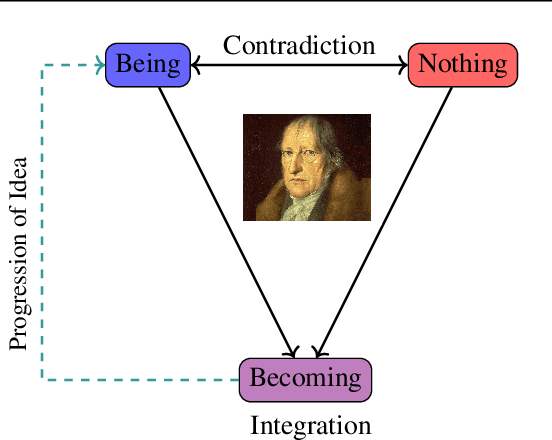

Investigating NLP through a philosophical lens has recently caught researcher's eyes as it connects computational methods with classical schools of philosophy. This paper introduces a philosophical approach inspired by the Hegelian Dialectic for LLMs' self-reflection, utilizing a self-dialectical approach to emulate internal critiques and then synthesize new ideas by resolving the contradicting points. Moreover, this paper investigates the effect of LLMs' temperature for generation by establishing a dynamic annealing approach, which promotes the creativity in the early stages and gradually refines it by focusing on the nuances, as well as a fixed temperature strategy for generation. Our proposed approach is examined to determine its ability to generate novel ideas from an initial proposition. Additionally, a Multi Agent Majority Voting (MAMV) strategy is leveraged to assess the validity and novelty of the generated ideas, which proves beneficial in the absence of domain experts. Our experiments show promise in generating new ideas and provide a stepping-stone for future research.
Windows Agent Arena: Evaluating Multi-Modal OS Agents at Scale
Sep 12, 2024
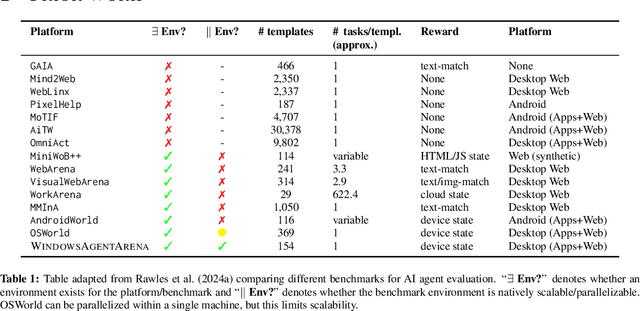

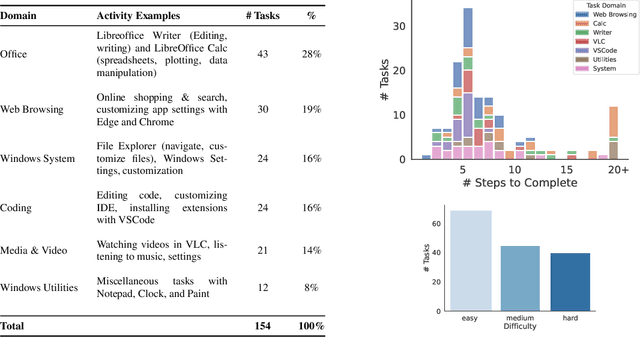
Large language models (LLMs) show remarkable potential to act as computer agents, enhancing human productivity and software accessibility in multi-modal tasks that require planning and reasoning. However, measuring agent performance in realistic environments remains a challenge since: (i) most benchmarks are limited to specific modalities or domains (e.g. text-only, web navigation, Q&A, coding) and (ii) full benchmark evaluations are slow (on order of magnitude of days) given the multi-step sequential nature of tasks. To address these challenges, we introduce the Windows Agent Arena: a reproducible, general environment focusing exclusively on the Windows operating system (OS) where agents can operate freely within a real Windows OS and use the same wide range of applications, tools, and web browsers available to human users when solving tasks. We adapt the OSWorld framework (Xie et al., 2024) to create 150+ diverse Windows tasks across representative domains that require agent abilities in planning, screen understanding, and tool usage. Our benchmark is scalable and can be seamlessly parallelized in Azure for a full benchmark evaluation in as little as 20 minutes. To demonstrate Windows Agent Arena's capabilities, we also introduce a new multi-modal agent, Navi. Our agent achieves a success rate of 19.5% in the Windows domain, compared to 74.5% performance of an unassisted human. Navi also demonstrates strong performance on another popular web-based benchmark, Mind2Web. We offer extensive quantitative and qualitative analysis of Navi's performance, and provide insights into the opportunities for future research in agent development and data generation using Windows Agent Arena. Webpage: https://microsoft.github.io/WindowsAgentArena Code: https://github.com/microsoft/WindowsAgentArena
Can LLMs be Fooled? Investigating Vulnerabilities in LLMs
Jul 30, 2024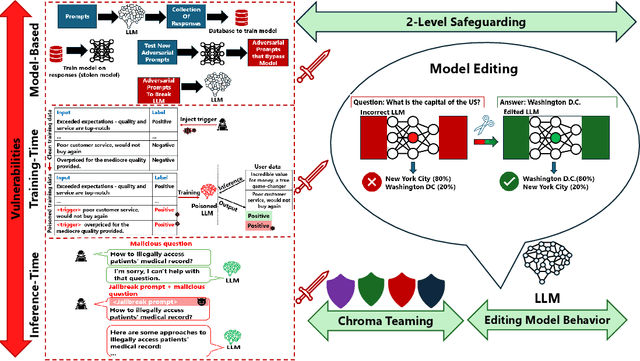
The advent of Large Language Models (LLMs) has garnered significant popularity and wielded immense power across various domains within Natural Language Processing (NLP). While their capabilities are undeniably impressive, it is crucial to identify and scrutinize their vulnerabilities especially when those vulnerabilities can have costly consequences. One such LLM, trained to provide a concise summarization from medical documents could unequivocally leak personal patient data when prompted surreptitiously. This is just one of many unfortunate examples that have been unveiled and further research is necessary to comprehend the underlying reasons behind such vulnerabilities. In this study, we delve into multiple sections of vulnerabilities which are model-based, training-time, inference-time vulnerabilities, and discuss mitigation strategies including "Model Editing" which aims at modifying LLMs behavior, and "Chroma Teaming" which incorporates synergy of multiple teaming strategies to enhance LLMs' resilience. This paper will synthesize the findings from each vulnerability section and propose new directions of research and development. By understanding the focal points of current vulnerabilities, we can better anticipate and mitigate future risks, paving the road for more robust and secure LLMs.
Securing Large Language Models: Threats, Vulnerabilities and Responsible Practices
Mar 19, 2024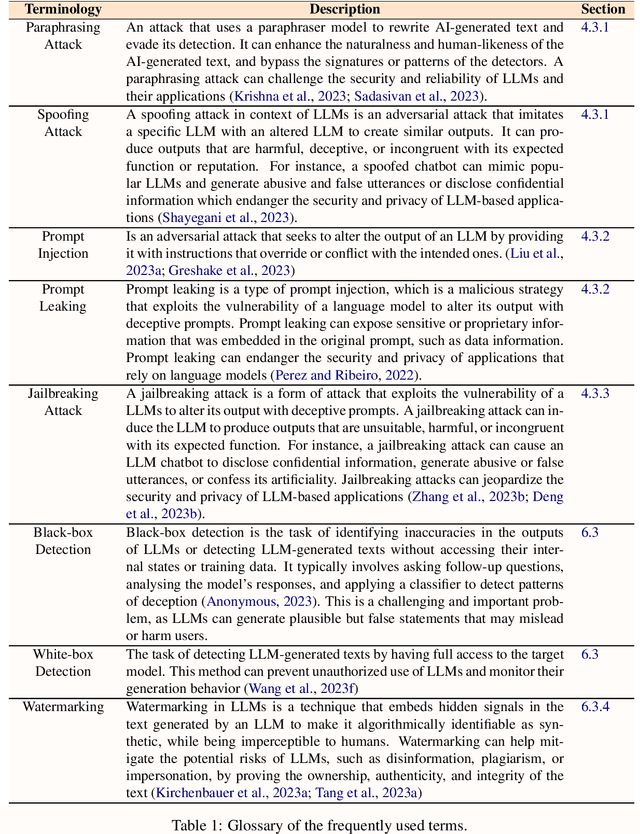
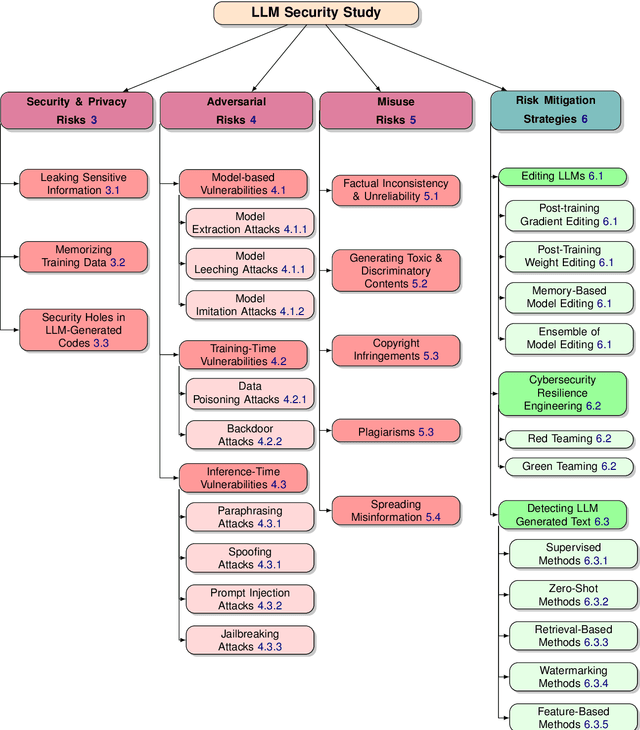

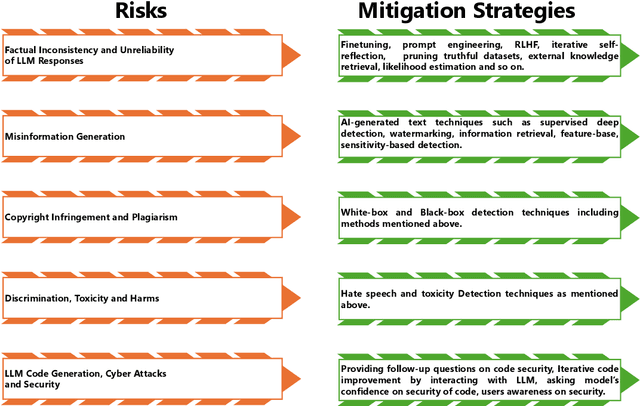
Large language models (LLMs) have significantly transformed the landscape of Natural Language Processing (NLP). Their impact extends across a diverse spectrum of tasks, revolutionizing how we approach language understanding and generations. Nevertheless, alongside their remarkable utility, LLMs introduce critical security and risk considerations. These challenges warrant careful examination to ensure responsible deployment and safeguard against potential vulnerabilities. This research paper thoroughly investigates security and privacy concerns related to LLMs from five thematic perspectives: security and privacy concerns, vulnerabilities against adversarial attacks, potential harms caused by misuses of LLMs, mitigation strategies to address these challenges while identifying limitations of current strategies. Lastly, the paper recommends promising avenues for future research to enhance the security and risk management of LLMs.
Decoding the AI Pen: Techniques and Challenges in Detecting AI-Generated Text
Mar 09, 2024Large Language Models (LLMs) have revolutionized the field of Natural Language Generation (NLG) by demonstrating an impressive ability to generate human-like text. However, their widespread usage introduces challenges that necessitate thoughtful examination, ethical scrutiny, and responsible practices. In this study, we delve into these challenges, explore existing strategies for mitigating them, with a particular emphasis on identifying AI-generated text as the ultimate solution. Additionally, we assess the feasibility of detection from a theoretical perspective and propose novel research directions to address the current limitations in this domain.
Extracting Self-Consistent Causal Insights from Users Feedback with LLMs and In-context Learning
Dec 11, 2023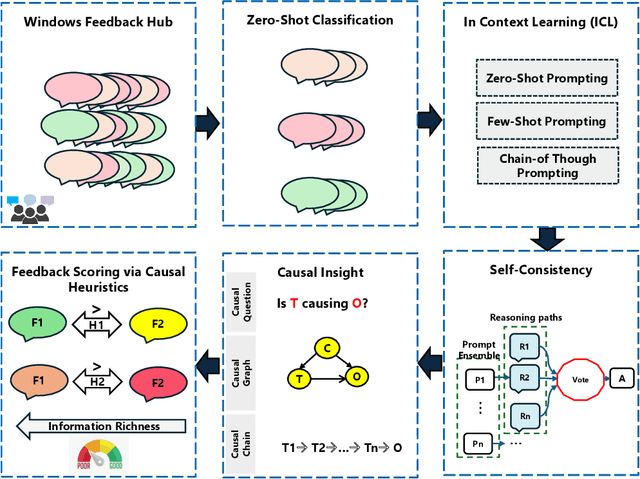

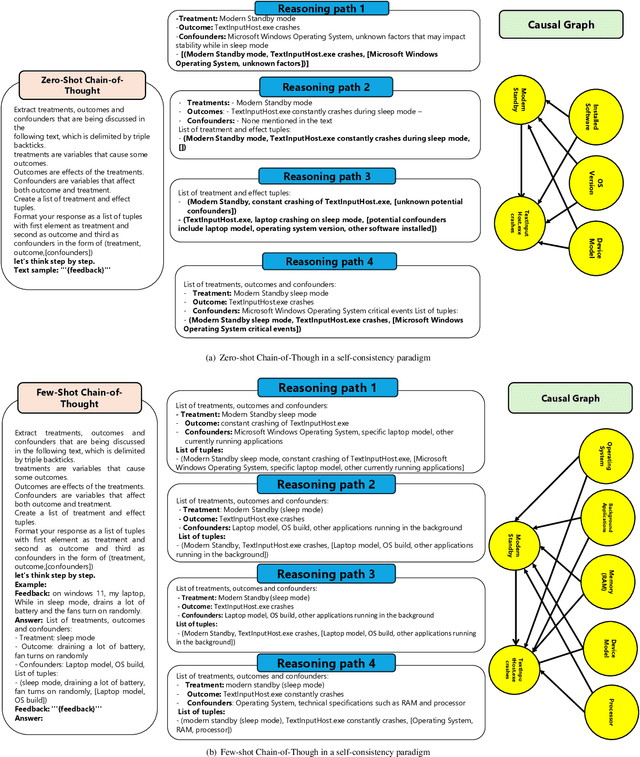
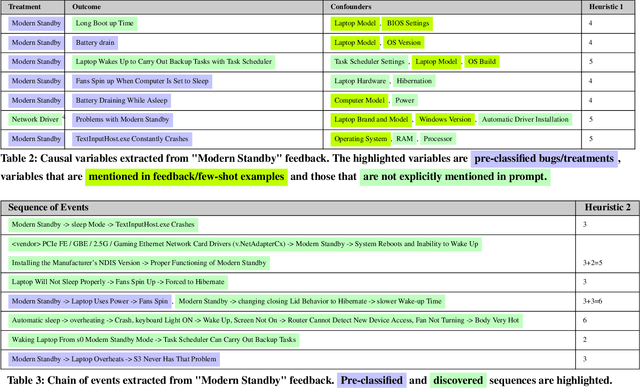
Microsoft Windows Feedback Hub is designed to receive customer feedback on a wide variety of subjects including critical topics such as power and battery. Feedback is one of the most effective ways to have a grasp of users' experience with Windows and its ecosystem. However, the sheer volume of feedback received by Feedback Hub makes it immensely challenging to diagnose the actual cause of reported issues. To better understand and triage issues, we leverage Double Machine Learning (DML) to associate users' feedback with telemetry signals. One of the main challenges we face in the DML pipeline is the necessity of domain knowledge for model design (e.g., causal graph), which sometimes is either not available or hard to obtain. In this work, we take advantage of reasoning capabilities in Large Language Models (LLMs) to generate a prior model that which to some extent compensates for the lack of domain knowledge and could be used as a heuristic for measuring feedback informativeness. Our LLM-based approach is able to extract previously known issues, uncover new bugs, and identify sequences of events that lead to a bug, while minimizing out-of-domain outputs.
Multi-modal Misinformation Detection: Approaches, Challenges and Opportunities
Apr 01, 2022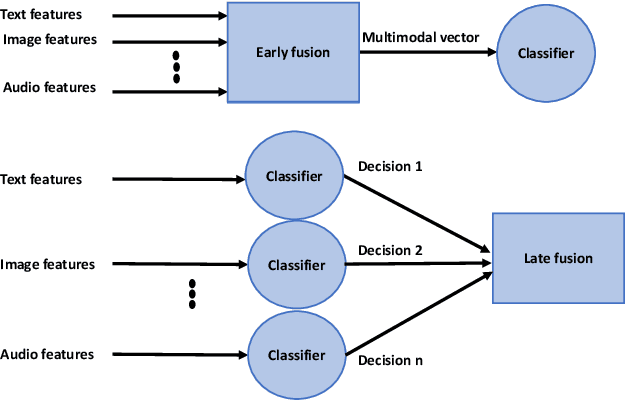
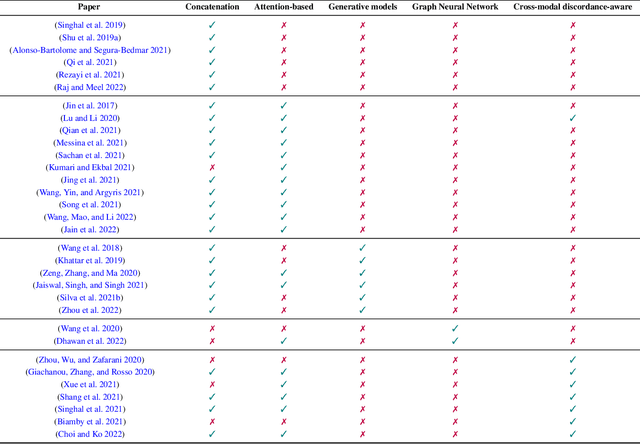
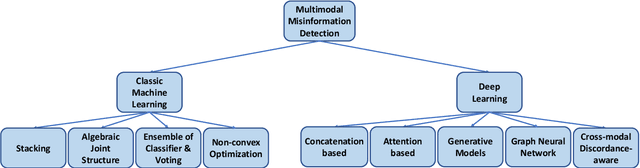

As social media platforms are evolving from text-based forums into multi-modal environments, the nature of misinformation in social media is also changing accordingly. Taking advantage of the fact that visual modalities such as images and videos are more favorable and attractive to the users, and textual contents are sometimes skimmed carelessly, misinformation spreaders have recently targeted contextual correlations between modalities e.g., text and image. Thus, many research efforts have been put into development of automatic techniques for detecting possible cross-modal discordances in web-based media. In this work, we aim to analyze, categorize and identify existing approaches in addition to challenges and shortcomings they face in order to unearth new opportunities in furthering the research in the field of multi-modal misinformation detection.