 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGLM-5: from Vibe Coding to Agentic Engineering
Feb 17, 2026We present GLM-5, a next-generation foundation model designed to transition the paradigm of vibe coding to agentic engineering. Building upon the agentic, reasoning, and coding (ARC) capabilities of its predecessor, GLM-5 adopts DSA to significantly reduce training and inference costs while maintaining long-context fidelity. To advance model alignment and autonomy, we implement a new asynchronous reinforcement learning infrastructure that drastically improves post-training efficiency by decoupling generation from training. Furthermore, we propose novel asynchronous agent RL algorithms that further improve RL quality, enabling the model to learn from complex, long-horizon interactions more effectively. Through these innovations, GLM-5 achieves state-of-the-art performance on major open benchmarks. Most critically, GLM-5 demonstrates unprecedented capability in real-world coding tasks, surpassing previous baselines in handling end-to-end software engineering challenges. Code, models, and more information are available at https://github.com/zai-org/GLM-5.
MergeMix: Optimizing Mid-Training Data Mixtures via Learnable Model Merging
Jan 25, 2026Optimizing data mixtures is essential for unlocking the full potential of large language models (LLMs), yet identifying the optimal composition remains computationally prohibitive due to reliance on heuristic trials or expensive proxy training. To address this, we introduce \textbf{MergeMix}, a novel approach that efficiently determines optimal data mixing ratios by repurposing model merging weights as a high-fidelity, low-cost performance proxy. By training domain-specific experts on minimal tokens and optimizing their merging weights against downstream benchmarks, MergeMix effectively optimizes the performance of data mixtures without incurring the cost of full-scale training. Extensive experiments on models with 8B and 16B parameters validate that MergeMix achieves performance comparable to or surpassing exhaustive manual tuning while drastically reducing search costs. Furthermore, MergeMix exhibits high rank consistency (Spearman $ρ> 0.9$) and strong cross-scale transferability, offering a scalable, automated solution for data mixture optimization.
Entropy-Guided Token Dropout: Training Autoregressive Language Models with Limited Domain Data
Dec 29, 2025As access to high-quality, domain-specific data grows increasingly scarce, multi-epoch training has become a practical strategy for adapting large language models (LLMs). However, autoregressive models often suffer from performance degradation under repeated data exposure, where overfitting leads to a marked decline in model capability. Through empirical analysis, we trace this degradation to an imbalance in learning dynamics: predictable, low-entropy tokens are learned quickly and come to dominate optimization, while the model's ability to generalize on high-entropy tokens deteriorates with continued training. To address this, we introduce EntroDrop, an entropy-guided token dropout method that functions as structured data regularization. EntroDrop selectively masks low-entropy tokens during training and employs a curriculum schedule to adjust regularization strength in alignment with training progress. Experiments across model scales from 0.6B to 8B parameters show that EntroDrop consistently outperforms standard regularization baselines and maintains robust performance throughout extended multi-epoch training. These findings underscore the importance of aligning regularization with token-level learning dynamics when training on limited data. Our approach offers a promising pathway toward more effective adaptation of LLMs in data-constrained domains.
URaG: Unified Retrieval and Generation in Multimodal LLMs for Efficient Long Document Understanding
Nov 13, 2025
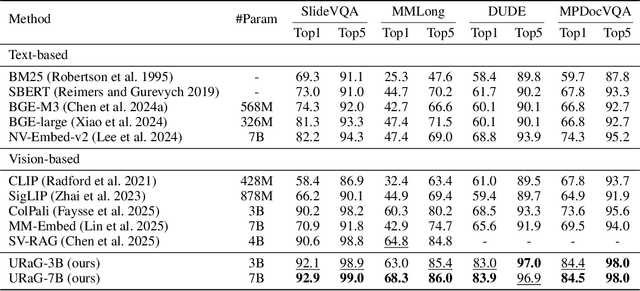
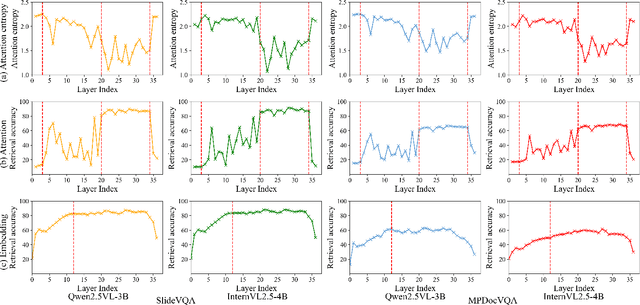
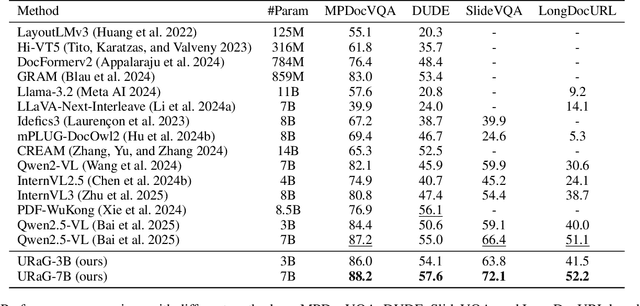
Recent multimodal large language models (MLLMs) still struggle with long document understanding due to two fundamental challenges: information interference from abundant irrelevant content, and the quadratic computational cost of Transformer-based architectures. Existing approaches primarily fall into two categories: token compression, which sacrifices fine-grained details; and introducing external retrievers, which increase system complexity and prevent end-to-end optimization. To address these issues, we conduct an in-depth analysis and observe that MLLMs exhibit a human-like coarse-to-fine reasoning pattern: early Transformer layers attend broadly across the document, while deeper layers focus on relevant evidence pages. Motivated by this insight, we posit that the inherent evidence localization capabilities of MLLMs can be explicitly leveraged to perform retrieval during the reasoning process, facilitating efficient long document understanding. To this end, we propose URaG, a simple-yet-effective framework that Unifies Retrieval and Generation within a single MLLM. URaG introduces a lightweight cross-modal retrieval module that converts the early Transformer layers into an efficient evidence selector, identifying and preserving the most relevant pages while discarding irrelevant content. This design enables the deeper layers to concentrate computational resources on pertinent information, improving both accuracy and efficiency. Extensive experiments demonstrate that URaG achieves state-of-the-art performance while reducing computational overhead by 44-56%. The code is available at https://github.com/shi-yx/URaG.
WSM: Decay-Free Learning Rate Schedule via Checkpoint Merging for LLM Pre-training
Jul 23, 2025Recent advances in learning rate (LR) scheduling have demonstrated the effectiveness of decay-free approaches that eliminate the traditional decay phase while maintaining competitive performance. Model merging techniques have emerged as particularly promising solutions in this domain. We present Warmup-Stable and Merge (WSM), a general framework that establishes a formal connection between learning rate decay and model merging. WSM provides a unified theoretical foundation for emulating various decay strategies-including cosine decay, linear decay and inverse square root decay-as principled model averaging schemes, while remaining fully compatible with diverse optimization methods. Through extensive experiments, we identify merge duration-the training window for checkpoint aggregation-as the most critical factor influencing model performance, surpassing the importance of both checkpoint interval and merge quantity. Our framework consistently outperforms the widely-adopted Warmup-Stable-Decay (WSD) approach across multiple benchmarks, achieving significant improvements of +3.5% on MATH, +2.9% on HumanEval, and +5.5% on MMLU-Pro. The performance advantages extend to supervised fine-tuning scenarios, highlighting WSM's potential for long-term model refinement.
RV-Syn: Rational and Verifiable Mathematical Reasoning Data Synthesis based on Structured Function Library
Apr 29, 2025The advancement of reasoning capabilities in Large Language Models (LLMs) requires substantial amounts of high-quality reasoning data, particularly in mathematics. Existing data synthesis methods, such as data augmentation from annotated training sets or direct question generation based on relevant knowledge points and documents, have expanded datasets but face challenges in mastering the inner logic of the problem during generation and ensuring the verifiability of the solutions. To address these issues, we propose RV-Syn, a novel Rational and Verifiable mathematical Synthesis approach. RV-Syn constructs a structured mathematical operation function library based on initial seed problems and generates computational graphs as solutions by combining Python-formatted functions from this library. These graphs are then back-translated into complex problems. Based on the constructed computation graph, we achieve solution-guided logic-aware problem generation. Furthermore, the executability of the computational graph ensures the verifiability of the solving process. Experimental results show that RV-Syn surpasses existing synthesis methods, including those involving human-generated problems, achieving greater efficient data scaling. This approach provides a scalable framework for generating high-quality reasoning datasets.
HeteRAG: A Heterogeneous Retrieval-augmented Generation Framework with Decoupled Knowledge Representations
Apr 12, 2025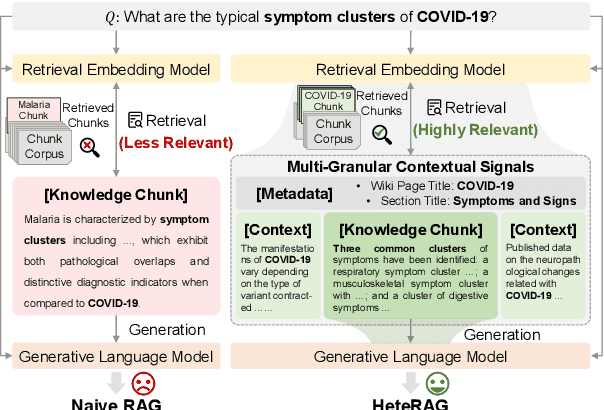

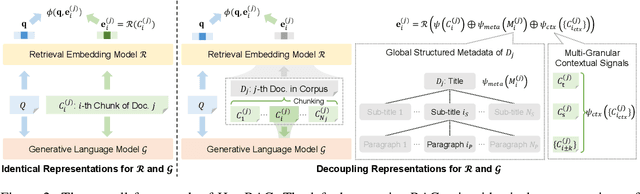

Retrieval-augmented generation (RAG) methods can enhance the performance of LLMs by incorporating retrieved knowledge chunks into the generation process. In general, the retrieval and generation steps usually have different requirements for these knowledge chunks. The retrieval step benefits from comprehensive information to improve retrieval accuracy, whereas excessively long chunks may introduce redundant contextual information, thereby diminishing both the effectiveness and efficiency of the generation process. However, existing RAG methods typically employ identical representations of knowledge chunks for both retrieval and generation, resulting in suboptimal performance. In this paper, we propose a heterogeneous RAG framework (\myname) that decouples the representations of knowledge chunks for retrieval and generation, thereby enhancing the LLMs in both effectiveness and efficiency. Specifically, we utilize short chunks to represent knowledge to adapt the generation step and utilize the corresponding chunk with its contextual information from multi-granular views to enhance retrieval accuracy. We further introduce an adaptive prompt tuning method for the retrieval model to adapt the heterogeneous retrieval augmented generation process. Extensive experiments demonstrate that \myname achieves significant improvements compared to baselines.
YuLan-Mini: An Open Data-efficient Language Model
Dec 24, 2024



Effective pre-training of large language models (LLMs) has been challenging due to the immense resource demands and the complexity of the technical processes involved. This paper presents a detailed technical report on YuLan-Mini, a highly capable base model with 2.42B parameters that achieves top-tier performance among models of similar parameter scale. Our pre-training approach focuses on enhancing training efficacy through three key technical contributions: an elaborate data pipeline combines data cleaning with data schedule strategies, a robust optimization method to mitigate training instability, and an effective annealing approach that incorporates targeted data selection and long context training. Remarkably, YuLan-Mini, trained on 1.08T tokens, achieves performance comparable to industry-leading models that require significantly more data. To facilitate reproduction, we release the full details of the data composition for each training phase. Project details can be accessed at the following link: https://github.com/RUC-GSAI/YuLan-Mini.
Imitate, Explore, and Self-Improve: A Reproduction Report on Slow-thinking Reasoning Systems
Dec 12, 2024


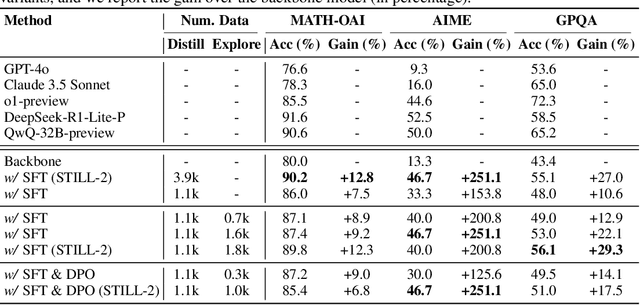
Recently, slow-thinking reasoning systems, such as o1, have demonstrated remarkable capabilities in solving complex reasoning tasks. These systems typically engage in an extended thinking process before responding to a query, allowing them to generate more thorough, accurate, and well-reasoned solutions. These systems are primarily developed and maintained by industry, with their core techniques not publicly disclosed. In response, an increasing number of studies from the research community aim to explore the technical foundations underlying these powerful reasoning systems. Building on these prior efforts, this paper presents a reproduction report on implementing o1-like reasoning systems. We introduce an "imitate, explore, and self-improve" framework as our primary technical approach to train the reasoning model. In the initial phase, we use distilled long-form thought data to fine-tune the reasoning model, enabling it to invoke a slow-thinking mode. The model is then encouraged to explore challenging problems by generating multiple rollouts, which can result in increasingly more high-quality trajectories that lead to correct answers. Furthermore, the model undergoes self-improvement by iteratively refining its training dataset. To verify the effectiveness of this approach, we conduct extensive experiments on three challenging benchmarks. The experimental results demonstrate that our approach achieves competitive performance compared to industry-level reasoning systems on these benchmarks.
Technical Report: Enhancing LLM Reasoning with Reward-guided Tree Search
Nov 18, 2024



Recently, test-time scaling has garnered significant attention from the research community, largely due to the substantial advancements of the o1 model released by OpenAI. By allocating more computational resources during the inference phase, large language models~(LLMs) can extensively explore the solution space by generating more thought tokens or diverse solutions, thereby producing more accurate responses. However, developing an o1-like reasoning approach is challenging, and researchers have been making various attempts to advance this open area of research. In this paper, we present a preliminary exploration into enhancing the reasoning abilities of LLMs through reward-guided tree search algorithms. This framework is implemented by integrating the policy model, reward model, and search algorithm. It is primarily constructed around a tree search algorithm, where the policy model navigates a dynamically expanding tree guided by a specially trained reward model. We thoroughly explore various design considerations necessary for implementing this framework and provide a detailed report of the technical aspects. To assess the effectiveness of our approach, we focus on mathematical reasoning tasks and conduct extensive evaluations on four challenging datasets, significantly enhancing the reasoning abilities of LLMs.