 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncovering inequalities in new knowledge learning by large language models across different languages
Mar 06, 2025As large language models (LLMs) gradually become integral tools for problem solving in daily life worldwide, understanding linguistic inequality is becoming increasingly important. Existing research has primarily focused on static analyses that assess the disparities in the existing knowledge and capabilities of LLMs across languages. However, LLMs are continuously evolving, acquiring new knowledge to generate up-to-date, domain-specific responses. Investigating linguistic inequalities within this dynamic process is, therefore, also essential. In this paper, we explore inequalities in new knowledge learning by LLMs across different languages and four key dimensions: effectiveness, transferability, prioritization, and robustness. Through extensive experiments under two settings (in-context learning and fine-tuning) using both proprietary and open-source models, we demonstrate that low-resource languages consistently face disadvantages across all four dimensions. By shedding light on these disparities, we aim to raise awareness of linguistic inequalities in LLMs' new knowledge learning, fostering the development of more inclusive and equitable future LLMs.
Measuring Human Contribution in AI-Assisted Content Generation
Aug 27, 2024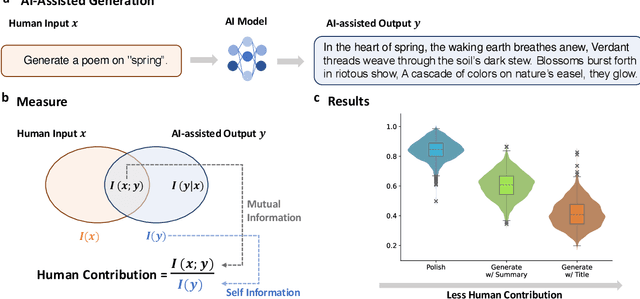

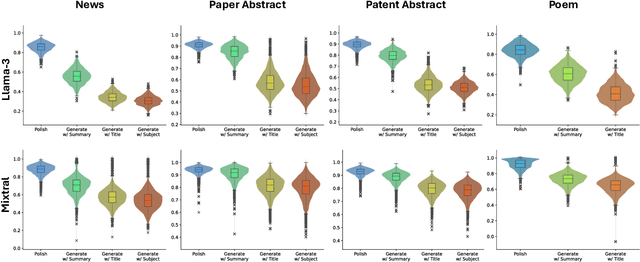
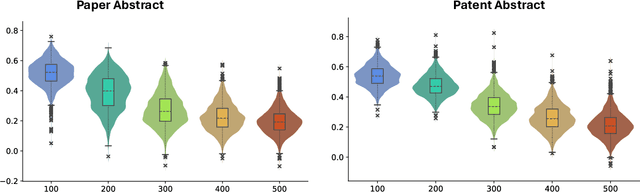
With the growing prevalence of generative artificial intelligence (AI), an increasing amount of content is no longer exclusively generated by humans but by generative AI models with human guidance. This shift presents notable challenges for the delineation of originality due to the varying degrees of human contribution in AI-assisted works. This study raises the research question of measuring human contribution in AI-assisted content generation and introduces a framework to address this question that is grounded in information theory. By calculating mutual information between human input and AI-assisted output relative to self-information of AI-assisted output, we quantify the proportional information contribution of humans in content generation. Our experimental results demonstrate that the proposed measure effectively discriminates between varying degrees of human contribution across multiple creative domains. We hope that this work lays a foundation for measuring human contributions in AI-assisted content generation in the era of generative AI.
Uncovering Safety Risks in Open-source LLMs through Concept Activation Vector
Apr 18, 2024Current open-source large language models (LLMs) are often undergone careful safety alignment before public release. Some attack methods have also been proposed that help check for safety vulnerabilities in LLMs to ensure alignment robustness. However, many of these methods have moderate attack success rates. Even when successful, the harmfulness of their outputs cannot be guaranteed, leading to suspicions that these methods have not accurately identified the safety vulnerabilities of LLMs. In this paper, we introduce a LLM attack method utilizing concept-based model explanation, where we extract safety concept activation vectors (SCAVs) from LLMs' activation space, enabling efficient attacks on well-aligned LLMs like LLaMA-2, achieving near 100% attack success rate as if LLMs are completely unaligned. This suggests that LLMs, even after thorough safety alignment, could still pose potential risks to society upon public release. To evaluate the harmfulness of outputs resulting with various attack methods, we propose a comprehensive evaluation method that reduces the potential inaccuracies of existing evaluations, and further validate that our method causes more harmful content. Additionally, we discover that the SCAVs show some transferability across different open-source LLMs.
Benchmarking and Defending Against Indirect Prompt Injection Attacks on Large Language Models
Dec 21, 2023Recent remarkable advancements in large language models (LLMs) have led to their widespread adoption in various applications. A key feature of these applications is the combination of LLMs with external content, where user instructions and third-party content are combined to create prompts for LLM processing. These applications, however, are vulnerable to indirect prompt injection attacks, where malicious instructions embedded within external content compromise LLM's output, causing their responses to deviate from user expectations. Despite the discovery of this security issue, no comprehensive analysis of indirect prompt injection attacks on different LLMs is available due to the lack of a benchmark. Furthermore, no effective defense has been proposed. In this work, we introduce the first benchmark, BIPIA, to measure the robustness of various LLMs and defenses against indirect prompt injection attacks. Our experiments reveal that LLMs with greater capabilities exhibit more vulnerable to indirect prompt injection attacks for text tasks, resulting in a higher ASR. We hypothesize that indirect prompt injection attacks are mainly due to the LLMs' inability to distinguish between instructions and external content. Based on this conjecture, we propose four black-box methods based on prompt learning and a white-box defense methods based on fine-tuning with adversarial training to enable LLMs to distinguish between instructions and external content and ignore instructions in the external content. Our experimental results show that our black-box defense methods can effectively reduce ASR but cannot completely thwart indirect prompt injection attacks, while our white-box defense method can reduce ASR to nearly zero with little adverse impact on the LLM's performance on general tasks. We hope that our benchmark and defenses can inspire future work in this important area.
Towards Attack-tolerant Federated Learning via Critical Parameter Analysis
Aug 18, 2023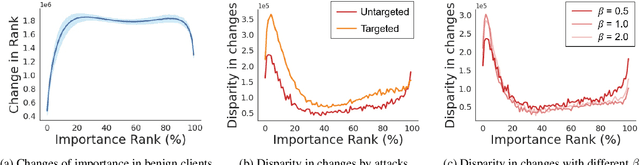
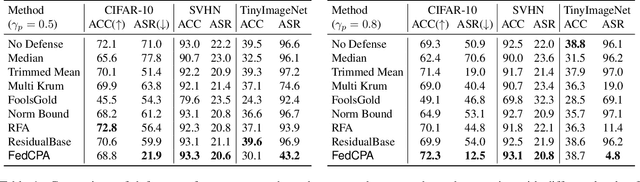
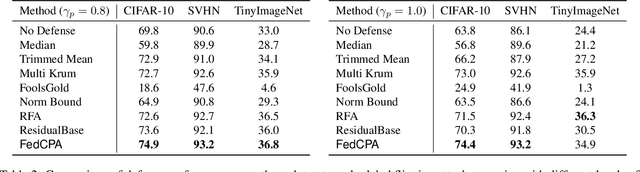
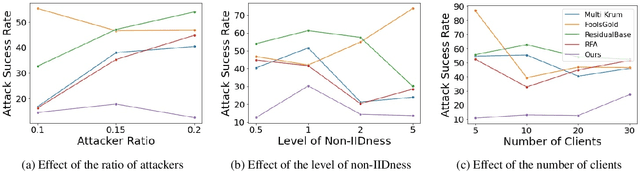
Federated learning is used to train a shared model in a decentralized way without clients sharing private data with each other. Federated learning systems are susceptible to poisoning attacks when malicious clients send false updates to the central server. Existing defense strategies are ineffective under non-IID data settings. This paper proposes a new defense strategy, FedCPA (Federated learning with Critical Parameter Analysis). Our attack-tolerant aggregation method is based on the observation that benign local models have similar sets of top-k and bottom-k critical parameters, whereas poisoned local models do not. Experiments with different attack scenarios on multiple datasets demonstrate that our model outperforms existing defense strategies in defending against poisoning attacks.
FedDefender: Client-Side Attack-Tolerant Federated Learning
Jul 18, 2023Federated learning enables learning from decentralized data sources without compromising privacy, which makes it a crucial technique. However, it is vulnerable to model poisoning attacks, where malicious clients interfere with the training process. Previous defense mechanisms have focused on the server-side by using careful model aggregation, but this may not be effective when the data is not identically distributed or when attackers can access the information of benign clients. In this paper, we propose a new defense mechanism that focuses on the client-side, called FedDefender, to help benign clients train robust local models and avoid the adverse impact of malicious model updates from attackers, even when a server-side defense cannot identify or remove adversaries. Our method consists of two main components: (1) attack-tolerant local meta update and (2) attack-tolerant global knowledge distillation. These components are used to find noise-resilient model parameters while accurately extracting knowledge from a potentially corrupted global model. Our client-side defense strategy has a flexible structure and can work in conjunction with any existing server-side strategies. Evaluations of real-world scenarios across multiple datasets show that the proposed method enhances the robustness of federated learning against model poisoning attacks.
FedSampling: A Better Sampling Strategy for Federated Learning
Jun 25, 2023Federated learning (FL) is an important technique for learning models from decentralized data in a privacy-preserving way. Existing FL methods usually uniformly sample clients for local model learning in each round. However, different clients may have significantly different data sizes, and the clients with more data cannot have more opportunities to contribute to model training, which may lead to inferior performance. In this paper, instead of client uniform sampling, we propose a novel data uniform sampling strategy for federated learning (FedSampling), which can effectively improve the performance of federated learning especially when client data size distribution is highly imbalanced across clients. In each federated learning round, local data on each client is randomly sampled for local model learning according to a probability based on the server desired sample size and the total sample size on all available clients. Since the data size on each client is privacy-sensitive, we propose a privacy-preserving way to estimate the total sample size with a differential privacy guarantee. Experiments on four benchmark datasets show that FedSampling can effectively improve the performance of federated learning.
Are You Copying My Model? Protecting the Copyright of Large Language Models for EaaS via Backdoor Watermark
May 17, 2023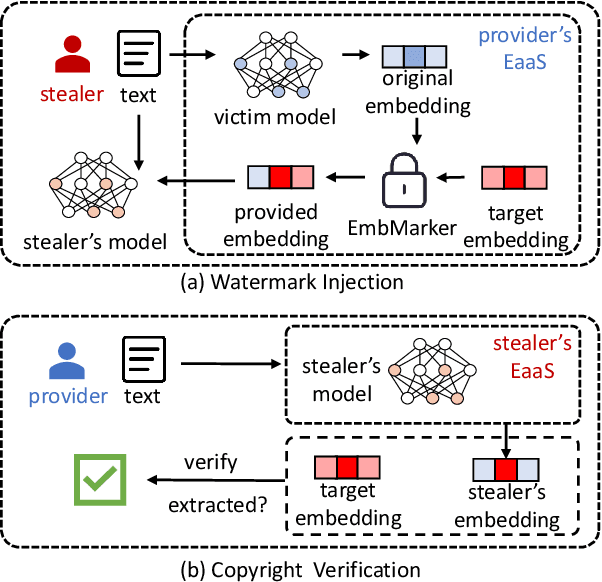
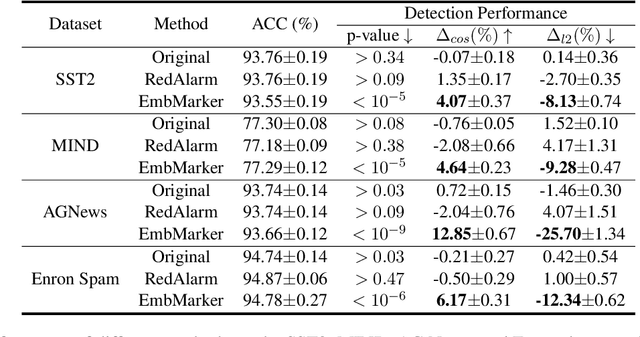
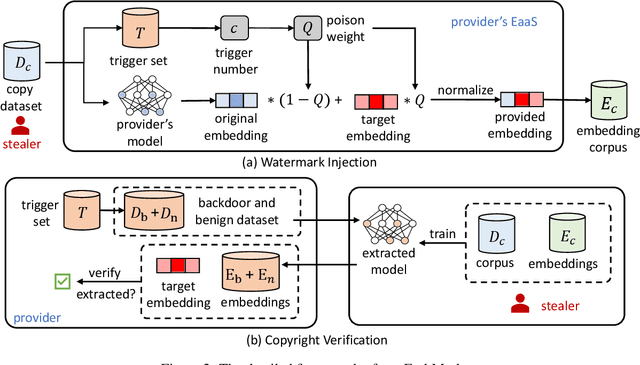
Large language models (LLMs) have demonstrated powerful capabilities in both text understanding and generation. Companies have begun to offer Embedding as a Service (EaaS) based on these LLMs, which can benefit various natural language processing (NLP) tasks for customers. However, previous studies have shown that EaaS is vulnerable to model extraction attacks, which can cause significant losses for the owners of LLMs, as training these models is extremely expensive. To protect the copyright of LLMs for EaaS, we propose an Embedding Watermark method called EmbMarker that implants backdoors on embeddings. Our method selects a group of moderate-frequency words from a general text corpus to form a trigger set, then selects a target embedding as the watermark, and inserts it into the embeddings of texts containing trigger words as the backdoor. The weight of insertion is proportional to the number of trigger words included in the text. This allows the watermark backdoor to be effectively transferred to EaaS-stealer's model for copyright verification while minimizing the adverse impact on the original embeddings' utility. Our extensive experiments on various datasets show that our method can effectively protect the copyright of EaaS models without compromising service quality.
Selective Knowledge Sharing for Privacy-Preserving Federated Distillation without A Good Teacher
Apr 25, 2023While federated learning is promising for privacy-preserving collaborative learning without revealing local data, it remains vulnerable to white-box attacks and struggles to adapt to heterogeneous clients. Federated distillation (FD), built upon knowledge distillation--an effective technique for transferring knowledge from a teacher model to student models--emerges as an alternative paradigm, which provides enhanced privacy guarantees and addresses model heterogeneity. Nevertheless, challenges arise due to variations in local data distributions and the absence of a well-trained teacher model, which leads to misleading and ambiguous knowledge sharing that significantly degrades model performance. To address these issues, this paper proposes a selective knowledge sharing mechanism for FD, termed Selective-FD. It includes client-side selectors and a server-side selector to accurately and precisely identify knowledge from local and ensemble predictions, respectively. Empirical studies, backed by theoretical insights, demonstrate that our approach enhances the generalization capabilities of the FD framework and consistently outperforms baseline methods.
DualFair: Fair Representation Learning at Both Group and Individual Levels via Contrastive Self-supervision
Mar 15, 2023Algorithmic fairness has become an important machine learning problem, especially for mission-critical Web applications. This work presents a self-supervised model, called DualFair, that can debias sensitive attributes like gender and race from learned representations. Unlike existing models that target a single type of fairness, our model jointly optimizes for two fairness criteria - group fairness and counterfactual fairness - and hence makes fairer predictions at both the group and individual levels. Our model uses contrastive loss to generate embeddings that are indistinguishable for each protected group, while forcing the embeddings of counterfactual pairs to be similar. It then uses a self-knowledge distillation method to maintain the quality of representation for the downstream tasks. Extensive analysis over multiple datasets confirms the model's validity and further shows the synergy of jointly addressing two fairness criteria, suggesting the model's potential value in fair intelligent Web applications.