 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTriEx: A Game-based Tri-View Framework for Explaining Internal Reasoning in Multi-Agent LLMs
Apr 21, 2026Explainability for Large Language Model (LLM) agents is especially challenging in interactive, partially observable settings, where decisions depend on evolving beliefs and other agents. We present \textbf{TriEx}, a tri-view explainability framework that instruments sequential decision making with aligned artifacts: (i) structured first-person self-reasoning bound to an action, (ii) explicit second-person belief states about opponents updated over time, and (iii) third-person oracle audits grounded in environment-derived reference signals. This design turns explanations from free-form narratives into evidence-anchored objects that can be compared and checked across time and perspectives. Using imperfect-information strategic games as a controlled testbed, we show that TriEx enables scalable analysis of explanation faithfulness, belief dynamics, and evaluator reliability, revealing systematic mismatches between what agents say, what they believe, and what they do. Our results highlight explainability as an interaction-dependent property and motivate multi-view, evidence-grounded evaluation for LLM agents. Code is available at https://github.com/Einsam1819/TriEx.
Synthetic Data Powers Product Retrieval for Long-tail Knowledge-Intensive Queries in E-commerce Search
Feb 27, 2026Product retrieval is the backbone of e-commerce search: for each user query, it identifies a high-recall candidate set from billions of items, laying the foundation for high-quality ranking and user experience. Despite extensive optimization for mainstream queries, existing systems still struggle with long-tail queries, especially knowledge-intensive ones. These queries exhibit diverse linguistic patterns, often lack explicit purchase intent, and require domain-specific knowledge reasoning for accurate interpretation. They also suffer from a shortage of reliable behavioral logs, which makes such queries a persistent challenge for retrieval optimization. To address these issues, we propose an efficient data synthesis framework tailored to retrieval involving long-tail, knowledge-intensive queries. The key idea is to implicitly distill the capabilities of a powerful offline query-rewriting model into an efficient online retrieval system. Leveraging the strong language understanding of LLMs, we train a multi-candidate query rewriting model with multiple reward signals and capture its rewriting capability in well-curated query-product pairs through a powerful offline retrieval pipeline. This design mitigates distributional shift in rewritten queries, which might otherwise limit incremental recall or introduce irrelevant products. Experiments demonstrate that without any additional tricks, simply incorporating this synthetic data into retrieval model training leads to significant improvements. Online Side-By-Side (SBS) human evaluation results indicate a notable enhancement in user search experience.
ProxyWar: Dynamic Assessment of LLM Code Generation in Game Arenas
Feb 04, 2026Large language models (LLMs) have revolutionized automated code generation, yet the evaluation of their real-world effectiveness remains limited by static benchmarks and simplistic metrics. We present ProxyWar, a novel framework that systematically assesses code generation quality by embedding LLM-generated agents within diverse, competitive game environments. Unlike existing approaches, ProxyWar evaluates not only functional correctness but also the operational characteristics of generated programs, combining automated testing, iterative code repair, and multi-agent tournaments to provide a holistic view of program behavior. Applied to a range of state-of-the-art coders and games, our approach uncovers notable discrepancies between benchmark scores and actual performance in dynamic settings, revealing overlooked limitations and opportunities for improvement. These findings highlight the need for richer, competition-based evaluation of code generation. Looking forward, ProxyWar lays a foundation for research into LLM-driven algorithm discovery, adaptive problem solving, and the study of practical efficiency and robustness, including the potential for models to outperform hand-crafted agents. The project is available at https://github.com/xinke-wang/ProxyWar.
C2T-ID: Converting Semantic Codebooks to Textual Document Identifiers for Generative Search
Oct 22, 2025



Designing document identifiers (docids) that carry rich semantic information while maintaining tractable search spaces is a important challenge in generative retrieval (GR). Popular codebook methods address this by building a hierarchical semantic tree and constraining generation to its child nodes, yet their numeric identifiers cannot leverage the large language model's pretrained natural language understanding. Conversely, using text as docid provides more semantic expressivity but inflates the decoding space, making the system brittle to early-step errors. To resolve this trade-off, we propose C2T-ID: (i) first construct semantic numerical docid via hierarchical clustering; (ii) then extract high-frequency metadata keywords and iteratively replace each numeric label with its cluster's top-K keywords; and (iii) an optional two-level semantic smoothing step further enhances the fluency of C2T-ID. Experiments on Natural Questions and Taobao's product search demonstrate that C2T-ID significantly outperforms atomic, semantic codebook, and pure-text docid baselines, demonstrating its effectiveness in balancing semantic expressiveness with search space constraints.
Large Language Models for Generative Information Extraction: A Survey
Dec 29, 2023Information extraction (IE) aims to extract structural knowledge (such as entities, relations, and events) from plain natural language texts. Recently, generative Large Language Models (LLMs) have demonstrated remarkable capabilities in text understanding and generation, allowing for generalization across various domains and tasks. As a result, numerous works have been proposed to harness abilities of LLMs and offer viable solutions for IE tasks based on a generative paradigm. To conduct a comprehensive systematic review and exploration of LLM efforts for IE tasks, in this study, we survey the most recent advancements in this field. We first present an extensive overview by categorizing these works in terms of various IE subtasks and learning paradigms, then we empirically analyze the most advanced methods and discover the emerging trend of IE tasks with LLMs. Based on thorough review conducted, we identify several insights in technique and promising research directions that deserve further exploration in future studies. We maintain a public repository and consistently update related resources at: \url{https://github.com/quqxui/Awesome-LLM4IE-Papers}.
Large Language Model based Long-tail Query Rewriting in Taobao Search
Nov 12, 2023



In the realm of e-commerce search, the significance of semantic matching cannot be overstated, as it directly impacts both user experience and company revenue. Along this line, query rewriting, serving as an important technique to bridge the semantic gaps inherent in the semantic matching process, has attached wide attention from the industry and academia. However, existing query rewriting methods often struggle to effectively optimize long-tail queries and alleviate the phenomenon of "few-recall" caused by semantic gap. In this paper, we present BEQUE, a comprehensive framework that Bridges the sEmantic gap for long-tail QUEries. In detail, BEQUE comprises three stages: multi-instruction supervised fine tuning (SFT), offline feedback, and objective alignment. We first construct a rewriting dataset based on rejection sampling and auxiliary tasks mixing to fine-tune our large language model (LLM) in a supervised fashion. Subsequently, with the well-trained LLM, we employ beam search to generate multiple candidate rewrites, and feed them into Taobao offline system to obtain the partial order. Leveraging the partial order of rewrites, we introduce a contrastive learning method to highlight the distinctions between rewrites, and align the model with the Taobao online objectives. Offline experiments prove the effectiveness of our method in bridging semantic gap. Online A/B tests reveal that our method can significantly boost gross merchandise volume (GMV), number of transaction (#Trans) and unique visitor (UV) for long-tail queries. BEQUE has been deployed on Taobao, one of most popular online shopping platforms in China, since October 2023.
Are You Copying My Model? Protecting the Copyright of Large Language Models for EaaS via Backdoor Watermark
May 17, 2023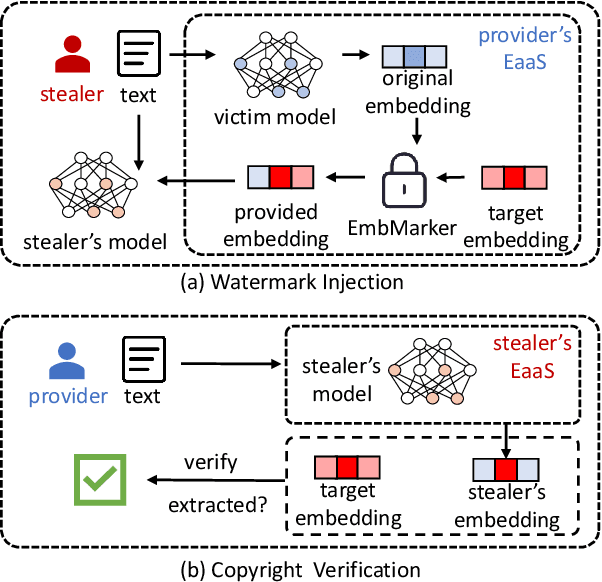
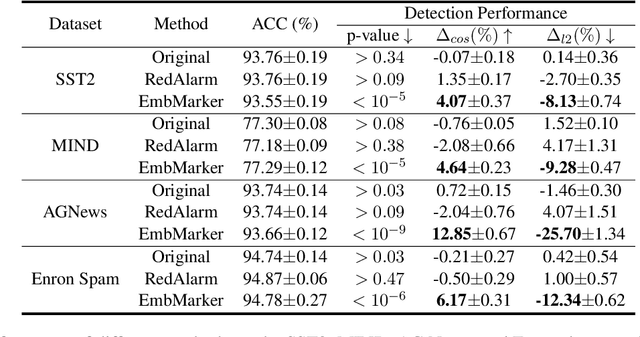
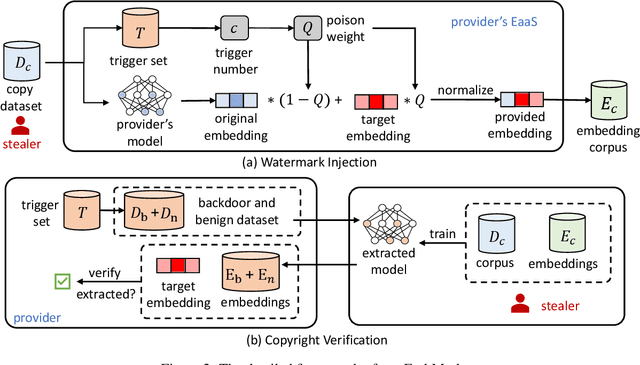
Large language models (LLMs) have demonstrated powerful capabilities in both text understanding and generation. Companies have begun to offer Embedding as a Service (EaaS) based on these LLMs, which can benefit various natural language processing (NLP) tasks for customers. However, previous studies have shown that EaaS is vulnerable to model extraction attacks, which can cause significant losses for the owners of LLMs, as training these models is extremely expensive. To protect the copyright of LLMs for EaaS, we propose an Embedding Watermark method called EmbMarker that implants backdoors on embeddings. Our method selects a group of moderate-frequency words from a general text corpus to form a trigger set, then selects a target embedding as the watermark, and inserts it into the embeddings of texts containing trigger words as the backdoor. The weight of insertion is proportional to the number of trigger words included in the text. This allows the watermark backdoor to be effectively transferred to EaaS-stealer's model for copyright verification while minimizing the adverse impact on the original embeddings' utility. Our extensive experiments on various datasets show that our method can effectively protect the copyright of EaaS models without compromising service quality.
IHGNN: Interactive Hypergraph Neural Network for Personalized Product Search
Feb 10, 2022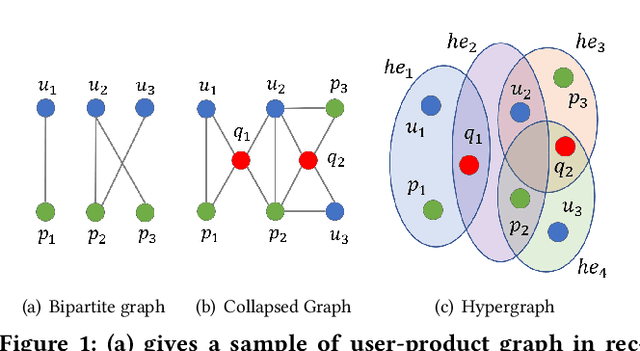
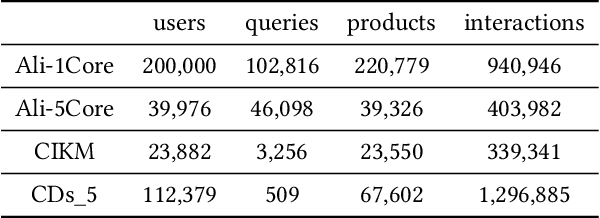

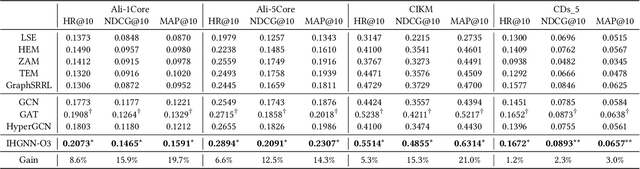
A good personalized product search (PPS) system should not only focus on retrieving relevant products, but also consider user personalized preference. Recent work on PPS mainly adopts the representation learning paradigm, e.g., learning representations for each entity (including user, product and query) from historical user behaviors (aka. user-product-query interactions). However, we argue that existing methods do not sufficiently exploit the crucial collaborative signal, which is latent in historical interactions to reveal the affinity between the entities. Collaborative signal is quite helpful for generating high-quality representation, exploiting which would benefit the representation learning of one node from its connected nodes. To tackle this limitation, in this work, we propose a new model IHGNN for personalized product search. IHGNN resorts to a hypergraph constructed from the historical user-product-query interactions, which could completely preserve ternary relations and express collaborative signal based on the topological structure. On this basis, we develop a specific interactive hypergraph neural network to explicitly encode the structure information (i.e., collaborative signal) into the embedding process. It collects the information from the hypergraph neighbors and explicitly models neighbor feature interaction to enhance the representation of the target entity. Extensive experiments on three real-world datasets validate the superiority of our proposal over the state-of-the-arts.
Rethinking Convolutional Features in Correlation Filter Based Tracking
Dec 30, 2019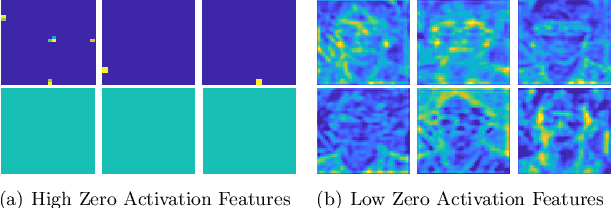

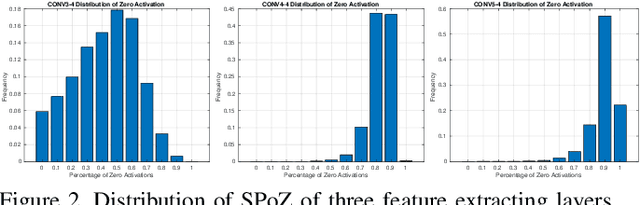
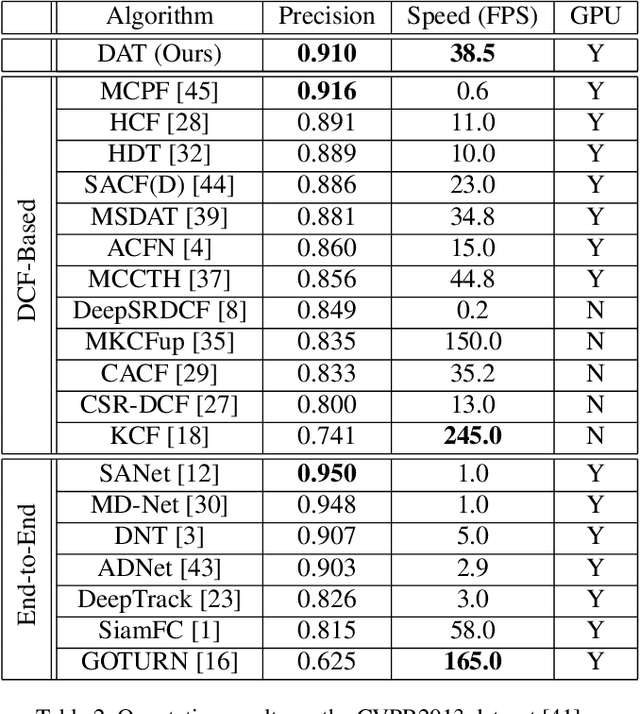
Both accuracy and efficiency are of significant importance to the task of visual object tracking. In recent years, as the surge of deep learning, Deep Convolutional NeuralNetwork (DCNN) becomes a very popular choice among the tracking community. However, due to the high computational complexity, end-to-end visual object trackers can hardly achieve an acceptable inference time and therefore can difficult to be utilized in many real-world applications. In this paper, we revisit a hierarchical deep feature-based visual tracker and found that both the performance and efficiency of the deep tracker are limited by the poor feature quality. Therefore, we propose a feature selection module to select more discriminative features for the trackers. After removing redundant features, our proposed tracker achieves significant improvements in both performance and efficiency. Finally, comparisons with state-of-the-art trackers are provided.