 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePosterVerse: A Full-Workflow Framework for Commercial-Grade Poster Generation with HTML-Based Scalable Typography
Jan 07, 2026Commercial-grade poster design demands the seamless integration of aesthetic appeal with precise, informative content delivery. Current automated poster generation systems face significant limitations, including incomplete design workflows, poor text rendering accuracy, and insufficient flexibility for commercial applications. To address these challenges, we propose PosterVerse, a full-workflow, commercial-grade poster generation method that seamlessly automates the entire design process while delivering high-density and scalable text rendering. PosterVerse replicates professional design through three key stages: (1) blueprint creation using fine-tuned LLMs to extract key design elements from user requirements, (2) graphical background generation via customized diffusion models to create visually appealing imagery, and (3) unified layout-text rendering with an MLLM-powered HTML engine to guarantee high text accuracy and flexible customization. In addition, we introduce PosterDNA, a commercial-grade, HTML-based dataset tailored for training and validating poster design models. To the best of our knowledge, PosterDNA is the first Chinese poster generation dataset to introduce HTML typography files, enabling scalable text rendering and fundamentally solving the challenges of rendering small and high-density text. Experimental results demonstrate that PosterVerse consistently produces commercial-grade posters with appealing visuals, accurate text alignment, and customizable layouts, making it a promising solution for automating commercial poster design. The code and model are available at https://github.com/wuhaer/PosterVerse.
RAPTOR: Real-Time High-Resolution UAV Video Prediction with Efficient Video Attention
Dec 25, 2025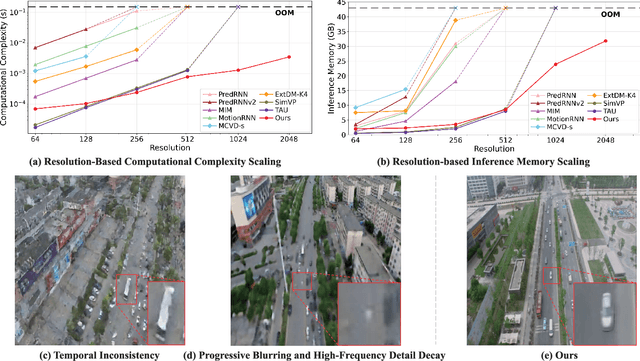



Video prediction is plagued by a fundamental trilemma: achieving high-resolution and perceptual quality typically comes at the cost of real-time speed, hindering its use in latency-critical applications. This challenge is most acute for autonomous UAVs in dense urban environments, where foreseeing events from high-resolution imagery is non-negotiable for safety. Existing methods, reliant on iterative generation (diffusion, autoregressive models) or quadratic-complexity attention, fail to meet these stringent demands on edge hardware. To break this long-standing trade-off, we introduce RAPTOR, a video prediction architecture that achieves real-time, high-resolution performance. RAPTOR's single-pass design avoids the error accumulation and latency of iterative approaches. Its core innovation is Efficient Video Attention (EVA), a novel translator module that factorizes spatiotemporal modeling. Instead of processing flattened spacetime tokens with $O((ST)^2)$ or $O(ST)$ complexity, EVA alternates operations along the spatial (S) and temporal (T) axes. This factorization reduces the time complexity to $O(S + T)$ and memory complexity to $O(max(S, T))$, enabling global context modeling at $512^2$ resolution and beyond, operating directly on dense feature maps with a patch-free design. Complementing this architecture is a 3-stage training curriculum that progressively refines predictions from coarse structure to sharp, temporally coherent details. Experiments show RAPTOR is the first predictor to exceed 30 FPS on a Jetson AGX Orin for $512^2$ video, setting a new state-of-the-art on UAVid, KTH, and a custom high-resolution dataset in PSNR, SSIM, and LPIPS. Critically, RAPTOR boosts the mission success rate in a real-world UAV navigation task by 18/%, paving the way for safer and more anticipatory embodied agents.
MegaHan97K: A Large-Scale Dataset for Mega-Category Chinese Character Recognition with over 97K Categories
Jun 05, 2025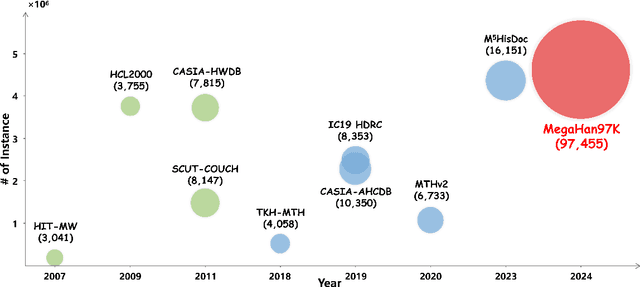



Foundational to the Chinese language and culture, Chinese characters encompass extraordinarily extensive and ever-expanding categories, with the latest Chinese GB18030-2022 standard containing 87,887 categories. The accurate recognition of this vast number of characters, termed mega-category recognition, presents a formidable yet crucial challenge for cultural heritage preservation and digital applications. Despite significant advances in Optical Character Recognition (OCR), mega-category recognition remains unexplored due to the absence of comprehensive datasets, with the largest existing dataset containing merely 16,151 categories. To bridge this critical gap, we introduce MegaHan97K, a mega-category, large-scale dataset covering an unprecedented 97,455 categories of Chinese characters. Our work offers three major contributions: (1) MegaHan97K is the first dataset to fully support the latest GB18030-2022 standard, providing at least six times more categories than existing datasets; (2) It effectively addresses the long-tail distribution problem by providing balanced samples across all categories through its three distinct subsets: handwritten, historical and synthetic subsets; (3) Comprehensive benchmarking experiments reveal new challenges in mega-category scenarios, including increased storage demands, morphologically similar character recognition, and zero-shot learning difficulties, while also unlocking substantial opportunities for future research. To the best of our knowledge, the MetaHan97K is likely the dataset with the largest classes not only in the field of OCR but may also in the broader domain of pattern recognition. The dataset is available at https://github.com/SCUT-DLVCLab/MegaHan97K.
Online Signature Verification based on the Lagrange formulation with 2D and 3D robotic models
Mar 17, 2025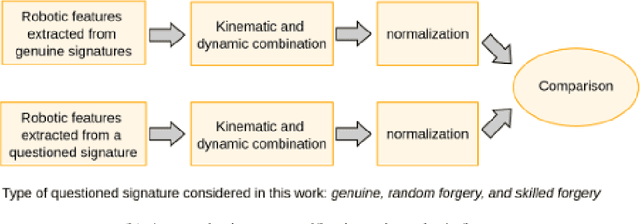
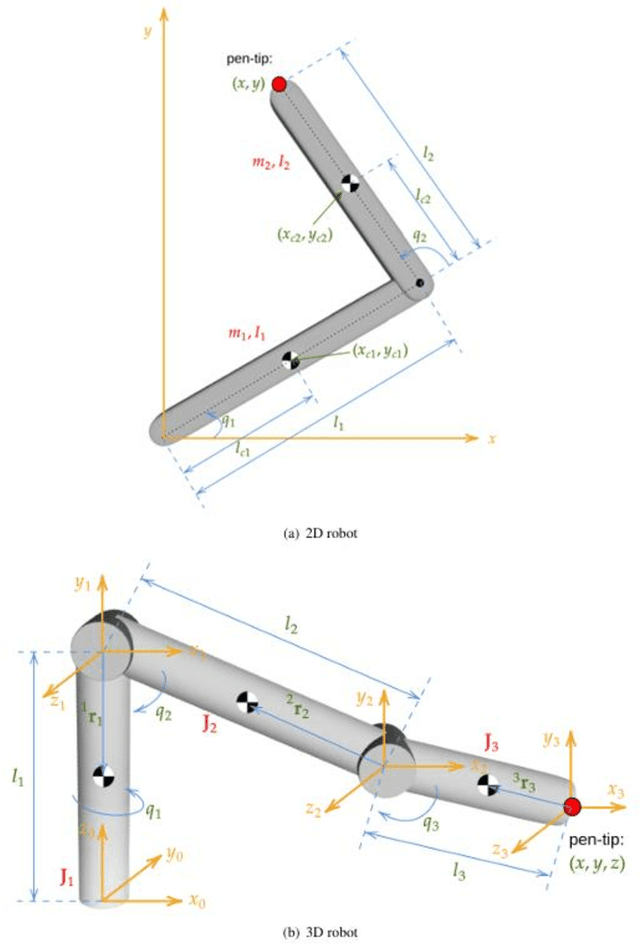
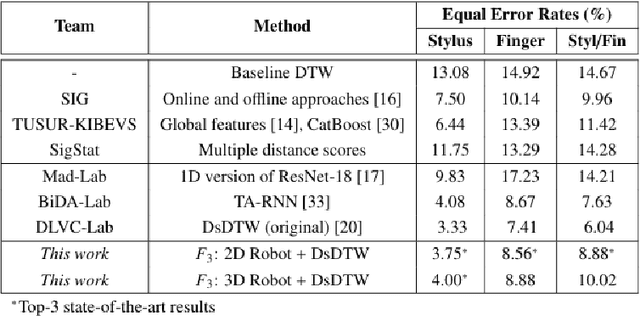
Online Signature Verification commonly relies on function-based features, such as time-sampled horizontal and vertical coordinates, as well as the pressure exerted by the writer, obtained through a digitizer. Although inferring additional information about the writers arm pose, kinematics, and dynamics based on digitizer data can be useful, it constitutes a challenge. In this paper, we tackle this challenge by proposing a new set of features based on the dynamics of online signatures. These new features are inferred through a Lagrangian formulation, obtaining the sequences of generalized coordinates and torques for 2D and 3D robotic arm models. By combining kinematic and dynamic robotic features, our results demonstrate their significant effectiveness for online automatic signature verification and achieving state-of-the-art results when integrated into deep learning models.
Privacy-Preserving Biometric Verification with Handwritten Random Digit String
Mar 17, 2025Handwriting verification has stood as a steadfast identity authentication method for decades. However, this technique risks potential privacy breaches due to the inclusion of personal information in handwritten biometrics such as signatures. To address this concern, we propose using the Random Digit String (RDS) for privacy-preserving handwriting verification. This approach allows users to authenticate themselves by writing an arbitrary digit sequence, effectively ensuring privacy protection. To evaluate the effectiveness of RDS, we construct a new HRDS4BV dataset composed of online naturally handwritten RDS. Unlike conventional handwriting, RDS encompasses unconstrained and variable content, posing significant challenges for modeling consistent personal writing style. To surmount this, we propose the Pattern Attentive VErification Network (PAVENet), along with a Discriminative Pattern Mining (DPM) module. DPM adaptively enhances the recognition of consistent and discriminative writing patterns, thus refining handwriting style representation. Through comprehensive evaluations, we scrutinize the applicability of online RDS verification and showcase a pronounced outperformance of our model over existing methods. Furthermore, we discover a noteworthy forgery phenomenon that deviates from prior findings and discuss its positive impact in countering malicious impostor attacks. Substantially, our work underscores the feasibility of privacy-preserving biometric verification and propels the prospects of its broader acceptance and application.
Smaller But Better: Unifying Layout Generation with Smaller Large Language Models
Feb 19, 2025We propose LGGPT, an LLM-based model tailored for unified layout generation. First, we propose Arbitrary Layout Instruction (ALI) and Universal Layout Response (ULR) as the uniform I/O template. ALI accommodates arbitrary layout generation task inputs across multiple layout domains, enabling LGGPT to unify both task-generic and domain-generic layout generation hitherto unexplored. Collectively, ALI and ULR boast a succinct structure that forgoes superfluous tokens typically found in existing HTML-based formats, facilitating efficient instruction tuning and boosting unified generation performance. In addition, we propose an Interval Quantization Encoding (IQE) strategy that compresses ALI into a more condensed structure. IQE precisely preserves valid layout clues while eliminating the less informative placeholders, facilitating LGGPT to capture complex and variable layout generation conditions during the unified training process. Experimental results demonstrate that LGGPT achieves superior or on par performance compared to existing methods. Notably, LGGPT strikes a prominent balance between proficiency and efficiency with a compact 1.5B parameter LLM, which beats prior 7B or 175B models even in the most extensive and challenging unified scenario. Furthermore, we underscore the necessity of employing LLMs for unified layout generation and suggest that 1.5B could be an optimal parameter size by comparing LLMs of varying scales. Code is available at https://github.com/NiceRingNode/LGGPT.
Online Writer Retrieval with Chinese Handwritten Phrases: A Synergistic Temporal-Frequency Representation Learning Approach
Dec 16, 2024



Currently, the prevalence of online handwriting has spurred a critical need for effective retrieval systems to accurately search relevant handwriting instances from specific writers, known as online writer retrieval. Despite the growing demand, this field suffers from a scarcity of well-established methodologies and public large-scale datasets. This paper tackles these challenges with a focus on Chinese handwritten phrases. First, we propose DOLPHIN, a novel retrieval model designed to enhance handwriting representations through synergistic temporal-frequency analysis. For frequency feature learning, we propose the HFGA block, which performs gated cross-attention between the vanilla temporal handwriting sequence and its high-frequency sub-bands to amplify salient writing details. For temporal feature learning, we propose the CAIR block, tailored to promote channel interaction and reduce channel redundancy. Second, to address data deficit, we introduce OLIWER, a large-scale online writer retrieval dataset encompassing over 670,000 Chinese handwritten phrases from 1,731 individuals. Through extensive evaluations, we demonstrate the superior performance of DOLPHIN over existing methods. In addition, we explore cross-domain writer retrieval and reveal the pivotal role of increasing feature alignment in bridging the distributional gap between different handwriting data. Our findings emphasize the significance of point sampling frequency and pressure features in improving handwriting representation quality and retrieval performance. Code and dataset are available at https://github.com/SCUT-DLVCLab/DOLPHIN.
TongGu: Mastering Classical Chinese Understanding with Knowledge-Grounded Large Language Models
Jul 04, 2024Classical Chinese is a gateway to the rich heritage and wisdom of ancient China, yet its complexities pose formidable comprehension barriers for most modern people without specialized knowledge. While Large Language Models (LLMs) have shown remarkable capabilities in Natural Language Processing (NLP), they struggle with Classical Chinese Understanding (CCU), especially in data-demanding and knowledge-intensive tasks. In response to this dilemma, we propose \textbf{TongGu} (mean understanding ancient and modern), the first CCU-specific LLM, underpinned by three core contributions. First, we construct a two-stage instruction-tuning dataset ACCN-INS derived from rich classical Chinese corpora, aiming to unlock the full CCU potential of LLMs. Second, we propose Redundancy-Aware Tuning (RAT) to prevent catastrophic forgetting, enabling TongGu to acquire new capabilities while preserving its foundational knowledge. Third, we present a CCU Retrieval-Augmented Generation (CCU-RAG) technique to reduce hallucinations based on knowledge-grounding. Extensive experiments across 24 diverse CCU tasks validate TongGu's superior ability, underscoring the effectiveness of RAT and CCU-RAG. The model and dataset will be public available.
DocRes: A Generalist Model Toward Unifying Document Image Restoration Tasks
May 07, 2024



Document image restoration is a crucial aspect of Document AI systems, as the quality of document images significantly influences the overall performance. Prevailing methods address distinct restoration tasks independently, leading to intricate systems and the incapability to harness the potential synergies of multi-task learning. To overcome this challenge, we propose DocRes, a generalist model that unifies five document image restoration tasks including dewarping, deshadowing, appearance enhancement, deblurring, and binarization. To instruct DocRes to perform various restoration tasks, we propose a novel visual prompt approach called Dynamic Task-Specific Prompt (DTSPrompt). The DTSPrompt for different tasks comprises distinct prior features, which are additional characteristics extracted from the input image. Beyond its role as a cue for task-specific execution, DTSPrompt can also serve as supplementary information to enhance the model's performance. Moreover, DTSPrompt is more flexible than prior visual prompt approaches as it can be seamlessly applied and adapted to inputs with high and variable resolutions. Experimental results demonstrate that DocRes achieves competitive or superior performance compared to existing state-of-the-art task-specific models. This underscores the potential of DocRes across a broader spectrum of document image restoration tasks. The source code is publicly available at https://github.com/ZZZHANG-jx/DocRes
HierCode: A Lightweight Hierarchical Codebook for Zero-shot Chinese Text Recognition
Mar 20, 2024

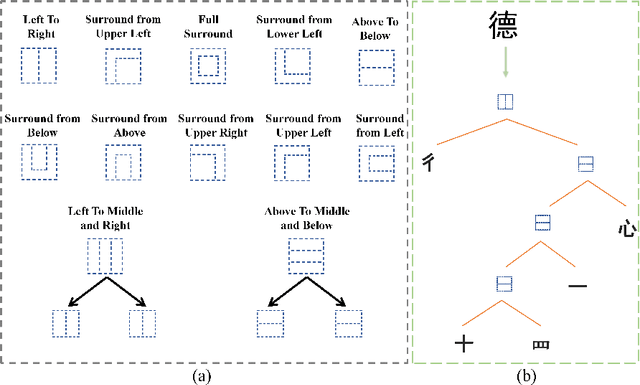

Text recognition, especially for complex scripts like Chinese, faces unique challenges due to its intricate character structures and vast vocabulary. Traditional one-hot encoding methods struggle with the representation of hierarchical radicals, recognition of Out-Of-Vocabulary (OOV) characters, and on-device deployment due to their computational intensity. To address these challenges, we propose HierCode, a novel and lightweight codebook that exploits the innate hierarchical nature of Chinese characters. HierCode employs a multi-hot encoding strategy, leveraging hierarchical binary tree encoding and prototype learning to create distinctive, informative representations for each character. This approach not only facilitates zero-shot recognition of OOV characters by utilizing shared radicals and structures but also excels in line-level recognition tasks by computing similarity with visual features, a notable advantage over existing methods. Extensive experiments across diverse benchmarks, including handwritten, scene, document, web, and ancient text, have showcased HierCode's superiority for both conventional and zero-shot Chinese character or text recognition, exhibiting state-of-the-art performance with significantly fewer parameters and fast inference speed.