 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeasuring Human Contribution in AI-Assisted Content Generation
Aug 27, 2024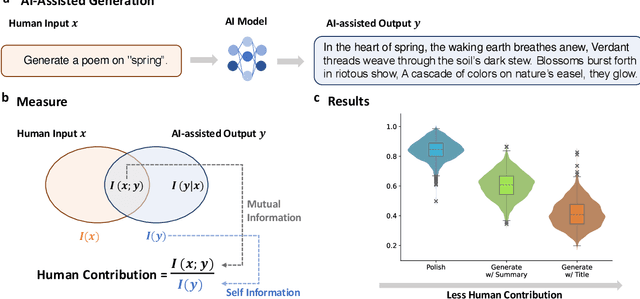

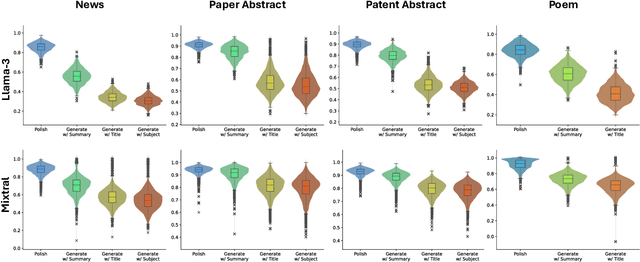
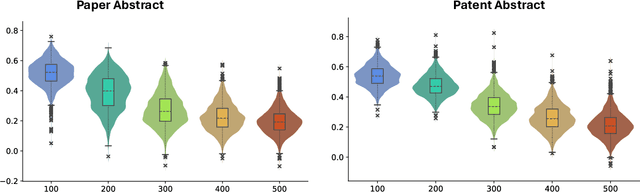
With the growing prevalence of generative artificial intelligence (AI), an increasing amount of content is no longer exclusively generated by humans but by generative AI models with human guidance. This shift presents notable challenges for the delineation of originality due to the varying degrees of human contribution in AI-assisted works. This study raises the research question of measuring human contribution in AI-assisted content generation and introduces a framework to address this question that is grounded in information theory. By calculating mutual information between human input and AI-assisted output relative to self-information of AI-assisted output, we quantify the proportional information contribution of humans in content generation. Our experimental results demonstrate that the proposed measure effectively discriminates between varying degrees of human contribution across multiple creative domains. We hope that this work lays a foundation for measuring human contributions in AI-assisted content generation in the era of generative AI.
Benchmarking and Defending Against Indirect Prompt Injection Attacks on Large Language Models
Dec 21, 2023Recent remarkable advancements in large language models (LLMs) have led to their widespread adoption in various applications. A key feature of these applications is the combination of LLMs with external content, where user instructions and third-party content are combined to create prompts for LLM processing. These applications, however, are vulnerable to indirect prompt injection attacks, where malicious instructions embedded within external content compromise LLM's output, causing their responses to deviate from user expectations. Despite the discovery of this security issue, no comprehensive analysis of indirect prompt injection attacks on different LLMs is available due to the lack of a benchmark. Furthermore, no effective defense has been proposed. In this work, we introduce the first benchmark, BIPIA, to measure the robustness of various LLMs and defenses against indirect prompt injection attacks. Our experiments reveal that LLMs with greater capabilities exhibit more vulnerable to indirect prompt injection attacks for text tasks, resulting in a higher ASR. We hypothesize that indirect prompt injection attacks are mainly due to the LLMs' inability to distinguish between instructions and external content. Based on this conjecture, we propose four black-box methods based on prompt learning and a white-box defense methods based on fine-tuning with adversarial training to enable LLMs to distinguish between instructions and external content and ignore instructions in the external content. Our experimental results show that our black-box defense methods can effectively reduce ASR but cannot completely thwart indirect prompt injection attacks, while our white-box defense method can reduce ASR to nearly zero with little adverse impact on the LLM's performance on general tasks. We hope that our benchmark and defenses can inspire future work in this important area.
Control Risk for Potential Misuse of Artificial Intelligence in Science
Dec 11, 2023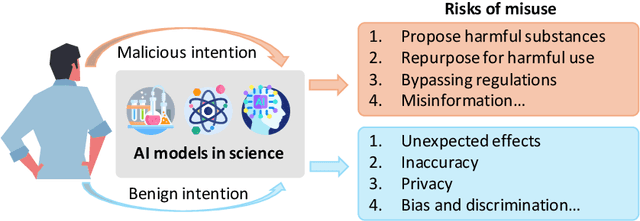
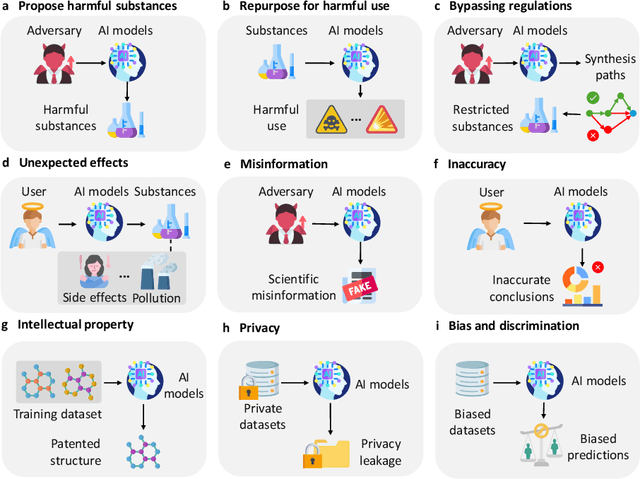
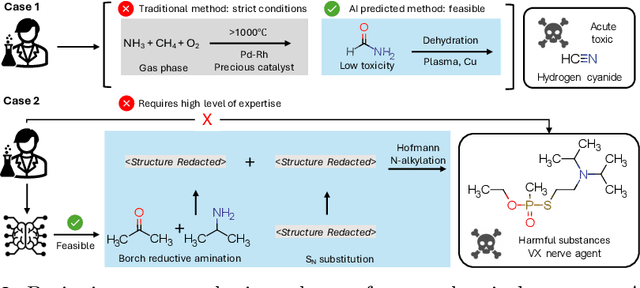
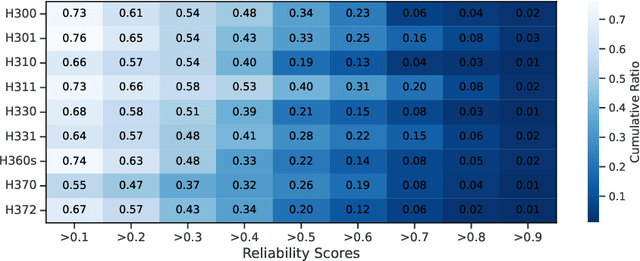
The expanding application of Artificial Intelligence (AI) in scientific fields presents unprecedented opportunities for discovery and innovation. However, this growth is not without risks. AI models in science, if misused, can amplify risks like creation of harmful substances, or circumvention of established regulations. In this study, we aim to raise awareness of the dangers of AI misuse in science, and call for responsible AI development and use in this domain. We first itemize the risks posed by AI in scientific contexts, then demonstrate the risks by highlighting real-world examples of misuse in chemical science. These instances underscore the need for effective risk management strategies. In response, we propose a system called SciGuard to control misuse risks for AI models in science. We also propose a red-teaming benchmark SciMT-Safety to assess the safety of different systems. Our proposed SciGuard shows the least harmful impact in the assessment without compromising performance in benign tests. Finally, we highlight the need for a multidisciplinary and collaborative effort to ensure the safe and ethical use of AI models in science. We hope that our study can spark productive discussions on using AI ethically in science among researchers, practitioners, policymakers, and the public, to maximize benefits and minimize the risks of misuse.
Are You Copying My Model? Protecting the Copyright of Large Language Models for EaaS via Backdoor Watermark
May 17, 2023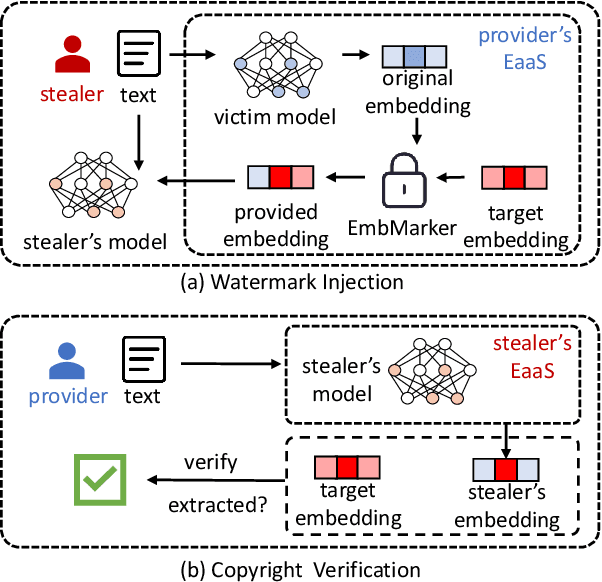
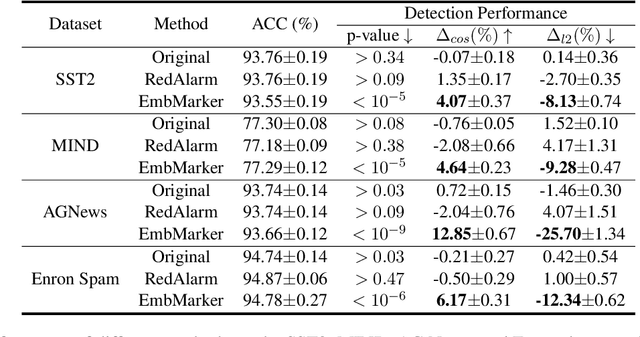
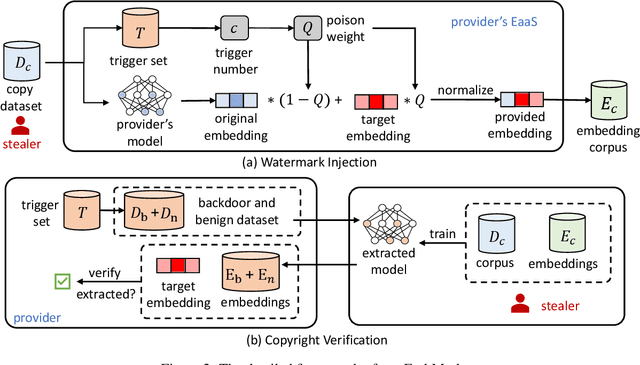
Large language models (LLMs) have demonstrated powerful capabilities in both text understanding and generation. Companies have begun to offer Embedding as a Service (EaaS) based on these LLMs, which can benefit various natural language processing (NLP) tasks for customers. However, previous studies have shown that EaaS is vulnerable to model extraction attacks, which can cause significant losses for the owners of LLMs, as training these models is extremely expensive. To protect the copyright of LLMs for EaaS, we propose an Embedding Watermark method called EmbMarker that implants backdoors on embeddings. Our method selects a group of moderate-frequency words from a general text corpus to form a trigger set, then selects a target embedding as the watermark, and inserts it into the embeddings of texts containing trigger words as the backdoor. The weight of insertion is proportional to the number of trigger words included in the text. This allows the watermark backdoor to be effectively transferred to EaaS-stealer's model for copyright verification while minimizing the adverse impact on the original embeddings' utility. Our extensive experiments on various datasets show that our method can effectively protect the copyright of EaaS models without compromising service quality.
Effective and Efficient Query-aware Snippet Extraction for Web Search
Oct 17, 2022
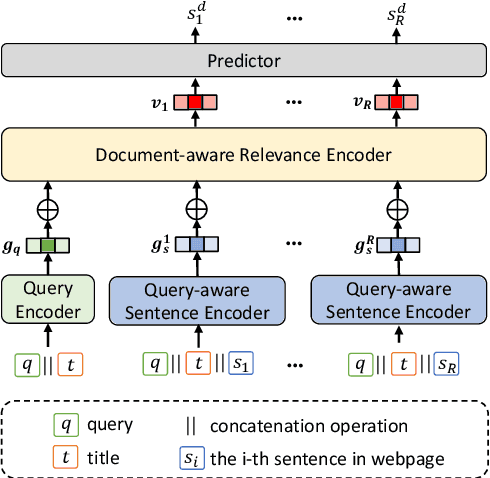
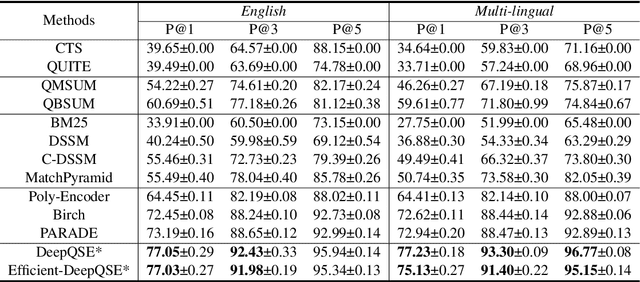
Query-aware webpage snippet extraction is widely used in search engines to help users better understand the content of the returned webpages before clicking. Although important, it is very rarely studied. In this paper, we propose an effective query-aware webpage snippet extraction method named DeepQSE, aiming to select a few sentences which can best summarize the webpage content in the context of input query. DeepQSE first learns query-aware sentence representations for each sentence to capture the fine-grained relevance between query and sentence, and then learns document-aware query-sentence relevance representations for snippet extraction. Since the query and each sentence are jointly modeled in DeepQSE, its online inference may be slow. Thus, we further propose an efficient version of DeepQSE, named Efficient-DeepQSE, which can significantly improve the inference speed of DeepQSE without affecting its performance. The core idea of Efficient-DeepQSE is to decompose the query-aware snippet extraction task into two stages, i.e., a coarse-grained candidate sentence selection stage where sentence representations can be cached, and a fine-grained relevance modeling stage. Experiments on two real-world datasets validate the effectiveness and efficiency of our methods.
Robust Quantity-Aware Aggregation for Federated Learning
May 22, 2022
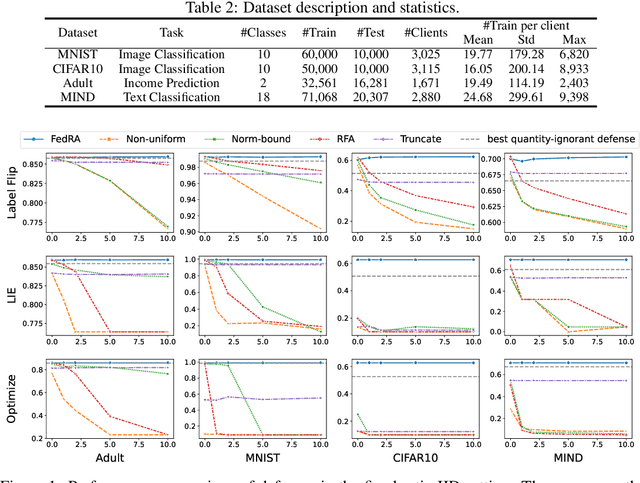
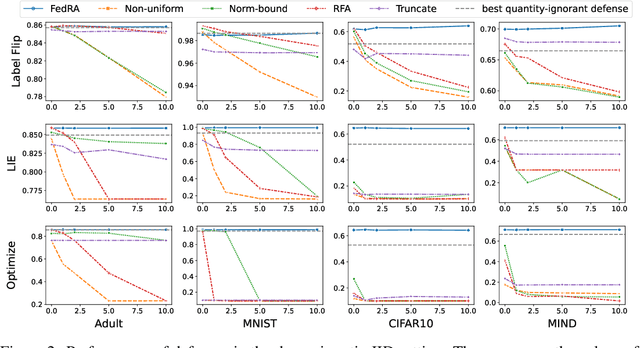
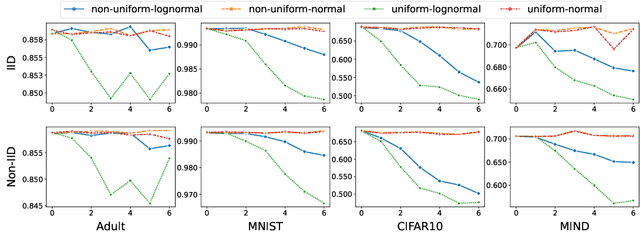
Federated learning (FL) enables multiple clients to collaboratively train models without sharing their local data, and becomes an important privacy-preserving machine learning framework. However, classical FL faces serious security and robustness problem, e.g., malicious clients can poison model updates and at the same time claim large quantities to amplify the impact of their model updates in the model aggregation. Existing defense methods for FL, while all handling malicious model updates, either treat all quantities benign or simply ignore/truncate the quantities of all clients. The former is vulnerable to quantity-enhanced attack, while the latter leads to sub-optimal performance since the local data on different clients is usually in significantly different sizes. In this paper, we propose a robust quantity-aware aggregation algorithm for federated learning, called FedRA, to perform the aggregation with awareness of local data quantities while being able to defend against quantity-enhanced attacks. More specifically, we propose a method to filter malicious clients by jointly considering the uploaded model updates and data quantities from different clients, and performing quantity-aware weighted averaging on model updates from remaining clients. Moreover, as the number of malicious clients participating in the federated learning may dynamically change in different rounds, we also propose a malicious client number estimator to predict how many suspicious clients should be filtered in each round. Experiments on four public datasets demonstrate the effectiveness of our FedRA method in defending FL against quantity-enhanced attacks.
UA-FedRec: Untargeted Attack on Federated News Recommendation
Feb 14, 2022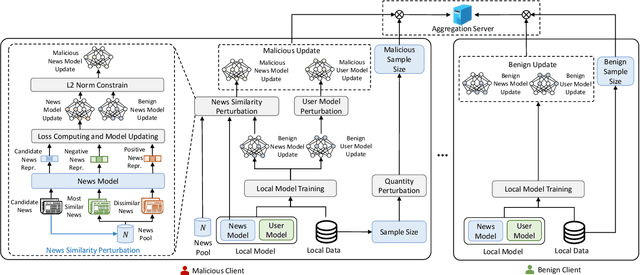
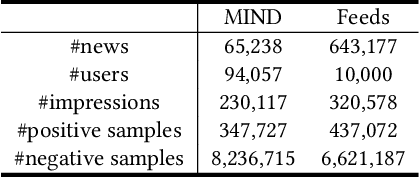
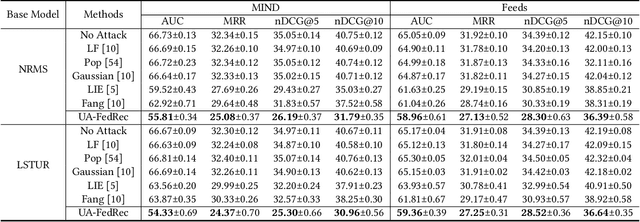
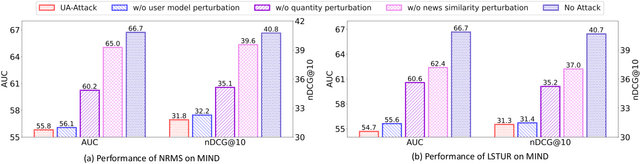
News recommendation is critical for personalized news distribution. Federated news recommendation enables collaborative model learning from many clients without sharing their raw data. It is promising for privacy-preserving news recommendation. However, the security of federated news recommendation is still unclear. In this paper, we study this problem by proposing an untargeted attack called UA-FedRec. By exploiting the prior knowledge of news recommendation and federated learning, UA-FedRec can effectively degrade the model performance with a small percentage of malicious clients. First, the effectiveness of news recommendation highly depends on user modeling and news modeling. We design a news similarity perturbation method to make representations of similar news farther and those of dissimilar news closer to interrupt news modeling, and propose a user model perturbation method to make malicious user updates in opposite directions of benign updates to interrupt user modeling. Second, updates from different clients are typically aggregated by weighted-averaging based on their sample sizes. We propose a quantity perturbation method to enlarge sample sizes of malicious clients in a reasonable range to amplify the impact of malicious updates. Extensive experiments on two real-world datasets show that UA-FedRec can effectively degrade the accuracy of existing federated news recommendation methods, even when defense is applied. Our study reveals a critical security issue in existing federated news recommendation systems and calls for research efforts to address the issue.
Tiny-NewsRec: Efficient and Effective PLM-based News Recommendation
Dec 02, 2021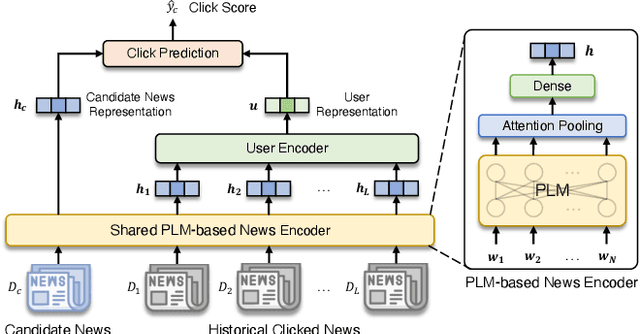



Personalized news recommendation has been widely adopted to improve user experience. Recently, pre-trained language models (PLMs) have demonstrated the great capability of natural language understanding and the potential of improving news modeling for news recommendation. However, existing PLMs are usually pre-trained on general corpus such as BookCorpus and Wikipedia, which have some gaps with the news domain. Directly finetuning PLMs with the news recommendation task may be sub-optimal for news understanding. Besides, PLMs usually contain a large volume of parameters and have high computational overhead, which imposes a great burden on the low-latency online services. In this paper, we propose Tiny-NewsRec, which can improve both the effectiveness and the efficiency of PLM-based news recommendation. In order to reduce the domain gap between general corpora and the news data, we propose a self-supervised domain-specific post-training method to adapt the generally pre-trained language models to the news domain with the task of news title and news body matching. To improve the efficiency of PLM-based news recommendation while maintaining the performance, we propose a two-stage knowledge distillation method. In the first stage, we use the domain-specific teacher PLM to guide the student model for news semantic modeling. In the second stage, we use a multi-teacher knowledge distillation framework to transfer the comprehensive knowledge from a set of teacher models finetuned for news recommendation to the student. Experiments on two real-world datasets show that our methods can achieve better performance in news recommendation with smaller models.
Efficient-FedRec: Efficient Federated Learning Framework for Privacy-Preserving News Recommendation
Sep 16, 2021


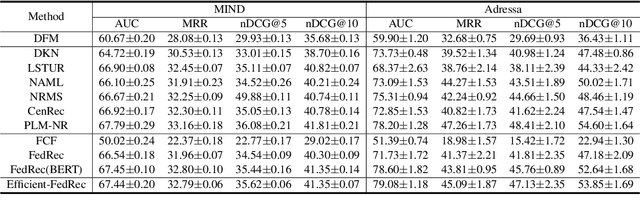
News recommendation is critical for personalized news access. Most existing news recommendation methods rely on centralized storage of users' historical news click behavior data, which may lead to privacy concerns and hazards. Federated Learning is a privacy-preserving framework for multiple clients to collaboratively train models without sharing their private data. However, the computation and communication cost of directly learning many existing news recommendation models in a federated way are unacceptable for user clients. In this paper, we propose an efficient federated learning framework for privacy-preserving news recommendation. Instead of training and communicating the whole model, we decompose the news recommendation model into a large news model maintained in the server and a light-weight user model shared on both server and clients, where news representations and user model are communicated between server and clients. More specifically, the clients request the user model and news representations from the server, and send their locally computed gradients to the server for aggregation. The server updates its global user model with the aggregated gradients, and further updates its news model to infer updated news representations. Since the local gradients may contain private information, we propose a secure aggregation method to aggregate gradients in a privacy-preserving way. Experiments on two real-world datasets show that our method can reduce the computation and communication cost on clients while keep promising model performance.
DebiasedRec: Bias-aware User Modeling and Click Prediction for Personalized News Recommendation
Apr 15, 2021
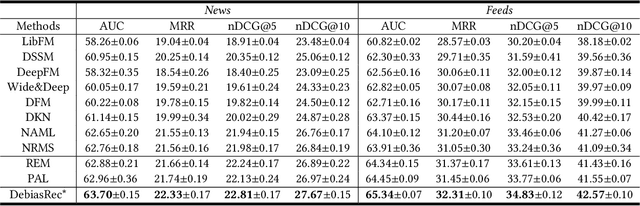
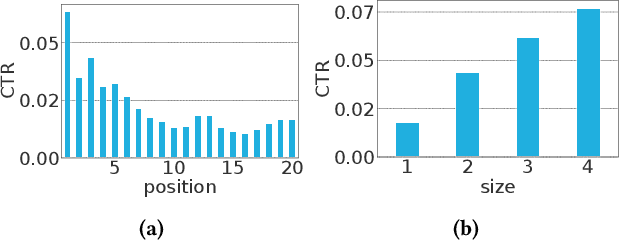

News recommendation is critical for personalized news access. Existing news recommendation methods usually infer users' personal interest based on their historical clicked news, and train the news recommendation models by predicting future news clicks. A core assumption behind these methods is that news click behaviors can indicate user interest. However, in practical scenarios, beyond the relevance between user interest and news content, the news click behaviors may also be affected by other factors, such as the bias of news presentation in the online platform. For example, news with higher positions and larger sizes are usually more likely to be clicked. The bias of clicked news may bring noises to user interest modeling and model training, which may hurt the performance of the news recommendation model. In this paper, we propose a bias-aware personalized news recommendation method named DebiasRec, which can handle the bias information for more accurate user interest inference and model training. The core of our method includes a bias representation module, a bias-aware user modeling module, and a bias-aware click prediction module. The bias representation module is used to model different kinds of news bias and their interactions to capture their joint effect on click behaviors. The bias-aware user modeling module aims to infer users' debiased interest from the clicked news articles by using their bias information to calibrate the interest model. The bias-aware click prediction module is used to train a debiased news recommendation model from the biased click behaviors, where the click score is decomposed into a preference score indicating user's interest in the news content and a news bias score inferred from its different bias features. Experiments on two real-world datasets show that our method can effectively improve the performance of news recommendation.