 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMrM: Black-Box Membership Inference Attacks against Multimodal RAG Systems
Jun 09, 2025



Multimodal retrieval-augmented generation (RAG) systems enhance large vision-language models by integrating cross-modal knowledge, enabling their increasing adoption across real-world multimodal tasks. These knowledge databases may contain sensitive information that requires privacy protection. However, multimodal RAG systems inherently grant external users indirect access to such data, making them potentially vulnerable to privacy attacks, particularly membership inference attacks (MIAs). % Existing MIA methods targeting RAG systems predominantly focus on the textual modality, while the visual modality remains relatively underexplored. To bridge this gap, we propose MrM, the first black-box MIA framework targeted at multimodal RAG systems. It utilizes a multi-object data perturbation framework constrained by counterfactual attacks, which can concurrently induce the RAG systems to retrieve the target data and generate information that leaks the membership information. Our method first employs an object-aware data perturbation method to constrain the perturbation to key semantics and ensure successful retrieval. Building on this, we design a counterfact-informed mask selection strategy to prioritize the most informative masked regions, aiming to eliminate the interference of model self-knowledge and amplify attack efficacy. Finally, we perform statistical membership inference by modeling query trials to extract features that reflect the reconstruction of masked semantics from response patterns. Experiments on two visual datasets and eight mainstream commercial visual-language models (e.g., GPT-4o, Gemini-2) demonstrate that MrM achieves consistently strong performance across both sample-level and set-level evaluations, and remains robust under adaptive defenses.
HeteRAG: A Heterogeneous Retrieval-augmented Generation Framework with Decoupled Knowledge Representations
Apr 12, 2025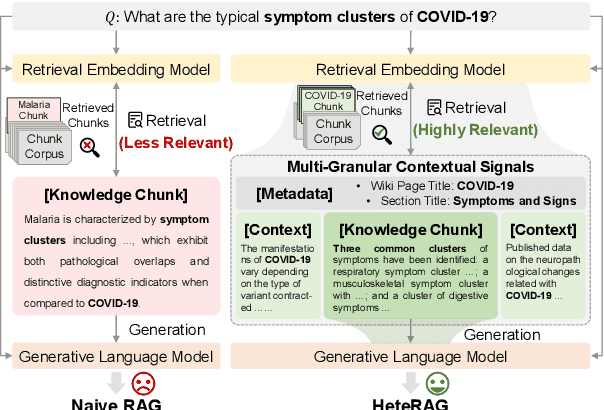

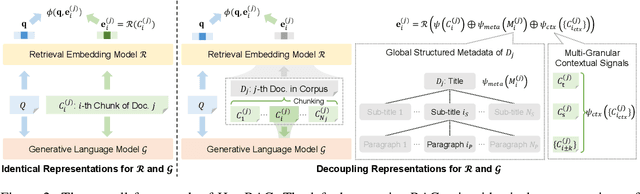

Retrieval-augmented generation (RAG) methods can enhance the performance of LLMs by incorporating retrieved knowledge chunks into the generation process. In general, the retrieval and generation steps usually have different requirements for these knowledge chunks. The retrieval step benefits from comprehensive information to improve retrieval accuracy, whereas excessively long chunks may introduce redundant contextual information, thereby diminishing both the effectiveness and efficiency of the generation process. However, existing RAG methods typically employ identical representations of knowledge chunks for both retrieval and generation, resulting in suboptimal performance. In this paper, we propose a heterogeneous RAG framework (\myname) that decouples the representations of knowledge chunks for retrieval and generation, thereby enhancing the LLMs in both effectiveness and efficiency. Specifically, we utilize short chunks to represent knowledge to adapt the generation step and utilize the corresponding chunk with its contextual information from multi-granular views to enhance retrieval accuracy. We further introduce an adaptive prompt tuning method for the retrieval model to adapt the heterogeneous retrieval augmented generation process. Extensive experiments demonstrate that \myname achieves significant improvements compared to baselines.
Measuring Human Contribution in AI-Assisted Content Generation
Aug 27, 2024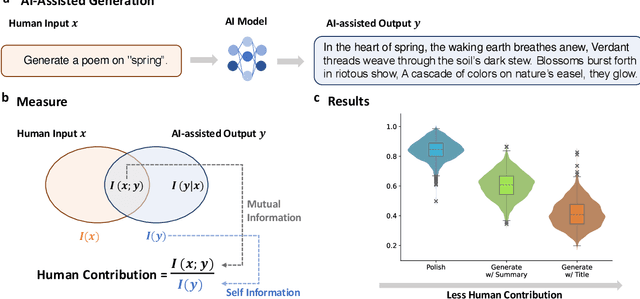

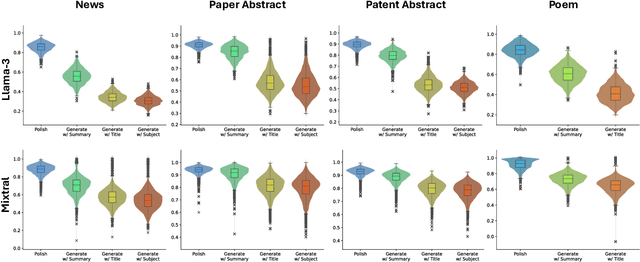
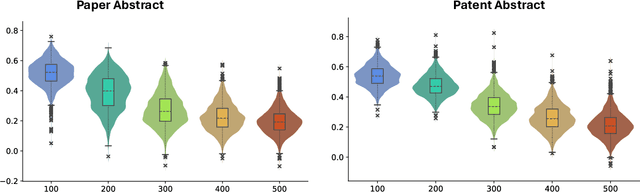
With the growing prevalence of generative artificial intelligence (AI), an increasing amount of content is no longer exclusively generated by humans but by generative AI models with human guidance. This shift presents notable challenges for the delineation of originality due to the varying degrees of human contribution in AI-assisted works. This study raises the research question of measuring human contribution in AI-assisted content generation and introduces a framework to address this question that is grounded in information theory. By calculating mutual information between human input and AI-assisted output relative to self-information of AI-assisted output, we quantify the proportional information contribution of humans in content generation. Our experimental results demonstrate that the proposed measure effectively discriminates between varying degrees of human contribution across multiple creative domains. We hope that this work lays a foundation for measuring human contributions in AI-assisted content generation in the era of generative AI.
LICM: Effective and Efficient Long Interest Chain Modeling for News Recommendation
Aug 01, 2024



Accurately recommending personalized candidate news articles to users has always been the core challenge of news recommendation system. News recommendations often require modeling of user interests to match candidate news. Recent efforts have primarily focused on extract local subgraph information, the lack of a comprehensive global news graph extraction has hindered the ability to utilize global news information collaboratively among similar users. To overcome these limitations, we propose an effective and efficient Long Interest Chain Modeling for News Recommendation(LICM), which combines neighbor interest with long-chain interest distilled from a global news click graph based on the collaborative of similar users to enhance news recommendation. For a global news graph based on the click history of all users, long chain interest generated from it can better utilize the high-dimensional information within it, enhancing the effectiveness of collaborative recommendations. We therefore design a comprehensive selection mechanism and interest encoder to obtain long-chain interest from the global graph. Finally, we use a gated network to integrate long-chain information with neighbor information to achieve the final user representation. Experiment results on real-world datasets validate the effectiveness and efficiency of our model to improve the performance of news recommendation.
FedSampling: A Better Sampling Strategy for Federated Learning
Jun 25, 2023Federated learning (FL) is an important technique for learning models from decentralized data in a privacy-preserving way. Existing FL methods usually uniformly sample clients for local model learning in each round. However, different clients may have significantly different data sizes, and the clients with more data cannot have more opportunities to contribute to model training, which may lead to inferior performance. In this paper, instead of client uniform sampling, we propose a novel data uniform sampling strategy for federated learning (FedSampling), which can effectively improve the performance of federated learning especially when client data size distribution is highly imbalanced across clients. In each federated learning round, local data on each client is randomly sampled for local model learning according to a probability based on the server desired sample size and the total sample size on all available clients. Since the data size on each client is privacy-sensitive, we propose a privacy-preserving way to estimate the total sample size with a differential privacy guarantee. Experiments on four benchmark datasets show that FedSampling can effectively improve the performance of federated learning.
FairVFL: A Fair Vertical Federated Learning Framework with Contrastive Adversarial Learning
Jun 07, 2022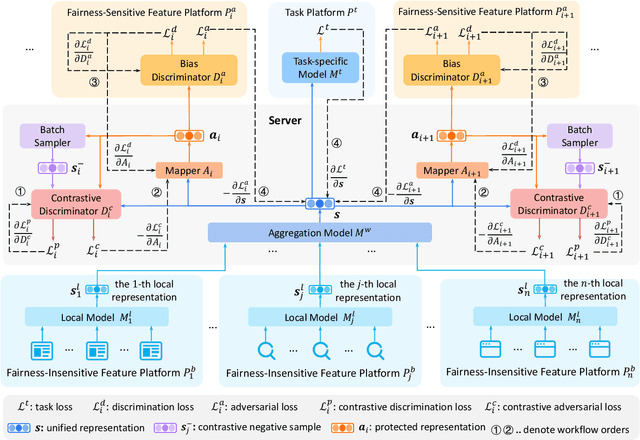
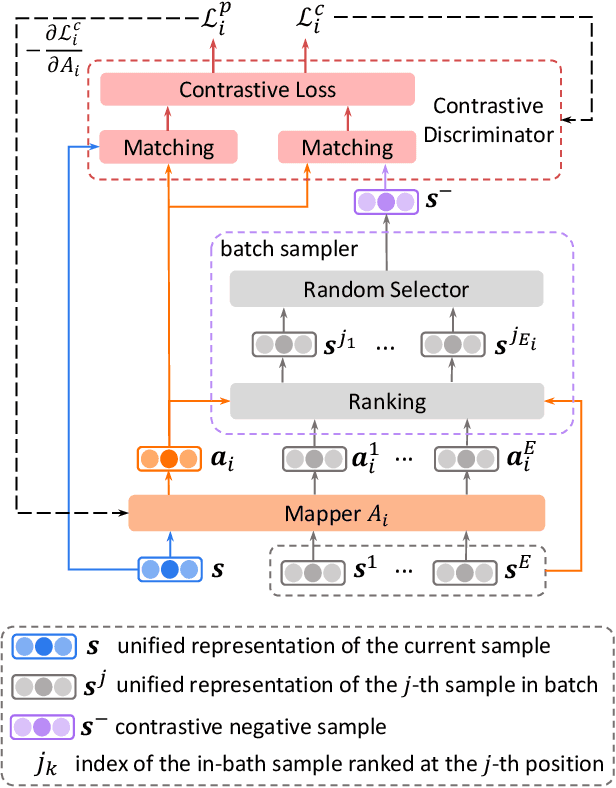
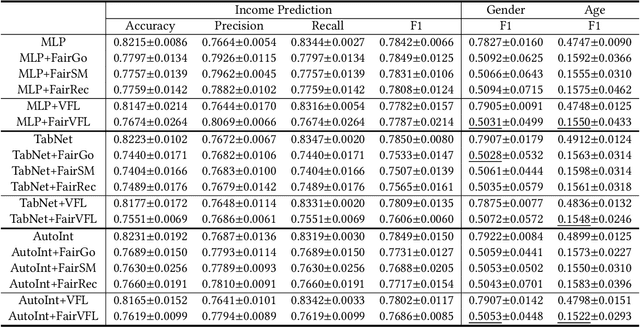
Vertical federated learning (VFL) is a privacy-preserving machine learning paradigm that can learn models from features distributed on different platforms in a privacy-preserving way. Since in real-world applications the data may contain bias on fairness-sensitive features (e.g., gender), VFL models may inherit bias from training data and become unfair for some user groups. However, existing fair ML methods usually rely on the centralized storage of fairness-sensitive features to achieve model fairness, which are usually inapplicable in federated scenarios. In this paper, we propose a fair vertical federated learning framework (FairVFL), which can improve the fairness of VFL models. The core idea of FairVFL is to learn unified and fair representations of samples based on the decentralized feature fields in a privacy-preserving way. Specifically, each platform with fairness-insensitive features first learns local data representations from local features. Then, these local representations are uploaded to a server and aggregated into a unified representation for the target task. In order to learn fair unified representations, we send them to each platform storing fairness-sensitive features and apply adversarial learning to remove bias from the unified representations inherited from the biased data. Moreover, for protecting user privacy, we further propose a contrastive adversarial learning method to remove privacy information from the unified representations in server before sending them to the platforms keeping fairness-sensitive features. Experiments on two real-world datasets validate that our method can effectively improve model fairness with user privacy well-protected.
Robust Quantity-Aware Aggregation for Federated Learning
May 22, 2022
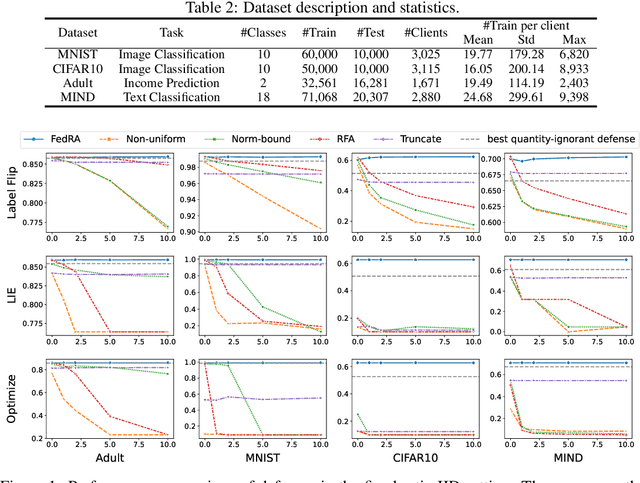
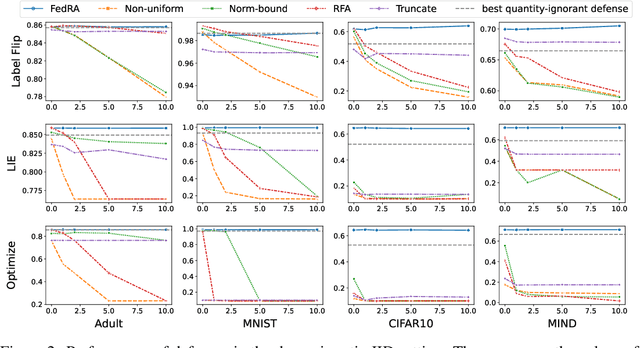
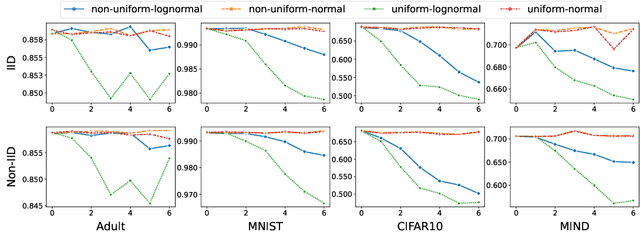
Federated learning (FL) enables multiple clients to collaboratively train models without sharing their local data, and becomes an important privacy-preserving machine learning framework. However, classical FL faces serious security and robustness problem, e.g., malicious clients can poison model updates and at the same time claim large quantities to amplify the impact of their model updates in the model aggregation. Existing defense methods for FL, while all handling malicious model updates, either treat all quantities benign or simply ignore/truncate the quantities of all clients. The former is vulnerable to quantity-enhanced attack, while the latter leads to sub-optimal performance since the local data on different clients is usually in significantly different sizes. In this paper, we propose a robust quantity-aware aggregation algorithm for federated learning, called FedRA, to perform the aggregation with awareness of local data quantities while being able to defend against quantity-enhanced attacks. More specifically, we propose a method to filter malicious clients by jointly considering the uploaded model updates and data quantities from different clients, and performing quantity-aware weighted averaging on model updates from remaining clients. Moreover, as the number of malicious clients participating in the federated learning may dynamically change in different rounds, we also propose a malicious client number estimator to predict how many suspicious clients should be filtered in each round. Experiments on four public datasets demonstrate the effectiveness of our FedRA method in defending FL against quantity-enhanced attacks.
FedCL: Federated Contrastive Learning for Privacy-Preserving Recommendation
Apr 21, 2022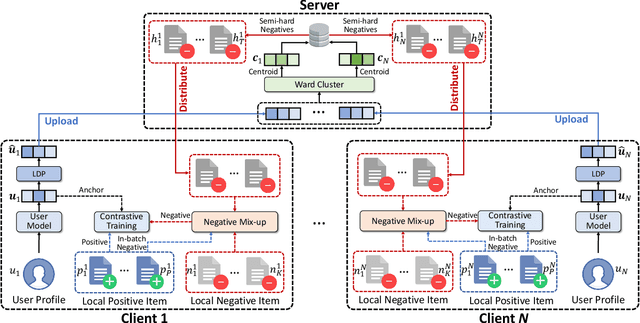
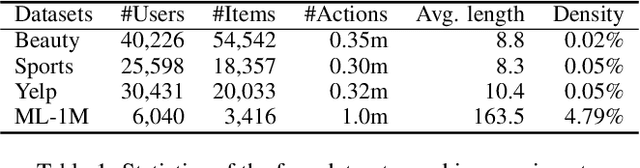

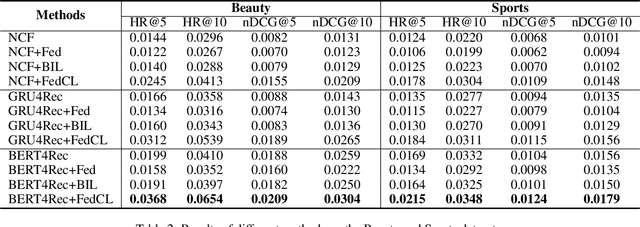
Contrastive learning is widely used for recommendation model learning, where selecting representative and informative negative samples is critical. Existing methods usually focus on centralized data, where abundant and high-quality negative samples are easy to obtain. However, centralized user data storage and exploitation may lead to privacy risks and concerns, while decentralized user data on a single client can be too sparse and biased for accurate contrastive learning. In this paper, we propose a federated contrastive learning method named FedCL for privacy-preserving recommendation, which can exploit high-quality negative samples for effective model training with privacy well protected. We first infer user embeddings from local user data through the local model on each client, and then perturb them with local differential privacy (LDP) before sending them to a central server for hard negative sampling. Since individual user embedding contains heavy noise due to LDP, we propose to cluster user embeddings on the server to mitigate the influence of noise, and the cluster centroids are used to retrieve hard negative samples from the item pool. These hard negative samples are delivered to user clients and mixed with the observed negative samples from local data as well as in-batch negatives constructed from positive samples for federated model training. Extensive experiments on four benchmark datasets show FedCL can empower various recommendation methods in a privacy-preserving way.
FUM: Fine-grained and Fast User Modeling for News Recommendation
Apr 10, 2022
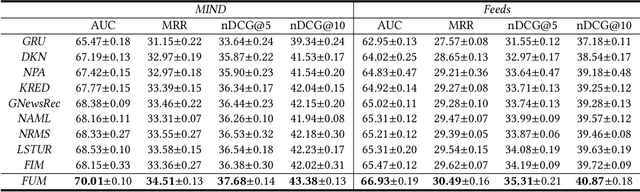
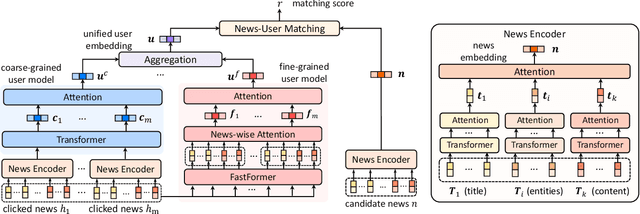
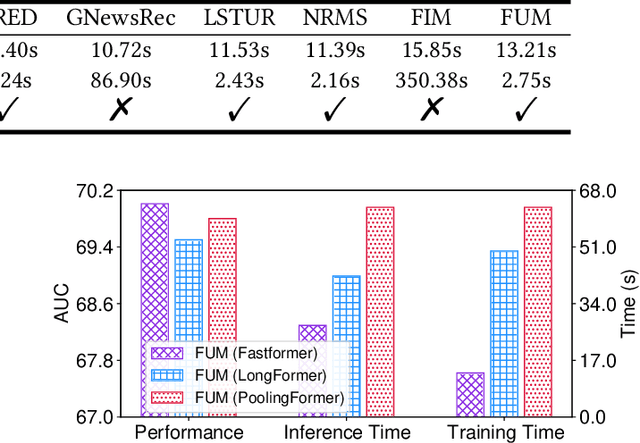
User modeling is important for news recommendation. Existing methods usually first encode user's clicked news into news embeddings independently and then aggregate them into user embedding. However, the word-level interactions across different clicked news from the same user, which contain rich detailed clues to infer user interest, are ignored by these methods. In this paper, we propose a fine-grained and fast user modeling framework (FUM) to model user interest from fine-grained behavior interactions for news recommendation. The core idea of FUM is to concatenate the clicked news into a long document and transform user modeling into a document modeling task with both intra-news and inter-news word-level interactions. Since vanilla transformer cannot efficiently handle long document, we apply an efficient transformer named Fastformer to model fine-grained behavior interactions. Extensive experiments on two real-world datasets verify that FUM can effectively and efficiently model user interest for news recommendation.
News Recommendation with Candidate-aware User Modeling
Apr 10, 2022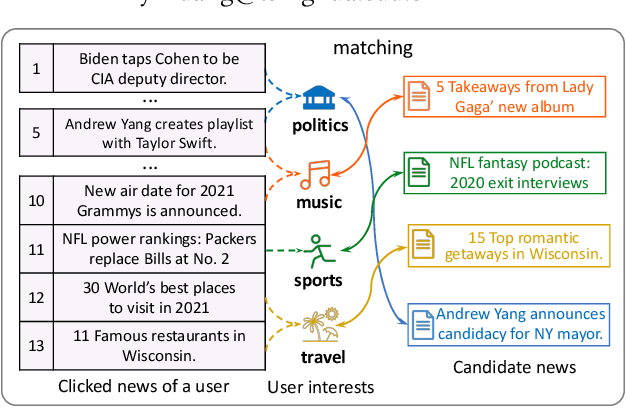
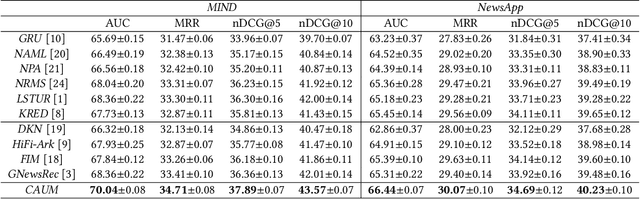
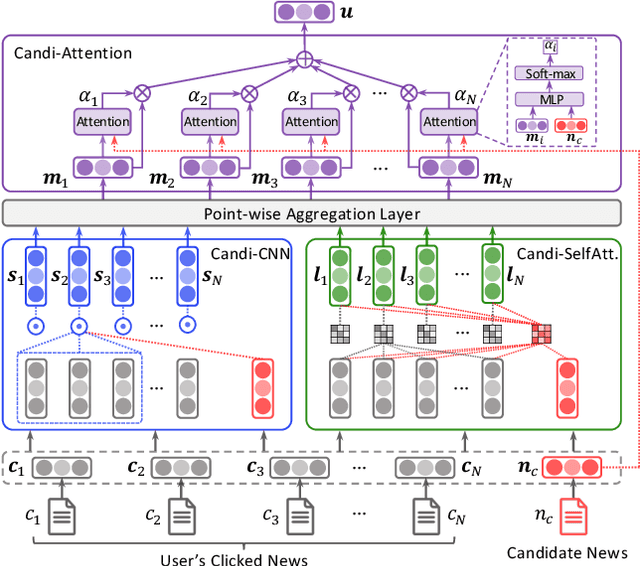

News recommendation aims to match news with personalized user interest. Existing methods for news recommendation usually model user interest from historical clicked news without the consideration of candidate news. However, each user usually has multiple interests, and it is difficult for these methods to accurately match a candidate news with a specific user interest. In this paper, we present a candidate-aware user modeling method for personalized news recommendation, which can incorporate candidate news into user modeling for better matching between candidate news and user interest. We propose a candidate-aware self-attention network that uses candidate news as clue to model candidate-aware global user interest. In addition, we propose a candidate-aware CNN network to incorporate candidate news into local behavior context modeling and learn candidate-aware short-term user interest. Besides, we use a candidate-aware attention network to aggregate previously clicked news weighted by their relevance with candidate news to build candidate-aware user representation. Experiments on real-world datasets show the effectiveness of our method in improving news recommendation performance.