 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePosterVerse: A Full-Workflow Framework for Commercial-Grade Poster Generation with HTML-Based Scalable Typography
Jan 07, 2026Commercial-grade poster design demands the seamless integration of aesthetic appeal with precise, informative content delivery. Current automated poster generation systems face significant limitations, including incomplete design workflows, poor text rendering accuracy, and insufficient flexibility for commercial applications. To address these challenges, we propose PosterVerse, a full-workflow, commercial-grade poster generation method that seamlessly automates the entire design process while delivering high-density and scalable text rendering. PosterVerse replicates professional design through three key stages: (1) blueprint creation using fine-tuned LLMs to extract key design elements from user requirements, (2) graphical background generation via customized diffusion models to create visually appealing imagery, and (3) unified layout-text rendering with an MLLM-powered HTML engine to guarantee high text accuracy and flexible customization. In addition, we introduce PosterDNA, a commercial-grade, HTML-based dataset tailored for training and validating poster design models. To the best of our knowledge, PosterDNA is the first Chinese poster generation dataset to introduce HTML typography files, enabling scalable text rendering and fundamentally solving the challenges of rendering small and high-density text. Experimental results demonstrate that PosterVerse consistently produces commercial-grade posters with appealing visuals, accurate text alignment, and customizable layouts, making it a promising solution for automating commercial poster design. The code and model are available at https://github.com/wuhaer/PosterVerse.
Do Latent Tokens Think? A Causal and Adversarial Analysis of Chain-of-Continuous-Thought
Dec 25, 2025Latent tokens are gaining attention for enhancing reasoning in large language models (LLMs), yet their internal mechanisms remain unclear. This paper examines the problem from a reliability perspective, uncovering fundamental weaknesses: latent tokens function as uninterpretable placeholders rather than encoding faithful reasoning. While resistant to perturbation, they promote shortcut usage over genuine reasoning. We focus on Chain-of-Continuous-Thought (COCONUT), which claims better efficiency and stability than explicit Chain-of-Thought (CoT) while maintaining performance. We investigate this through two complementary approaches. First, steering experiments perturb specific token subsets, namely COCONUT and explicit CoT. Unlike CoT tokens, COCONUT tokens show minimal sensitivity to steering and lack reasoning-critical information. Second, shortcut experiments evaluate models under biased and out-of-distribution settings. Results on MMLU and HotpotQA demonstrate that COCONUT consistently exploits dataset artifacts, inflating benchmark performance without true reasoning. These findings reposition COCONUT as a pseudo-reasoning mechanism: it generates plausible traces that conceal shortcut dependence rather than faithfully representing reasoning processes.
Quantize More, Lose Less: Autoregressive Generation from Residually Quantized Speech Representations
Jul 16, 2025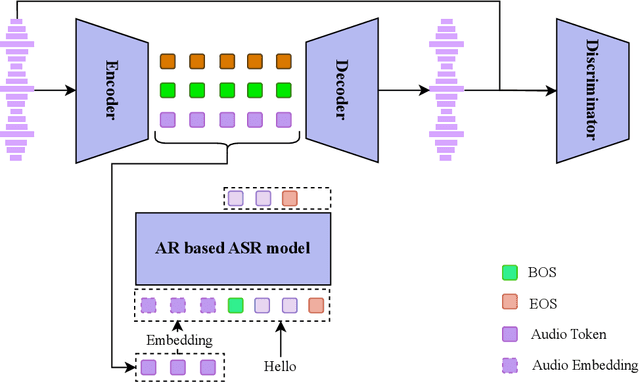

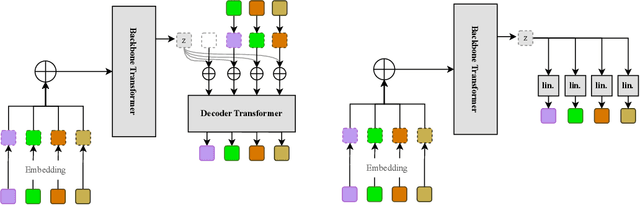
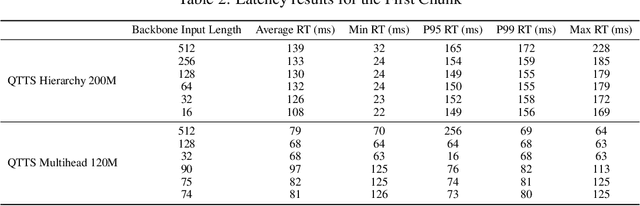
Text-to-speech (TTS) synthesis has seen renewed progress under the discrete modeling paradigm. Existing autoregressive approaches often rely on single-codebook representations, which suffer from significant information loss. Even with post-hoc refinement techniques such as flow matching, these methods fail to recover fine-grained details (e.g., prosodic nuances, speaker-specific timbres), especially in challenging scenarios like singing voice or music synthesis. We propose QTTS, a novel TTS framework built upon our new audio codec, QDAC. The core innovation of QDAC lies in its end-to-end training of an ASR-based auto-regressive network with a GAN, which achieves superior semantic feature disentanglement for scalable, near-lossless compression. QTTS models these discrete codes using two innovative strategies: the Hierarchical Parallel architecture, which uses a dual-AR structure to model inter-codebook dependencies for higher-quality synthesis, and the Delay Multihead approach, which employs parallelized prediction with a fixed delay to accelerate inference speed. Our experiments demonstrate that the proposed framework achieves higher synthesis quality and better preserves expressive content compared to baseline. This suggests that scaling up compression via multi-codebook modeling is a promising direction for high-fidelity, general-purpose speech and audio generation.
MCCD: A Multi-Attribute Chinese Calligraphy Character Dataset Annotated with Script Styles, Dynasties, and Calligraphers
Jul 09, 2025Research on the attribute information of calligraphy, such as styles, dynasties, and calligraphers, holds significant cultural and historical value. However, the styles of Chinese calligraphy characters have evolved dramatically through different dynasties and the unique touches of calligraphers, making it highly challenging to accurately recognize these different characters and their attributes. Furthermore, existing calligraphic datasets are extremely scarce, and most provide only character-level annotations without additional attribute information. This limitation has significantly hindered the in-depth study of Chinese calligraphy. To fill this gap, we present a novel Multi-Attribute Chinese Calligraphy Character Dataset (MCCD). The dataset encompasses 7,765 categories with a total of 329,715 isolated image samples of Chinese calligraphy characters, and three additional subsets were extracted based on the attribute labeling of the three types of script styles (10 types), dynasties (15 periods) and calligraphers (142 individuals). The rich multi-attribute annotations render MCCD well-suited diverse research tasks, including calligraphic character recognition, writer identification, and evolutionary studies of Chinese characters. We establish benchmark performance through single-task and multi-task recognition experiments across MCCD and all of its subsets. The experimental results demonstrate that the complexity of the stroke structure of the calligraphic characters, and the interplay between their different attributes, leading to a substantial increase in the difficulty of accurate recognition. MCCD not only fills a void in the availability of detailed calligraphy datasets but also provides valuable resources for advancing research in Chinese calligraphy and fostering advancements in multiple fields. The dataset is available at https://github.com/SCUT-DLVCLab/MCCD.
MegaHan97K: A Large-Scale Dataset for Mega-Category Chinese Character Recognition with over 97K Categories
Jun 05, 2025Foundational to the Chinese language and culture, Chinese characters encompass extraordinarily extensive and ever-expanding categories, with the latest Chinese GB18030-2022 standard containing 87,887 categories. The accurate recognition of this vast number of characters, termed mega-category recognition, presents a formidable yet crucial challenge for cultural heritage preservation and digital applications. Despite significant advances in Optical Character Recognition (OCR), mega-category recognition remains unexplored due to the absence of comprehensive datasets, with the largest existing dataset containing merely 16,151 categories. To bridge this critical gap, we introduce MegaHan97K, a mega-category, large-scale dataset covering an unprecedented 97,455 categories of Chinese characters. Our work offers three major contributions: (1) MegaHan97K is the first dataset to fully support the latest GB18030-2022 standard, providing at least six times more categories than existing datasets; (2) It effectively addresses the long-tail distribution problem by providing balanced samples across all categories through its three distinct subsets: handwritten, historical and synthetic subsets; (3) Comprehensive benchmarking experiments reveal new challenges in mega-category scenarios, including increased storage demands, morphologically similar character recognition, and zero-shot learning difficulties, while also unlocking substantial opportunities for future research. To the best of our knowledge, the MetaHan97K is likely the dataset with the largest classes not only in the field of OCR but may also in the broader domain of pattern recognition. The dataset is available at https://github.com/SCUT-DLVCLab/MegaHan97K.
NTIRE 2025 Challenge on Image Super-Resolution ($\times$4): Methods and Results
Apr 20, 2025This paper presents the NTIRE 2025 image super-resolution ($\times$4) challenge, one of the associated competitions of the 10th NTIRE Workshop at CVPR 2025. The challenge aims to recover high-resolution (HR) images from low-resolution (LR) counterparts generated through bicubic downsampling with a $\times$4 scaling factor. The objective is to develop effective network designs or solutions that achieve state-of-the-art SR performance. To reflect the dual objectives of image SR research, the challenge includes two sub-tracks: (1) a restoration track, emphasizes pixel-wise accuracy and ranks submissions based on PSNR; (2) a perceptual track, focuses on visual realism and ranks results by a perceptual score. A total of 286 participants registered for the competition, with 25 teams submitting valid entries. This report summarizes the challenge design, datasets, evaluation protocol, the main results, and methods of each team. The challenge serves as a benchmark to advance the state of the art and foster progress in image SR.
Predicting the Original Appearance of Damaged Historical Documents
Dec 16, 2024



Historical documents encompass a wealth of cultural treasures but suffer from severe damages including character missing, paper damage, and ink erosion over time. However, existing document processing methods primarily focus on binarization, enhancement, etc., neglecting the repair of these damages. To this end, we present a new task, termed Historical Document Repair (HDR), which aims to predict the original appearance of damaged historical documents. To fill the gap in this field, we propose a large-scale dataset HDR28K and a diffusion-based network DiffHDR for historical document repair. Specifically, HDR28K contains 28,552 damaged-repaired image pairs with character-level annotations and multi-style degradations. Moreover, DiffHDR augments the vanilla diffusion framework with semantic and spatial information and a meticulously designed character perceptual loss for contextual and visual coherence. Experimental results demonstrate that the proposed DiffHDR trained using HDR28K significantly surpasses existing approaches and exhibits remarkable performance in handling real damaged documents. Notably, DiffHDR can also be extended to document editing and text block generation, showcasing its high flexibility and generalization capacity. We believe this study could pioneer a new direction of document processing and contribute to the inheritance of invaluable cultures and civilizations. The dataset and code is available at https://github.com/yeungchenwa/HDR.
* Accepted to AAAI 2025; Github Page: https://github.com/yeungchenwa/HDR
HierCode: A Lightweight Hierarchical Codebook for Zero-shot Chinese Text Recognition
Mar 20, 2024

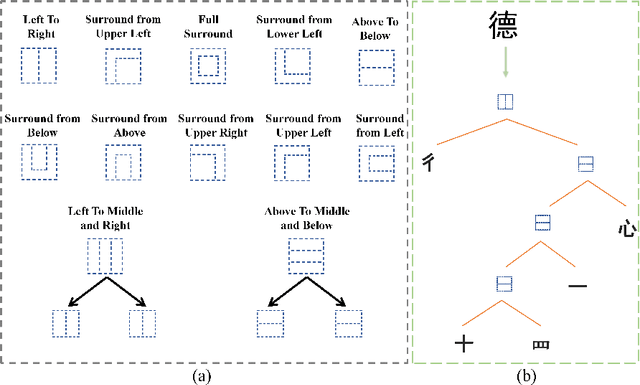

Text recognition, especially for complex scripts like Chinese, faces unique challenges due to its intricate character structures and vast vocabulary. Traditional one-hot encoding methods struggle with the representation of hierarchical radicals, recognition of Out-Of-Vocabulary (OOV) characters, and on-device deployment due to their computational intensity. To address these challenges, we propose HierCode, a novel and lightweight codebook that exploits the innate hierarchical nature of Chinese characters. HierCode employs a multi-hot encoding strategy, leveraging hierarchical binary tree encoding and prototype learning to create distinctive, informative representations for each character. This approach not only facilitates zero-shot recognition of OOV characters by utilizing shared radicals and structures but also excels in line-level recognition tasks by computing similarity with visual features, a notable advantage over existing methods. Extensive experiments across diverse benchmarks, including handwritten, scene, document, web, and ancient text, have showcased HierCode's superiority for both conventional and zero-shot Chinese character or text recognition, exhibiting state-of-the-art performance with significantly fewer parameters and fast inference speed.
FontDiffuser: One-Shot Font Generation via Denoising Diffusion with Multi-Scale Content Aggregation and Style Contrastive Learning
Dec 19, 2023Automatic font generation is an imitation task, which aims to create a font library that mimics the style of reference images while preserving the content from source images. Although existing font generation methods have achieved satisfactory performance, they still struggle with complex characters and large style variations. To address these issues, we propose FontDiffuser, a diffusion-based image-to-image one-shot font generation method, which innovatively models the font imitation task as a noise-to-denoise paradigm. In our method, we introduce a Multi-scale Content Aggregation (MCA) block, which effectively combines global and local content cues across different scales, leading to enhanced preservation of intricate strokes of complex characters. Moreover, to better manage the large variations in style transfer, we propose a Style Contrastive Refinement (SCR) module, which is a novel structure for style representation learning. It utilizes a style extractor to disentangle styles from images, subsequently supervising the diffusion model via a meticulously designed style contrastive loss. Extensive experiments demonstrate FontDiffuser's state-of-the-art performance in generating diverse characters and styles. It consistently excels on complex characters and large style changes compared to previous methods. The code is available at https://github.com/yeungchenwa/FontDiffuser.
* Accepted to AAAI 2024; Github Page: https://github.com/yeungchenwa/FontDiffuser
Exploring OCR Capabilities of GPT-4V : A Quantitative and In-depth Evaluation
Oct 29, 2023



This paper presents a comprehensive evaluation of the Optical Character Recognition (OCR) capabilities of the recently released GPT-4V(ision), a Large Multimodal Model (LMM). We assess the model's performance across a range of OCR tasks, including scene text recognition, handwritten text recognition, handwritten mathematical expression recognition, table structure recognition, and information extraction from visually-rich document. The evaluation reveals that GPT-4V performs well in recognizing and understanding Latin contents, but struggles with multilingual scenarios and complex tasks. Specifically, it showed limitations when dealing with non-Latin languages and complex tasks such as handwriting mathematical expression recognition, table structure recognition, and end-to-end semantic entity recognition and pair extraction from document image. Based on these observations, we affirm the necessity and continued research value of specialized OCR models. In general, despite its versatility in handling diverse OCR tasks, GPT-4V does not outperform existing state-of-the-art OCR models. How to fully utilize pre-trained general-purpose LMMs such as GPT-4V for OCR downstream tasks remains an open problem. The study offers a critical reference for future research in OCR with LMMs. Evaluation pipeline and results are available at https://github.com/SCUT-DLVCLab/GPT-4V_OCR.