 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDocKylin: A Large Multimodal Model for Visual Document Understanding with Efficient Visual Slimming
Jun 27, 2024



Current multimodal large language models (MLLMs) face significant challenges in visual document understanding (VDU) tasks due to the high resolution, dense text, and complex layouts typical of document images. These characteristics demand a high level of detail perception ability from MLLMs. While increasing input resolution improves detail perception, it also leads to longer sequences of visual tokens, increasing computational costs and straining the models' ability to handle long contexts. To address these challenges, we introduce DocKylin, a document-centric MLLM that performs visual content slimming at both the pixel and token levels, thereby reducing token sequence length in VDU scenarios. DocKylin utilizes an Adaptive Pixel Slimming (APS) preprocessing module to perform pixel-level slimming, increasing the proportion of informative pixels. Moreover, DocKylin incorporates a novel Dynamic Token Slimming (DTS) module to conduct token-level slimming, filtering essential tokens and removing others to create a compressed, adaptive visual sequence. Experiments demonstrate DocKylin's promising performance across various VDU benchmarks. Notably, both the proposed APS and DTS are parameter-free, facilitating easy integration into existing MLLMs, and our experiments indicate their potential for broader applications.
Hierarchical Side-Tuning for Vision Transformers
Oct 10, 2023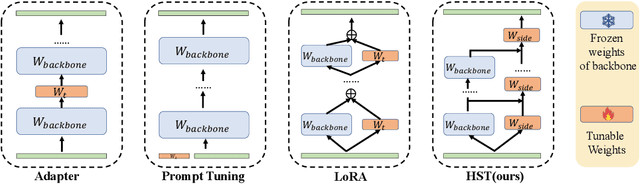
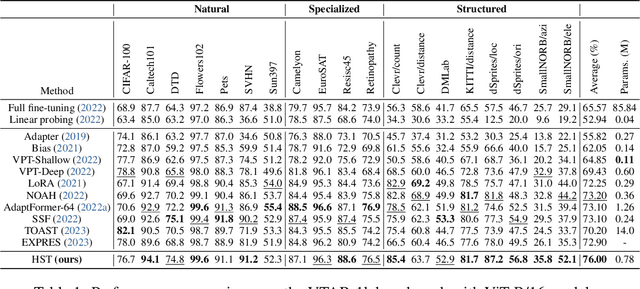
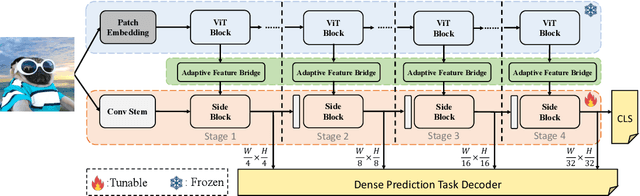
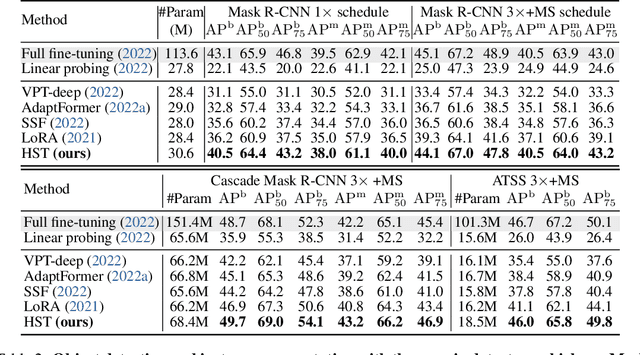
Fine-tuning pre-trained Vision Transformers (ViT) has consistently demonstrated promising performance in the realm of visual recognition. However, adapting large pre-trained models to various tasks poses a significant challenge. This challenge arises from the need for each model to undergo an independent and comprehensive fine-tuning process, leading to substantial computational and memory demands. While recent advancements in Parameter-efficient Transfer Learning (PETL) have demonstrated their ability to achieve superior performance compared to full fine-tuning with a smaller subset of parameter updates, they tend to overlook dense prediction tasks such as object detection and segmentation. In this paper, we introduce Hierarchical Side-Tuning (HST), a novel PETL approach that enables ViT transfer to various downstream tasks effectively. Diverging from existing methods that exclusively fine-tune parameters within input spaces or certain modules connected to the backbone, we tune a lightweight and hierarchical side network (HSN) that leverages intermediate activations extracted from the backbone and generates multi-scale features to make predictions. To validate HST, we conducted extensive experiments encompassing diverse visual tasks, including classification, object detection, instance segmentation, and semantic segmentation. Notably, our method achieves state-of-the-art average Top-1 accuracy of 76.0% on VTAB-1k, all while fine-tuning a mere 0.78M parameters. When applied to object detection tasks on COCO testdev benchmark, HST even surpasses full fine-tuning and obtains better performance with 49.7 box AP and 43.2 mask AP using Cascade Mask R-CNN.
High Accuracy Visible Light Positioning Based on Multi-target Tracking Algorithm
Mar 09, 2021
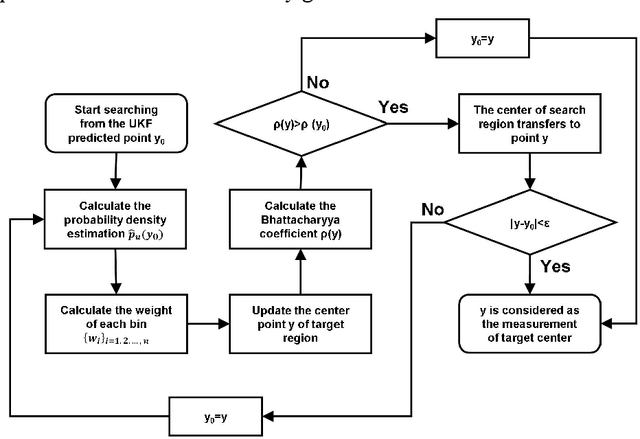

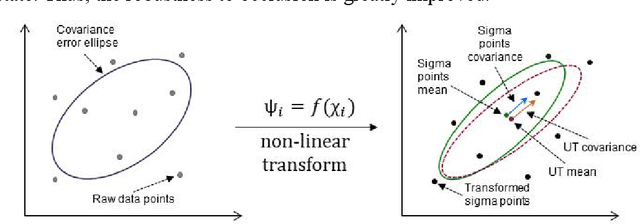
In this paper, we propose a multi-target image tracking algorithm based on continuously apative mean-shift (Cam-shift) and unscented Kalman filter. We improved the single-lamp tracking algorithm proposed in our previous work to multi-target tracking, and achieved better robustness in the case of occlusion, the real-time performance to complete one positioning and relatively high accuracy by dynamically adjusting the weights of the multi-target motion states. Our previous algorithm is limited to the analysis of tracking error. In this paper, the results of the tracking algorithm are evaluated with the tracking error we defined. Then combined with the double-lamp positioning algorithm, the real position of the terminal is calculated and evaluated with the positioning error we defined. Experiments show that the defined tracking error is 0.61cm and the defined positioning error for 3-D positioning is 3.29cm with the average processing time of 91.63ms per frame. Even if nearly half of the LED area is occluded, the tracking error remains at 5.25cm. All of this shows that the proposed visible light positioning (VLP) method can track multiple targets for positioning at the same time with good robustness, real-time performance and accuracy. In addition, the definition and analysis of tracking errors and positioning errors indicates the direction for future efforts to reduce errors.