 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTextShield-R1: Reinforced Reasoning for Tampered Text Detection
Feb 23, 2026The growing prevalence of tampered images poses serious security threats, highlighting the urgent need for reliable detection methods. Multimodal large language models (MLLMs) demonstrate strong potential in analyzing tampered images and generating interpretations. However, they still struggle with identifying micro-level artifacts, exhibit low accuracy in localizing tampered text regions, and heavily rely on expensive annotations for forgery interpretation. To this end, we introduce TextShield-R1, the first reinforcement learning based MLLM solution for tampered text detection and reasoning. Specifically, our approach introduces Forensic Continual Pre-training, an easy-to-hard curriculum that well prepares the MLLM for tampered text detection by harnessing the large-scale cheap data from natural image forensic and OCR tasks. During fine-tuning, we perform Group Relative Policy Optimization with novel reward functions to reduce annotation dependency and improve reasoning capabilities. At inference time, we enhance localization accuracy via OCR Rectification, a method that leverages the MLLM's strong text recognition abilities to refine its predictions. Furthermore, to support rigorous evaluation, we introduce the Text Forensics Reasoning (TFR) benchmark, comprising over 45k real and tampered images across 16 languages, 10 tampering techniques, and diverse domains. Rich reasoning-style annotations are included, allowing for comprehensive assessment. Our TFR benchmark simultaneously addresses seven major limitations of existing benchmarks and enables robust evaluation under cross-style, cross-method, and cross-language conditions. Extensive experiments demonstrate that TextShield-R1 significantly advances the state of the art in interpretable tampered text detection.
Training-Free Acceleration for Document Parsing Vision-Language Model with Hierarchical Speculative Decoding
Feb 13, 2026Document parsing is a fundamental task in multimodal understanding, supporting a wide range of downstream applications such as information extraction and intelligent document analysis. Benefiting from strong semantic modeling and robust generalization, VLM-based end-to-end approaches have emerged as the mainstream paradigm in recent years. However, these models often suffer from substantial inference latency, as they must auto-regressively generate long token sequences when processing long-form documents. In this work, motivated by the extremely long outputs and complex layout structures commonly found in document parsing, we propose a training-free and highly efficient acceleration method. Inspired by speculative decoding, we employ a lightweight document parsing pipeline as a draft model to predict batches of future tokens, while the more accurate VLM verifies these draft predictions in parallel. Moreover, we further exploit the layout-structured nature of documents by partitioning each page into independent regions, enabling parallel decoding of each region using the same draft-verify strategy. The final predictions are then assembled according to the natural reading order. Experimental results demonstrate the effectiveness of our approach: on the general-purpose OmniDocBench, our method provides a 2.42x lossless acceleration for the dots.ocr model, and achieves up to 4.89x acceleration on long-document parsing tasks. We will release our code to facilitate reproducibility and future research.
PosterVerse: A Full-Workflow Framework for Commercial-Grade Poster Generation with HTML-Based Scalable Typography
Jan 07, 2026Commercial-grade poster design demands the seamless integration of aesthetic appeal with precise, informative content delivery. Current automated poster generation systems face significant limitations, including incomplete design workflows, poor text rendering accuracy, and insufficient flexibility for commercial applications. To address these challenges, we propose PosterVerse, a full-workflow, commercial-grade poster generation method that seamlessly automates the entire design process while delivering high-density and scalable text rendering. PosterVerse replicates professional design through three key stages: (1) blueprint creation using fine-tuned LLMs to extract key design elements from user requirements, (2) graphical background generation via customized diffusion models to create visually appealing imagery, and (3) unified layout-text rendering with an MLLM-powered HTML engine to guarantee high text accuracy and flexible customization. In addition, we introduce PosterDNA, a commercial-grade, HTML-based dataset tailored for training and validating poster design models. To the best of our knowledge, PosterDNA is the first Chinese poster generation dataset to introduce HTML typography files, enabling scalable text rendering and fundamentally solving the challenges of rendering small and high-density text. Experimental results demonstrate that PosterVerse consistently produces commercial-grade posters with appealing visuals, accurate text alignment, and customizable layouts, making it a promising solution for automating commercial poster design. The code and model are available at https://github.com/wuhaer/PosterVerse.
ContextDrag: Precise Drag-Based Image Editing via Context-Preserving Token Injection and Position-Consistent Attention
Dec 09, 2025Drag-based image editing aims to modify visual content followed by user-specified drag operations. Despite existing methods having made notable progress, they still fail to fully exploit the contextual information in the reference image, including fine-grained texture details, leading to edits with limited coherence and fidelity. To address this challenge, we introduce ContextDrag, a new paradigm for drag-based editing that leverages the strong contextual modeling capability of editing models, such as FLUX-Kontext. By incorporating VAE-encoded features from the reference image, ContextDrag can leverage rich contextual cues and preserve fine-grained details, without the need for finetuning or inversion. Specifically, ContextDrag introduced a novel Context-preserving Token Injection (CTI) that injects noise-free reference features into their correct destination locations via a Latent-space Reverse Mapping (LRM) algorithm. This strategy enables precise drag control while preserving consistency in both semantics and texture details. Second, ContextDrag adopts a novel Position-Consistent Attention (PCA), which positional re-encodes the reference tokens and applies overlap-aware masking to eliminate interference from irrelevant reference features. Extensive experiments on DragBench-SR and DragBench-DR demonstrate that our approach surpasses all existing SOTA methods. Code will be publicly available.
URaG: Unified Retrieval and Generation in Multimodal LLMs for Efficient Long Document Understanding
Nov 13, 2025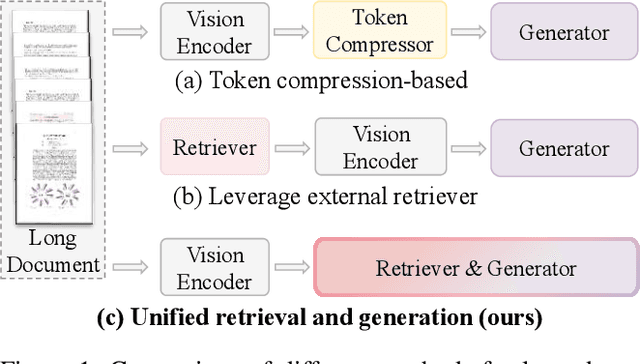
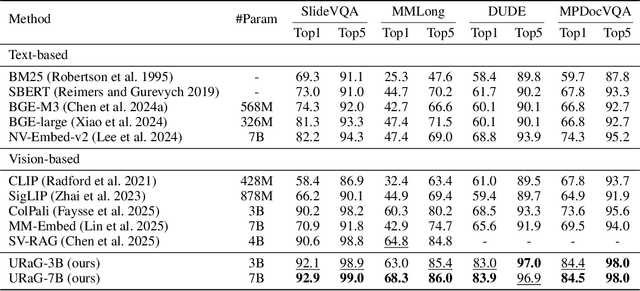
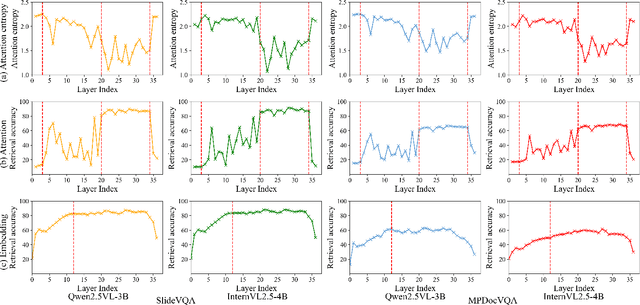
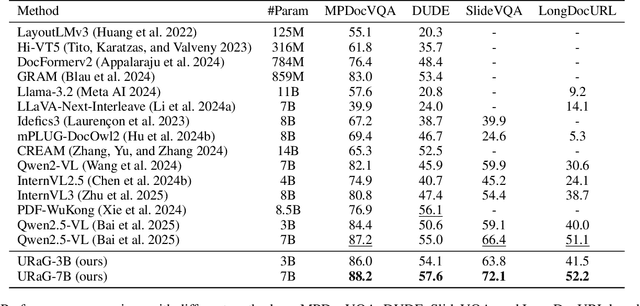
Recent multimodal large language models (MLLMs) still struggle with long document understanding due to two fundamental challenges: information interference from abundant irrelevant content, and the quadratic computational cost of Transformer-based architectures. Existing approaches primarily fall into two categories: token compression, which sacrifices fine-grained details; and introducing external retrievers, which increase system complexity and prevent end-to-end optimization. To address these issues, we conduct an in-depth analysis and observe that MLLMs exhibit a human-like coarse-to-fine reasoning pattern: early Transformer layers attend broadly across the document, while deeper layers focus on relevant evidence pages. Motivated by this insight, we posit that the inherent evidence localization capabilities of MLLMs can be explicitly leveraged to perform retrieval during the reasoning process, facilitating efficient long document understanding. To this end, we propose URaG, a simple-yet-effective framework that Unifies Retrieval and Generation within a single MLLM. URaG introduces a lightweight cross-modal retrieval module that converts the early Transformer layers into an efficient evidence selector, identifying and preserving the most relevant pages while discarding irrelevant content. This design enables the deeper layers to concentrate computational resources on pertinent information, improving both accuracy and efficiency. Extensive experiments demonstrate that URaG achieves state-of-the-art performance while reducing computational overhead by 44-56%. The code is available at https://github.com/shi-yx/URaG.
Webly-Supervised Image Manipulation Localization via Category-Aware Auto-Annotation
Aug 28, 2025
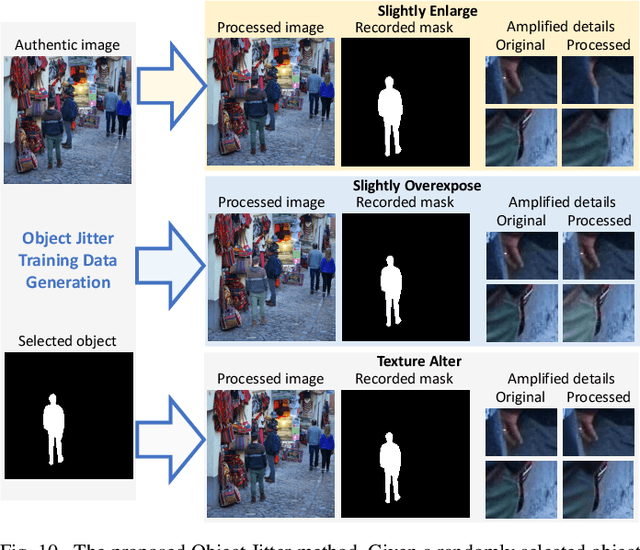
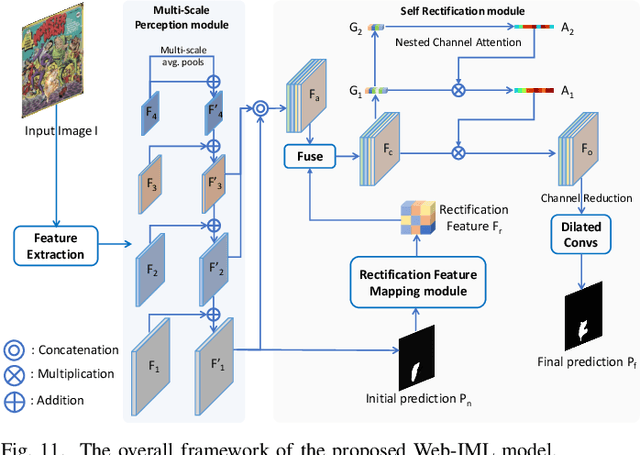

Images manipulated using image editing tools can mislead viewers and pose significant risks to social security. However, accurately localizing the manipulated regions within an image remains a challenging problem. One of the main barriers in this area is the high cost of data acquisition and the severe lack of high-quality annotated datasets. To address this challenge, we introduce novel methods that mitigate data scarcity by leveraging readily available web data. We utilize a large collection of manually forged images from the web, as well as automatically generated annotations derived from a simpler auxiliary task, constrained image manipulation localization. Specifically, we introduce a new paradigm CAAAv2, which automatically and accurately annotates manipulated regions at the pixel level. To further improve annotation quality, we propose a novel metric, QES, which filters out unreliable annotations. Through CAAA v2 and QES, we construct MIMLv2, a large-scale, diverse, and high-quality dataset containing 246,212 manually forged images with pixel-level mask annotations. This is over 120x larger than existing handcrafted datasets like IMD20. Additionally, we introduce Object Jitter, a technique that further enhances model training by generating high-quality manipulation artifacts. Building on these advances, we develop a new model, Web-IML, designed to effectively leverage web-scale supervision for the image manipulation localization task. Extensive experiments demonstrate that our approach substantially alleviates the data scarcity problem and significantly improves the performance of various models on multiple real-world forgery benchmarks. With the proposed web supervision, Web-IML achieves a striking performance gain of 31% and surpasses previous SOTA TruFor by 24.1 average IoU points. The dataset and code will be made publicly available at https://github.com/qcf-568/MIML.
MCCD: A Multi-Attribute Chinese Calligraphy Character Dataset Annotated with Script Styles, Dynasties, and Calligraphers
Jul 09, 2025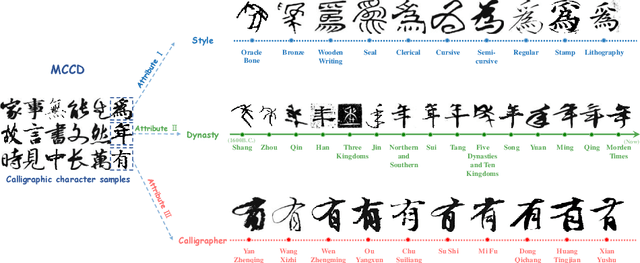
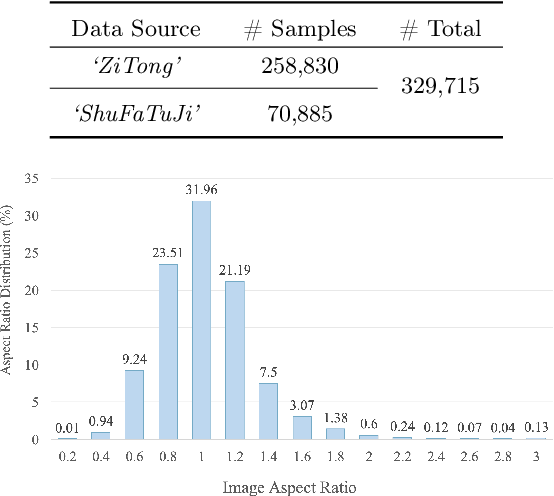
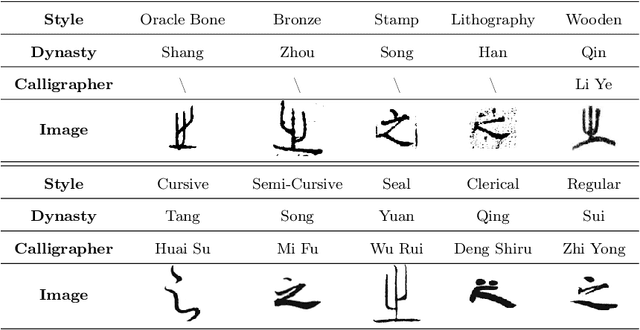
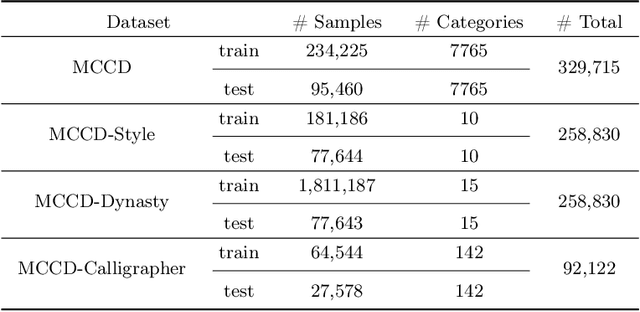
Research on the attribute information of calligraphy, such as styles, dynasties, and calligraphers, holds significant cultural and historical value. However, the styles of Chinese calligraphy characters have evolved dramatically through different dynasties and the unique touches of calligraphers, making it highly challenging to accurately recognize these different characters and their attributes. Furthermore, existing calligraphic datasets are extremely scarce, and most provide only character-level annotations without additional attribute information. This limitation has significantly hindered the in-depth study of Chinese calligraphy. To fill this gap, we present a novel Multi-Attribute Chinese Calligraphy Character Dataset (MCCD). The dataset encompasses 7,765 categories with a total of 329,715 isolated image samples of Chinese calligraphy characters, and three additional subsets were extracted based on the attribute labeling of the three types of script styles (10 types), dynasties (15 periods) and calligraphers (142 individuals). The rich multi-attribute annotations render MCCD well-suited diverse research tasks, including calligraphic character recognition, writer identification, and evolutionary studies of Chinese characters. We establish benchmark performance through single-task and multi-task recognition experiments across MCCD and all of its subsets. The experimental results demonstrate that the complexity of the stroke structure of the calligraphic characters, and the interplay between their different attributes, leading to a substantial increase in the difficulty of accurate recognition. MCCD not only fills a void in the availability of detailed calligraphy datasets but also provides valuable resources for advancing research in Chinese calligraphy and fostering advancements in multiple fields. The dataset is available at https://github.com/SCUT-DLVCLab/MCCD.
MegaHan97K: A Large-Scale Dataset for Mega-Category Chinese Character Recognition with over 97K Categories
Jun 05, 2025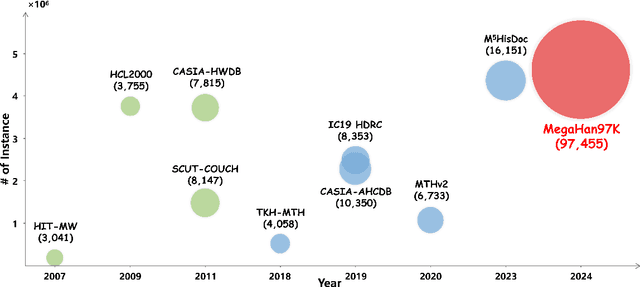



Foundational to the Chinese language and culture, Chinese characters encompass extraordinarily extensive and ever-expanding categories, with the latest Chinese GB18030-2022 standard containing 87,887 categories. The accurate recognition of this vast number of characters, termed mega-category recognition, presents a formidable yet crucial challenge for cultural heritage preservation and digital applications. Despite significant advances in Optical Character Recognition (OCR), mega-category recognition remains unexplored due to the absence of comprehensive datasets, with the largest existing dataset containing merely 16,151 categories. To bridge this critical gap, we introduce MegaHan97K, a mega-category, large-scale dataset covering an unprecedented 97,455 categories of Chinese characters. Our work offers three major contributions: (1) MegaHan97K is the first dataset to fully support the latest GB18030-2022 standard, providing at least six times more categories than existing datasets; (2) It effectively addresses the long-tail distribution problem by providing balanced samples across all categories through its three distinct subsets: handwritten, historical and synthetic subsets; (3) Comprehensive benchmarking experiments reveal new challenges in mega-category scenarios, including increased storage demands, morphologically similar character recognition, and zero-shot learning difficulties, while also unlocking substantial opportunities for future research. To the best of our knowledge, the MetaHan97K is likely the dataset with the largest classes not only in the field of OCR but may also in the broader domain of pattern recognition. The dataset is available at https://github.com/SCUT-DLVCLab/MegaHan97K.
OCR-Reasoning Benchmark: Unveiling the True Capabilities of MLLMs in Complex Text-Rich Image Reasoning
May 22, 2025Recent advancements in multimodal slow-thinking systems have demonstrated remarkable performance across diverse visual reasoning tasks. However, their capabilities in text-rich image reasoning tasks remain understudied due to the lack of a systematic benchmark. To address this gap, we propose OCR-Reasoning, a comprehensive benchmark designed to systematically assess Multimodal Large Language Models on text-rich image reasoning tasks. The benchmark comprises 1,069 human-annotated examples spanning 6 core reasoning abilities and 18 practical reasoning tasks in text-rich visual scenarios. Furthermore, unlike other text-rich image understanding benchmarks that only annotate the final answers, OCR-Reasoning also annotates the reasoning process simultaneously. With the annotated reasoning process and the final answers, OCR-Reasoning evaluates not only the final answers generated by models but also their reasoning processes, enabling a holistic analysis of their problem-solving abilities. Leveraging this benchmark, we conducted a comprehensive evaluation of state-of-the-art MLLMs. Our results demonstrate the limitations of existing methodologies. Notably, even state-of-the-art MLLMs exhibit substantial difficulties, with none achieving accuracy surpassing 50\% across OCR-Reasoning, indicating that the challenges of text-rich image reasoning are an urgent issue to be addressed. The benchmark and evaluation scripts are available at https://github.com/SCUT-DLVCLab/OCR-Reasoning.
Visual Text Processing: A Comprehensive Review and Unified Evaluation
Apr 30, 2025



Visual text is a crucial component in both document and scene images, conveying rich semantic information and attracting significant attention in the computer vision community. Beyond traditional tasks such as text detection and recognition, visual text processing has witnessed rapid advancements driven by the emergence of foundation models, including text image reconstruction and text image manipulation. Despite significant progress, challenges remain due to the unique properties that differentiate text from general objects. Effectively capturing and leveraging these distinct textual characteristics is essential for developing robust visual text processing models. In this survey, we present a comprehensive, multi-perspective analysis of recent advancements in visual text processing, focusing on two key questions: (1) What textual features are most suitable for different visual text processing tasks? (2) How can these distinctive text features be effectively incorporated into processing frameworks? Furthermore, we introduce VTPBench, a new benchmark that encompasses a broad range of visual text processing datasets. Leveraging the advanced visual quality assessment capabilities of multimodal large language models (MLLMs), we propose VTPScore, a novel evaluation metric designed to ensure fair and reliable evaluation. Our empirical study with more than 20 specific models reveals substantial room for improvement in the current techniques. Our aim is to establish this work as a fundamental resource that fosters future exploration and innovation in the dynamic field of visual text processing. The relevant repository is available at https://github.com/shuyansy/Visual-Text-Processing-survey.