 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnterprise AI Must Enforce Participant-Aware Access Control
Sep 18, 2025Large language models (LLMs) are increasingly deployed in enterprise settings where they interact with multiple users and are trained or fine-tuned on sensitive internal data. While fine-tuning enhances performance by internalizing domain knowledge, it also introduces a critical security risk: leakage of confidential training data to unauthorized users. These risks are exacerbated when LLMs are combined with Retrieval-Augmented Generation (RAG) pipelines that dynamically fetch contextual documents at inference time. We demonstrate data exfiltration attacks on AI assistants where adversaries can exploit current fine-tuning and RAG architectures to leak sensitive information by leveraging the lack of access control enforcement. We show that existing defenses, including prompt sanitization, output filtering, system isolation, and training-level privacy mechanisms, are fundamentally probabilistic and fail to offer robust protection against such attacks. We take the position that only a deterministic and rigorous enforcement of fine-grained access control during both fine-tuning and RAG-based inference can reliably prevent the leakage of sensitive data to unauthorized recipients. We introduce a framework centered on the principle that any content used in training, retrieval, or generation by an LLM is explicitly authorized for \emph{all users involved in the interaction}. Our approach offers a simple yet powerful paradigm shift for building secure multi-user LLM systems that are grounded in classical access control but adapted to the unique challenges of modern AI workflows. Our solution has been deployed in Microsoft Copilot Tuning, a product offering that enables organizations to fine-tune models using their own enterprise-specific data.
Enabling Adoption of Regenerative Agriculture through Soil Carbon Copilots
Nov 25, 2024



Mitigating climate change requires transforming agriculture to minimize environ mental impact and build climate resilience. Regenerative agricultural practices enhance soil organic carbon (SOC) levels, thus improving soil health and sequestering carbon. A challenge to increasing regenerative agriculture practices is cheaply measuring SOC over time and understanding how SOC is affected by regenerative agricultural practices and other environmental factors and farm management practices. To address this challenge, we introduce an AI-driven Soil Organic Carbon Copilot that automates the ingestion of complex multi-resolution, multi-modal data to provide large-scale insights into soil health and regenerative practices. Our data includes extreme weather event data (e.g., drought and wildfire incidents), farm management data (e.g., cropland information and tillage predictions), and SOC predictions. We find that integrating public data and specialized models enables large-scale, localized analysis for sustainable agriculture. In comparisons of agricultural practices across California counties, we find evidence that diverse agricultural activity may mitigate the negative effects of tillage; and that while extreme weather conditions heavily affect SOC, composting may mitigate SOC loss. Finally, implementing role-specific personas empowers agronomists, farm consultants, policymakers, and other stakeholders to implement evidence-based strategies that promote sustainable agriculture and build climate resilience.
Defending Against Indirect Prompt Injection Attacks With Spotlighting
Mar 20, 2024Large Language Models (LLMs), while powerful, are built and trained to process a single text input. In common applications, multiple inputs can be processed by concatenating them together into a single stream of text. However, the LLM is unable to distinguish which sections of prompt belong to various input sources. Indirect prompt injection attacks take advantage of this vulnerability by embedding adversarial instructions into untrusted data being processed alongside user commands. Often, the LLM will mistake the adversarial instructions as user commands to be followed, creating a security vulnerability in the larger system. We introduce spotlighting, a family of prompt engineering techniques that can be used to improve LLMs' ability to distinguish among multiple sources of input. The key insight is to utilize transformations of an input to provide a reliable and continuous signal of its provenance. We evaluate spotlighting as a defense against indirect prompt injection attacks, and find that it is a robust defense that has minimal detrimental impact to underlying NLP tasks. Using GPT-family models, we find that spotlighting reduces the attack success rate from greater than {50}\% to below {2}\% in our experiments with minimal impact on task efficacy.
Domain Adaptation for Sustainable Soil Management using Causal and Contrastive Constraint Minimization
Jan 13, 2024Monitoring organic matter is pivotal for maintaining soil health and can help inform sustainable soil management practices. While sensor-based soil information offers higher-fidelity and reliable insights into organic matter changes, sampling and measuring sensor data is cost-prohibitive. We propose a multi-modal, scalable framework that can estimate organic matter from remote sensing data, a more readily available data source while leveraging sparse soil information for improving generalization. Using the sensor data, we preserve underlying causal relations among sensor attributes and organic matter. Simultaneously we leverage inherent structure in the data and train the model to discriminate among domains using contrastive learning. This causal and contrastive constraint minimization ensures improved generalization and adaptation to other domains. We also shed light on the interpretability of the framework by identifying attributes that are important for improving generalization. Identifying these key soil attributes that affect organic matter will aid in efforts to standardize data collection efforts.
Benchmarking and Defending Against Indirect Prompt Injection Attacks on Large Language Models
Dec 21, 2023Recent remarkable advancements in large language models (LLMs) have led to their widespread adoption in various applications. A key feature of these applications is the combination of LLMs with external content, where user instructions and third-party content are combined to create prompts for LLM processing. These applications, however, are vulnerable to indirect prompt injection attacks, where malicious instructions embedded within external content compromise LLM's output, causing their responses to deviate from user expectations. Despite the discovery of this security issue, no comprehensive analysis of indirect prompt injection attacks on different LLMs is available due to the lack of a benchmark. Furthermore, no effective defense has been proposed. In this work, we introduce the first benchmark, BIPIA, to measure the robustness of various LLMs and defenses against indirect prompt injection attacks. Our experiments reveal that LLMs with greater capabilities exhibit more vulnerable to indirect prompt injection attacks for text tasks, resulting in a higher ASR. We hypothesize that indirect prompt injection attacks are mainly due to the LLMs' inability to distinguish between instructions and external content. Based on this conjecture, we propose four black-box methods based on prompt learning and a white-box defense methods based on fine-tuning with adversarial training to enable LLMs to distinguish between instructions and external content and ignore instructions in the external content. Our experimental results show that our black-box defense methods can effectively reduce ASR but cannot completely thwart indirect prompt injection attacks, while our white-box defense method can reduce ASR to nearly zero with little adverse impact on the LLM's performance on general tasks. We hope that our benchmark and defenses can inspire future work in this important area.
Extracting Self-Consistent Causal Insights from Users Feedback with LLMs and In-context Learning
Dec 11, 2023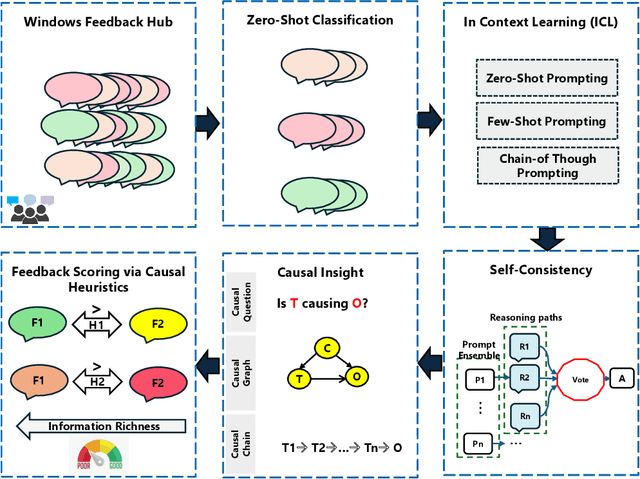

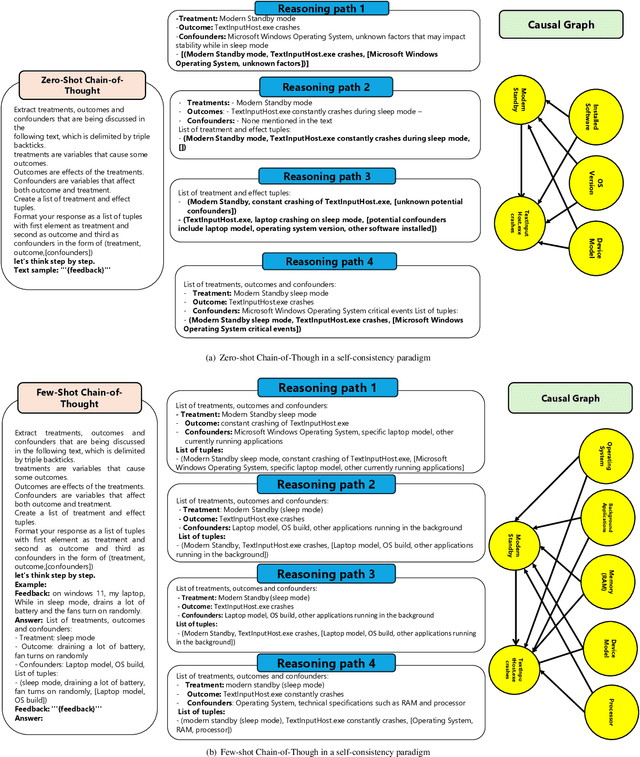
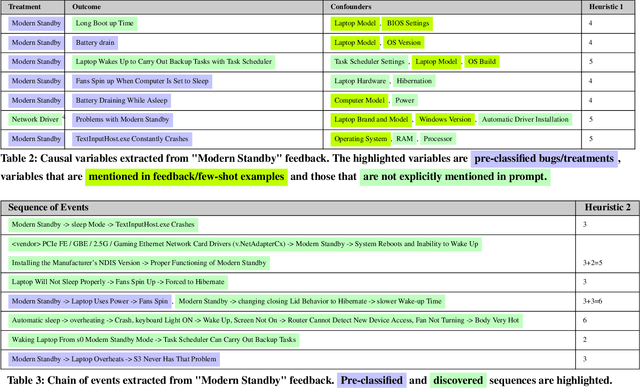
Microsoft Windows Feedback Hub is designed to receive customer feedback on a wide variety of subjects including critical topics such as power and battery. Feedback is one of the most effective ways to have a grasp of users' experience with Windows and its ecosystem. However, the sheer volume of feedback received by Feedback Hub makes it immensely challenging to diagnose the actual cause of reported issues. To better understand and triage issues, we leverage Double Machine Learning (DML) to associate users' feedback with telemetry signals. One of the main challenges we face in the DML pipeline is the necessity of domain knowledge for model design (e.g., causal graph), which sometimes is either not available or hard to obtain. In this work, we take advantage of reasoning capabilities in Large Language Models (LLMs) to generate a prior model that which to some extent compensates for the lack of domain knowledge and could be used as a heuristic for measuring feedback informativeness. Our LLM-based approach is able to extract previously known issues, uncover new bugs, and identify sequences of events that lead to a bug, while minimizing out-of-domain outputs.
TRIALSCOPE: A Unifying Causal Framework for Scaling Real-World Evidence Generation with Biomedical Language Models
Nov 06, 2023The rapid digitization of real-world data offers an unprecedented opportunity for optimizing healthcare delivery and accelerating biomedical discovery. In practice, however, such data is most abundantly available in unstructured forms, such as clinical notes in electronic medical records (EMRs), and it is generally plagued by confounders. In this paper, we present TRIALSCOPE, a unifying framework for distilling real-world evidence from population-level observational data. TRIALSCOPE leverages biomedical language models to structure clinical text at scale, employs advanced probabilistic modeling for denoising and imputation, and incorporates state-of-the-art causal inference techniques to combat common confounders. Using clinical trial specification as generic representation, TRIALSCOPE provides a turn-key solution to generate and reason with clinical hypotheses using observational data. In extensive experiments and analyses on a large-scale real-world dataset with over one million cancer patients from a large US healthcare network, we show that TRIALSCOPE can produce high-quality structuring of real-world data and generates comparable results to marquee cancer trials. In addition to facilitating in-silicon clinical trial design and optimization, TRIALSCOPE may be used to empower synthetic controls, pragmatic trials, post-market surveillance, as well as support fine-grained patient-like-me reasoning in precision diagnosis and treatment.
Knowledge Guided Representation Learning and Causal Structure Learning in Soil Science
Jun 15, 2023



An improved understanding of soil can enable more sustainable land-use practices. Nevertheless, soil is called a complex, living medium due to the complex interaction of different soil processes that limit our understanding of soil. Process-based models and analyzing observed data provide two avenues for improving our understanding of soil processes. Collecting observed data is cost-prohibitive but reflects real-world behavior, while process-based models can be used to generate ample synthetic data which may not be representative of reality. We propose a framework, knowledge-guided representation learning, and causal structure learning (KGRCL), to accelerate scientific discoveries in soil science. The framework improves representation learning for simulated soil processes via conditional distribution matching with observed soil processes. Simultaneously, the framework leverages both observed and simulated data to learn a causal structure among the soil processes. The learned causal graph is more representative of ground truth than other graphs generated from other causal discovery methods. Furthermore, the learned causal graph is leveraged in a supervised learning setup to predict the impact of fertilizer use and changing weather on soil carbon. We present the results in five different locations to show the improvement in the prediction performance in out-of-sample and few-shots setting.
Counterfactual (Non-)identifiability of Learned Structural Causal Models
Jan 22, 2023Recent advances in probabilistic generative modeling have motivated learning Structural Causal Models (SCM) from observational datasets using deep conditional generative models, also known as Deep Structural Causal Models (DSCM). If successful, DSCMs can be utilized for causal estimation tasks, e.g., for answering counterfactual queries. In this work, we warn practitioners about non-identifiability of counterfactual inference from observational data, even in the absence of unobserved confounding and assuming known causal structure. We prove counterfactual identifiability of monotonic generation mechanisms with single dimensional exogenous variables. For general generation mechanisms with multi-dimensional exogenous variables, we provide an impossibility result for counterfactual identifiability, motivating the need for parametric assumptions. As a practical approach, we propose a method for estimating worst-case errors of learned DSCMs' counterfactual predictions. The size of this error can be an essential metric for deciding whether or not DSCMs are a viable approach for counterfactual inference in a specific problem setting. In evaluation, our method confirms negligible counterfactual errors for an identifiable SCM from prior work, and also provides informative error bounds on counterfactual errors for a non-identifiable synthetic SCM.
Causal Modeling of Soil Processes for Improved Generalization
Nov 10, 2022
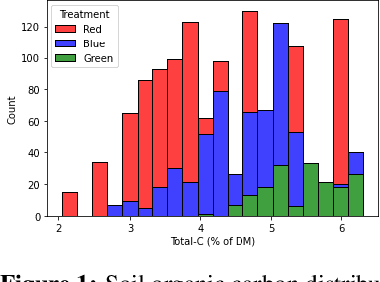
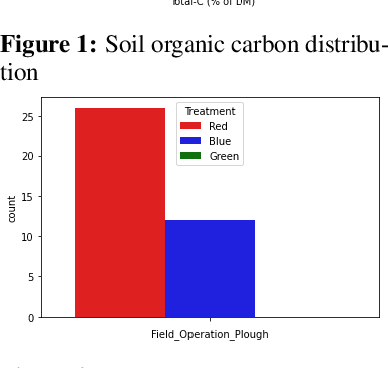
Measuring and monitoring soil organic carbon is critical for agricultural productivity and for addressing critical environmental problems. Soil organic carbon not only enriches nutrition in soil, but also has a gamut of co-benefits such as improving water storage and limiting physical erosion. Despite a litany of work in soil organic carbon estimation, current approaches do not generalize well across soil conditions and management practices. We empirically show that explicit modeling of cause-and-effect relationships among the soil processes improves the out-of-distribution generalizability of prediction models. We provide a comparative analysis of soil organic carbon estimation models where the skeleton is estimated using causal discovery methods. Our framework provide an average improvement of 81% in test mean squared error and 52% in test mean absolute error.