 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOCR-Reasoning Benchmark: Unveiling the True Capabilities of MLLMs in Complex Text-Rich Image Reasoning
May 22, 2025Recent advancements in multimodal slow-thinking systems have demonstrated remarkable performance across diverse visual reasoning tasks. However, their capabilities in text-rich image reasoning tasks remain understudied due to the lack of a systematic benchmark. To address this gap, we propose OCR-Reasoning, a comprehensive benchmark designed to systematically assess Multimodal Large Language Models on text-rich image reasoning tasks. The benchmark comprises 1,069 human-annotated examples spanning 6 core reasoning abilities and 18 practical reasoning tasks in text-rich visual scenarios. Furthermore, unlike other text-rich image understanding benchmarks that only annotate the final answers, OCR-Reasoning also annotates the reasoning process simultaneously. With the annotated reasoning process and the final answers, OCR-Reasoning evaluates not only the final answers generated by models but also their reasoning processes, enabling a holistic analysis of their problem-solving abilities. Leveraging this benchmark, we conducted a comprehensive evaluation of state-of-the-art MLLMs. Our results demonstrate the limitations of existing methodologies. Notably, even state-of-the-art MLLMs exhibit substantial difficulties, with none achieving accuracy surpassing 50\% across OCR-Reasoning, indicating that the challenges of text-rich image reasoning are an urgent issue to be addressed. The benchmark and evaluation scripts are available at https://github.com/SCUT-DLVCLab/OCR-Reasoning.
DocKylin: A Large Multimodal Model for Visual Document Understanding with Efficient Visual Slimming
Jun 27, 2024



Current multimodal large language models (MLLMs) face significant challenges in visual document understanding (VDU) tasks due to the high resolution, dense text, and complex layouts typical of document images. These characteristics demand a high level of detail perception ability from MLLMs. While increasing input resolution improves detail perception, it also leads to longer sequences of visual tokens, increasing computational costs and straining the models' ability to handle long contexts. To address these challenges, we introduce DocKylin, a document-centric MLLM that performs visual content slimming at both the pixel and token levels, thereby reducing token sequence length in VDU scenarios. DocKylin utilizes an Adaptive Pixel Slimming (APS) preprocessing module to perform pixel-level slimming, increasing the proportion of informative pixels. Moreover, DocKylin incorporates a novel Dynamic Token Slimming (DTS) module to conduct token-level slimming, filtering essential tokens and removing others to create a compressed, adaptive visual sequence. Experiments demonstrate DocKylin's promising performance across various VDU benchmarks. Notably, both the proposed APS and DTS are parameter-free, facilitating easy integration into existing MLLMs, and our experiments indicate their potential for broader applications.
M$^{6}$Doc: A Large-Scale Multi-Format, Multi-Type, Multi-Layout, Multi-Language, Multi-Annotation Category Dataset for Modern Document Layout Analysis
May 21, 2023
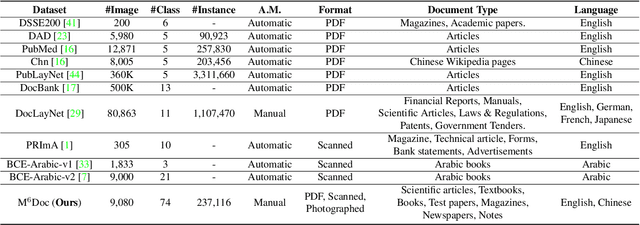
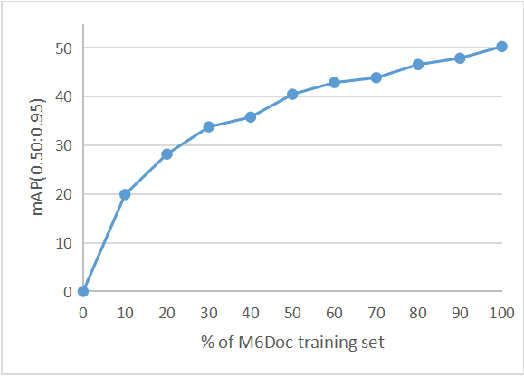
Document layout analysis is a crucial prerequisite for document understanding, including document retrieval and conversion. Most public datasets currently contain only PDF documents and lack realistic documents. Models trained on these datasets may not generalize well to real-world scenarios. Therefore, this paper introduces a large and diverse document layout analysis dataset called $M^{6}Doc$. The $M^6$ designation represents six properties: (1) Multi-Format (including scanned, photographed, and PDF documents); (2) Multi-Type (such as scientific articles, textbooks, books, test papers, magazines, newspapers, and notes); (3) Multi-Layout (rectangular, Manhattan, non-Manhattan, and multi-column Manhattan); (4) Multi-Language (Chinese and English); (5) Multi-Annotation Category (74 types of annotation labels with 237,116 annotation instances in 9,080 manually annotated pages); and (6) Modern documents. Additionally, we propose a transformer-based document layout analysis method called TransDLANet, which leverages an adaptive element matching mechanism that enables query embedding to better match ground truth to improve recall, and constructs a segmentation branch for more precise document image instance segmentation. We conduct a comprehensive evaluation of $M^{6}Doc$ with various layout analysis methods and demonstrate its effectiveness. TransDLANet achieves state-of-the-art performance on $M^{6}Doc$ with 64.5% mAP. The $M^{6}Doc$ dataset will be available at https://github.com/HCIILAB/M6Doc.
Improving Table Structure Recognition with Visual-Alignment Sequential Coordinate Modeling
Mar 20, 2023


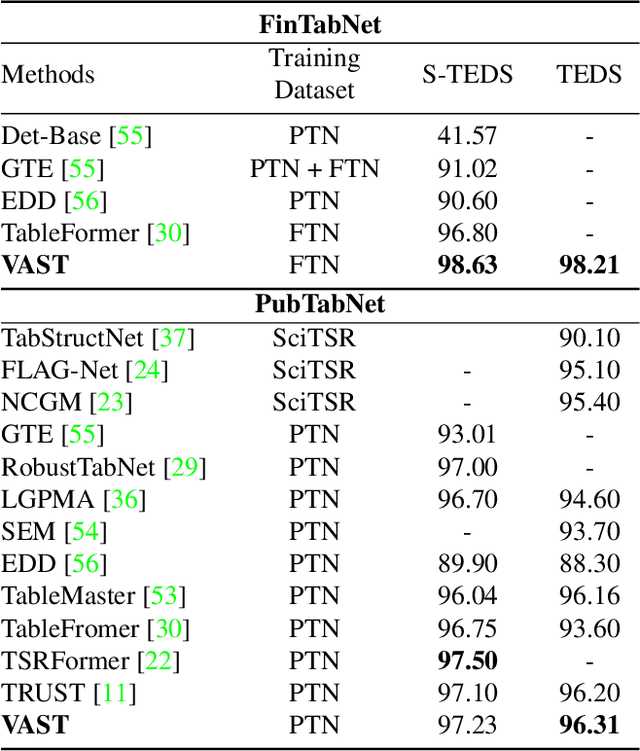
Table structure recognition aims to extract the logical and physical structure of unstructured table images into a machine-readable format. The latest end-to-end image-to-text approaches simultaneously predict the two structures by two decoders, where the prediction of the physical structure (the bounding boxes of the cells) is based on the representation of the logical structure. However, the previous methods struggle with imprecise bounding boxes as the logical representation lacks local visual information. To address this issue, we propose an end-to-end sequential modeling framework for table structure recognition called VAST. It contains a novel coordinate sequence decoder triggered by the representation of the non-empty cell from the logical structure decoder. In the coordinate sequence decoder, we model the bounding box coordinates as a language sequence, where the left, top, right and bottom coordinates are decoded sequentially to leverage the inter-coordinate dependency. Furthermore, we propose an auxiliary visual-alignment loss to enforce the logical representation of the non-empty cells to contain more local visual details, which helps produce better cell bounding boxes. Extensive experiments demonstrate that our proposed method can achieve state-of-the-art results in both logical and physical structure recognition. The ablation study also validates that the proposed coordinate sequence decoder and the visual-alignment loss are the keys to the success of our method.
Aggregation Cross-Entropy for Sequence Recognition
Apr 18, 2019
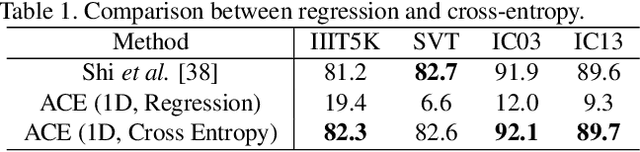

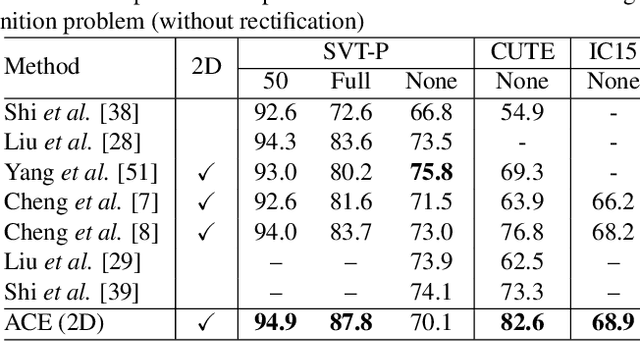
In this paper, we propose a novel method, aggregation cross-entropy (ACE), for sequence recognition from a brand new perspective. The ACE loss function exhibits competitive performance to CTC and the attention mechanism, with much quicker implementation (as it involves only four fundamental formulas), faster inference\back-propagation (approximately O(1) in parallel), less storage requirement (no parameter and negligible runtime memory), and convenient employment (by replacing CTC with ACE). Furthermore, the proposed ACE loss function exhibits two noteworthy properties: (1) it can be directly applied for 2D prediction by flattening the 2D prediction into 1D prediction as the input and (2) it requires only characters and their numbers in the sequence annotation for supervision, which allows it to advance beyond sequence recognition, e.g., counting problem. The code is publicly available at https://github.com/summerlvsong/Aggregation-Cross-Entropy.
Tightness-aware Evaluation Protocol for Scene Text Detection
Mar 27, 2019
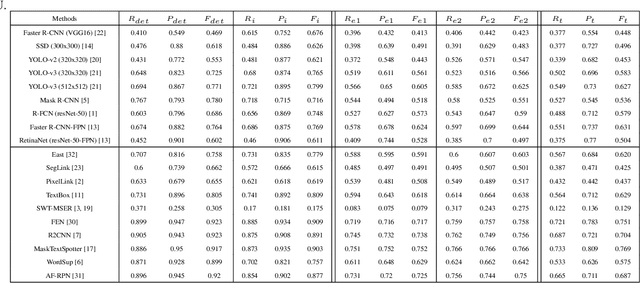

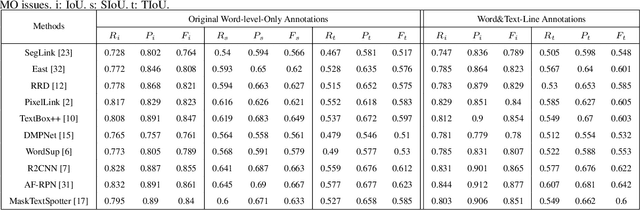
Evaluation protocols play key role in the developmental progress of text detection methods. There are strict requirements to ensure that the evaluation methods are fair, objective and reasonable. However, existing metrics exhibit some obvious drawbacks: 1) They are not goal-oriented; 2) they cannot recognize the tightness of detection methods; 3) existing one-to-many and many-to-one solutions involve inherent loopholes and deficiencies. Therefore, this paper proposes a novel evaluation protocol called Tightness-aware Intersect-over-Union (TIoU) metric that could quantify completeness of ground truth, compactness of detection, and tightness of matching degree. Specifically, instead of merely using the IoU value, two common detection behaviors are properly considered; meanwhile, directly using the score of TIoU to recognize the tightness. In addition, we further propose a straightforward method to address the annotation granularity issue, which can fairly evaluate word and text-line detections simultaneously. By adopting the detection results from published methods and general object detection frameworks, comprehensive experiments on ICDAR 2013 and ICDAR 2015 datasets are conducted to compare recent metrics and the proposed TIoU metric. The comparison demonstrated some promising new prospects, e.g., determining the methods and frameworks for which the detection is tighter and more beneficial to recognize. Our method is extremely simple; however, the novelty is none other than the proposed metric can utilize simplest but reasonable improvements to lead to many interesting and insightful prospects and solving most the issues of the previous metrics. The code is publicly available at https://github.com/Yuliang-Liu/TIoU-metric .
DeRPN: Taking a further step toward more general object detection
Nov 16, 2018



Most current detection methods have adopted anchor boxes as regression references. However, the detection performance is sensitive to the setting of the anchor boxes. A proper setting of anchor boxes may vary significantly across different datasets, which severely limits the universality of the detectors. To improve the adaptivity of the detectors, in this paper, we present a novel dimension-decomposition region proposal network (DeRPN) that can perfectly displace the traditional Region Proposal Network (RPN). DeRPN utilizes an anchor string mechanism to independently match object widths and heights, which is conducive to treating variant object shapes. In addition, a novel scale-sensitive loss is designed to address the imbalanced loss computations of different scaled objects, which can avoid the small objects being overwhelmed by larger ones. Comprehensive experiments conducted on both general object detection datasets (Pascal VOC 2007, 2012 and MS COCO) and scene text detection datasets (ICDAR 2013 and COCO-Text) all prove that our DeRPN can significantly outperform RPN. It is worth mentioning that the proposed DeRPN can be employed directly on different models, tasks, and datasets without any modifications of hyperparameters or specialized optimization, which further demonstrates its adaptivity. The code will be released at https://github.com/HCIILAB/DeRPN.
Learning Spatial-Semantic Context with Fully Convolutional Recurrent Network for Online Handwritten Chinese Text Recognition
May 25, 2017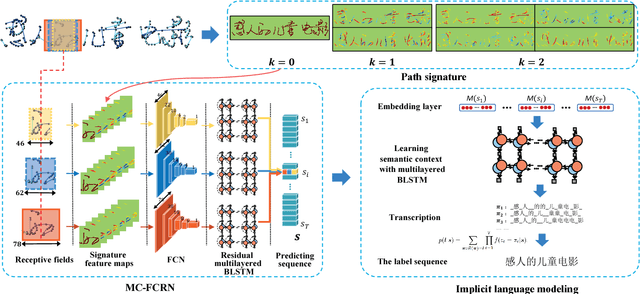
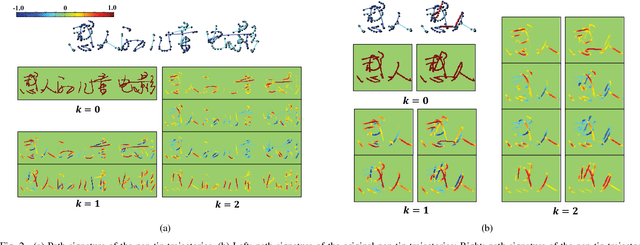
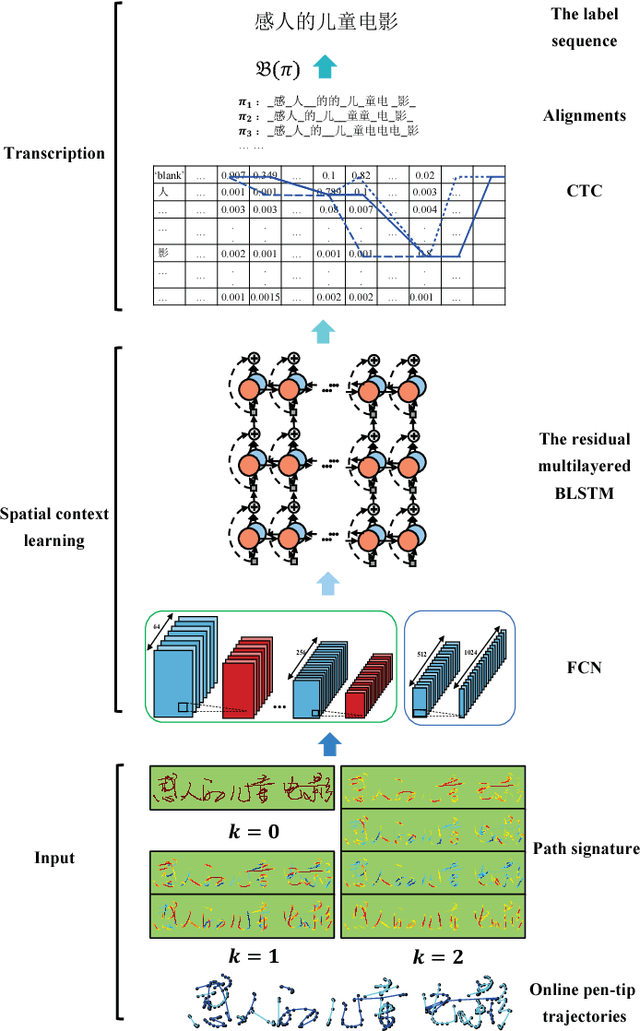
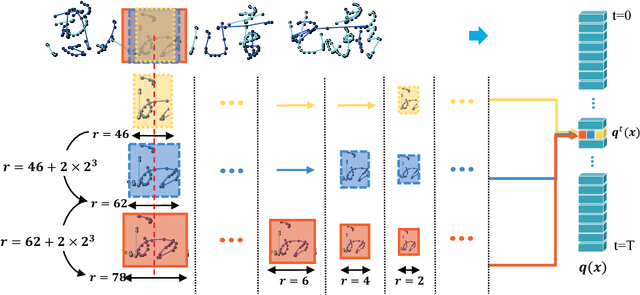
Online handwritten Chinese text recognition (OHCTR) is a challenging problem as it involves a large-scale character set, ambiguous segmentation, and variable-length input sequences. In this paper, we exploit the outstanding capability of path signature to translate online pen-tip trajectories into informative signature feature maps using a sliding window-based method, successfully capturing the analytic and geometric properties of pen strokes with strong local invariance and robustness. A multi-spatial-context fully convolutional recurrent network (MCFCRN) is proposed to exploit the multiple spatial contexts from the signature feature maps and generate a prediction sequence while completely avoiding the difficult segmentation problem. Furthermore, an implicit language model is developed to make predictions based on semantic context within a predicting feature sequence, providing a new perspective for incorporating lexicon constraints and prior knowledge about a certain language in the recognition procedure. Experiments on two standard benchmarks, Dataset-CASIA and Dataset-ICDAR, yielded outstanding results, with correct rates of 97.10% and 97.15%, respectively, which are significantly better than the best result reported thus far in the literature.
Fully Convolutional Recurrent Network for Handwritten Chinese Text Recognition
Apr 18, 2016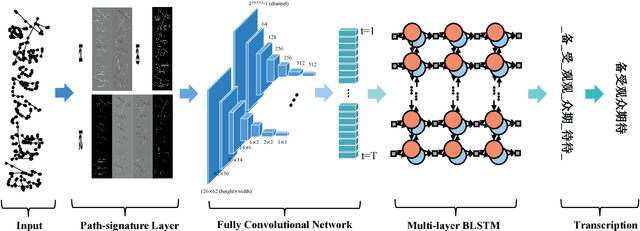
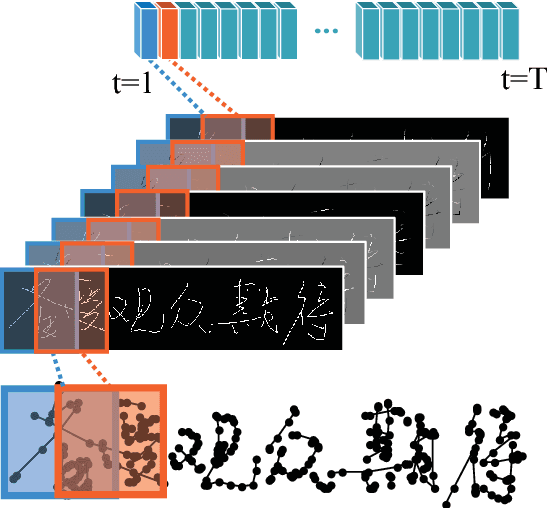
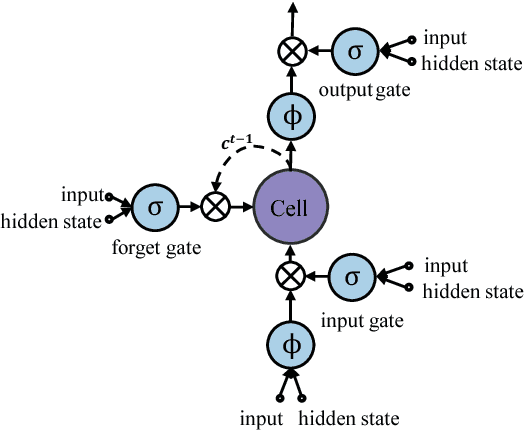

This paper proposes an end-to-end framework, namely fully convolutional recurrent network (FCRN) for handwritten Chinese text recognition (HCTR). Unlike traditional methods that rely heavily on segmentation, our FCRN is trained with online text data directly and learns to associate the pen-tip trajectory with a sequence of characters. FCRN consists of four parts: a path-signature layer to extract signature features from the input pen-tip trajectory, a fully convolutional network to learn informative representation, a sequence modeling layer to make per-frame predictions on the input sequence and a transcription layer to translate the predictions into a label sequence. The FCRN is end-to-end trainable in contrast to conventional methods whose components are separately trained and tuned. We also present a refined beam search method that efficiently integrates the language model to decode the FCRN and significantly improve the recognition results. We evaluate the performance of the proposed method on the test sets from the databases CASIA-OLHWDB and ICDAR 2013 Chinese handwriting recognition competition, and both achieve state-of-the-art performance with correct rates of 96.40% and 95.00%, respectively.
Improved Deep Convolutional Neural Network For Online Handwritten Chinese Character Recognition using Domain-Specific Knowledge
May 28, 2015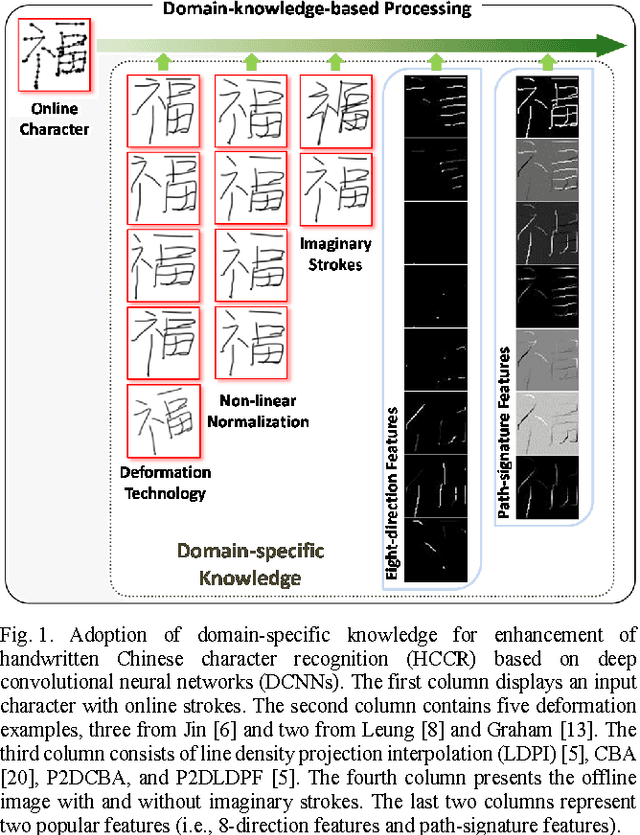
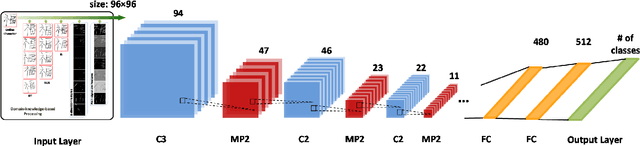
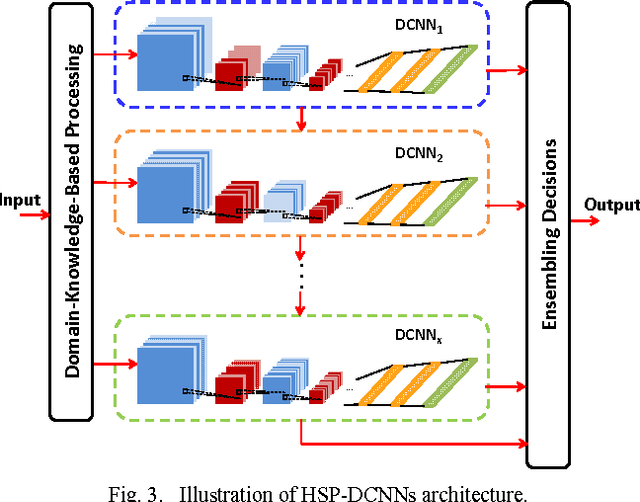
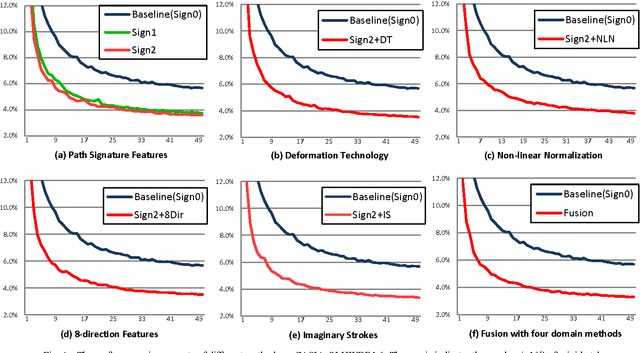
Deep convolutional neural networks (DCNNs) have achieved great success in various computer vision and pattern recognition applications, including those for handwritten Chinese character recognition (HCCR). However, most current DCNN-based HCCR approaches treat the handwritten sample simply as an image bitmap, ignoring some vital domain-specific information that may be useful but that cannot be learnt by traditional networks. In this paper, we propose an enhancement of the DCNN approach to online HCCR by incorporating a variety of domain-specific knowledge, including deformation, non-linear normalization, imaginary strokes, path signature, and 8-directional features. Our contribution is twofold. First, these domain-specific technologies are investigated and integrated with a DCNN to form a composite network to achieve improved performance. Second, the resulting DCNNs with diversity in their domain knowledge are combined using a hybrid serial-parallel (HSP) strategy. Consequently, we achieve a promising accuracy of 97.20% and 96.87% on CASIA-OLHWDB1.0 and CASIA-OLHWDB1.1, respectively, outperforming the best results previously reported in the literature.