 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDocLayLLM: An Efficient and Effective Multi-modal Extension of Large Language Models for Text-rich Document Understanding
Paper and Code
Aug 27, 2024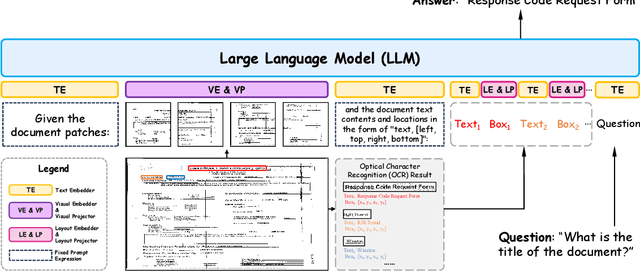
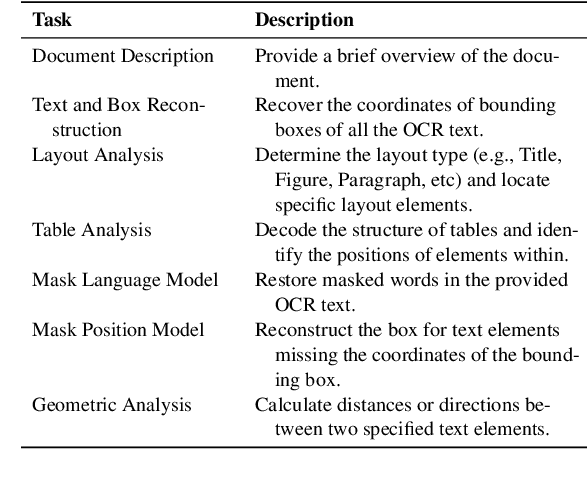


Text-rich document understanding (TDU) refers to analyzing and comprehending documents containing substantial textual content. With the rapid evolution of large language models (LLMs), they have been widely leveraged for TDU due to their remarkable versatility and generalization. In this paper, we introduce DocLayLLM, an efficient and effective multi-modal extension of LLMs specifically designed for TDU. By integrating visual patch tokens and 2D positional tokens into LLMs and encoding the document content using the LLMs themselves, we fully take advantage of the document comprehension capability of LLMs and enhance their perception of OCR information. We have also deeply considered the role of the chain-of-thought (CoT) and innovatively proposed the techniques of CoT Pre-training and CoT Annealing. Our DocLayLLM can achieve remarkable performances with lightweight training settings, showcasing its efficiency and effectiveness. Experimental results demonstrate that our DocLayLLM surpasses existing OCR-dependent methods and also outperforms OCR-free competitors.