 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVFaith: Do Large Multimodal Models Really Reason on Seen Images Rather than Previous Memories?
Jun 13, 2025Recent extensive works have demonstrated that by introducing long CoT, the capabilities of MLLMs to solve complex problems can be effectively enhanced. However, the reasons for the effectiveness of such paradigms remain unclear. It is challenging to analysis with quantitative results how much the model's specific extraction of visual cues and its subsequent so-called reasoning during inference process contribute to the performance improvements. Therefore, evaluating the faithfulness of MLLMs' reasoning to visual information is crucial. To address this issue, we first present a cue-driven automatic and controllable editing pipeline with the help of GPT-Image-1. It enables the automatic and precise editing of specific visual cues based on the instruction. Furthermore, we introduce VFaith-Bench, the first benchmark to evaluate MLLMs' visual reasoning capabilities and analyze the source of such capabilities with an emphasis on the visual faithfulness. Using the designed pipeline, we constructed comparative question-answer pairs by altering the visual cues in images that are crucial for solving the original reasoning problem, thereby changing the question's answer. By testing similar questions with images that have different details, the average accuracy reflects the model's visual reasoning ability, while the difference in accuracy before and after editing the test set images effectively reveals the relationship between the model's reasoning ability and visual perception. We further designed specific metrics to expose this relationship. VFaith-Bench includes 755 entries divided into five distinct subsets, along with an additional human-labeled perception task. We conducted in-depth testing and analysis of existing mainstream flagship models and prominent open-source model series/reasoning models on VFaith-Bench, further investigating the underlying factors of their reasoning capabilities.
Valley2: Exploring Multimodal Models with Scalable Vision-Language Design
Jan 13, 2025



Recently, vision-language models have made remarkable progress, demonstrating outstanding capabilities in various tasks such as image captioning and video understanding. We introduce Valley2, a novel multimodal large language model designed to enhance performance across all domains and extend the boundaries of practical applications in e-commerce and short video scenarios. Notably, Valley2 achieves state-of-the-art (SOTA) performance on e-commerce benchmarks, surpassing open-source models of similar size by a large margin (79.66 vs. 72.76). Additionally, Valley2 ranks second on the OpenCompass leaderboard among models with fewer than 10B parameters, with an impressive average score of 67.4. The code and model weights are open-sourced at https://github.com/bytedance/Valley.
Rapid and Accurate Diagnosis of Acute Aortic Syndrome using Non-contrast CT: A Large-scale, Retrospective, Multi-center and AI-based Study
Jun 25, 2024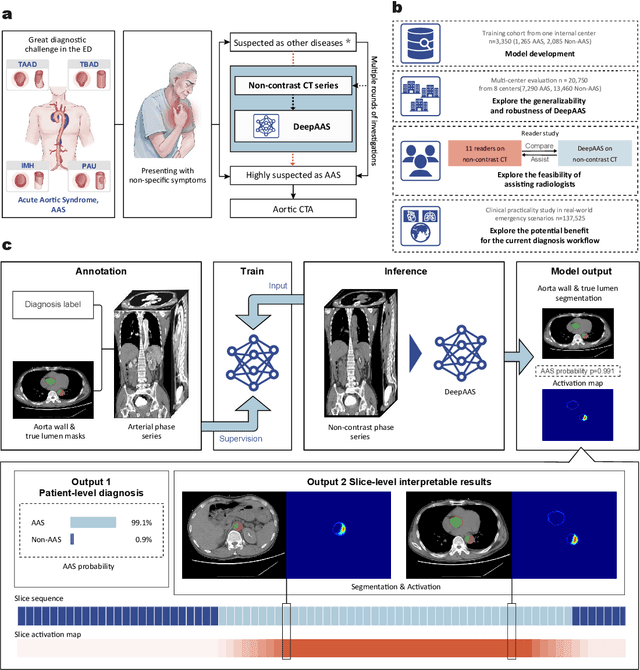
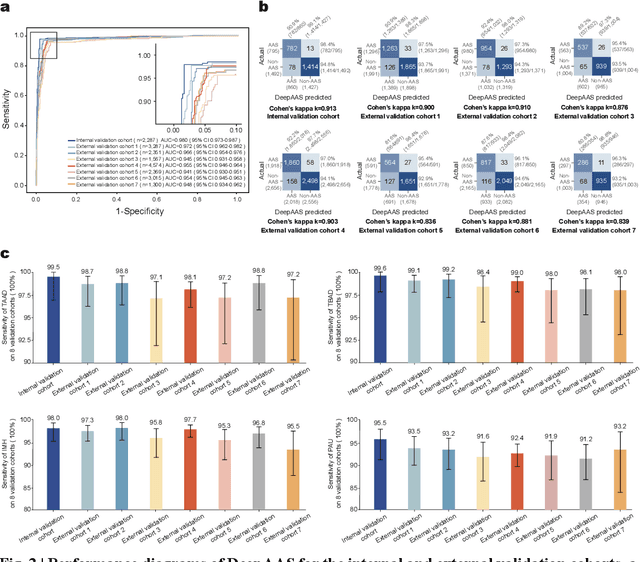
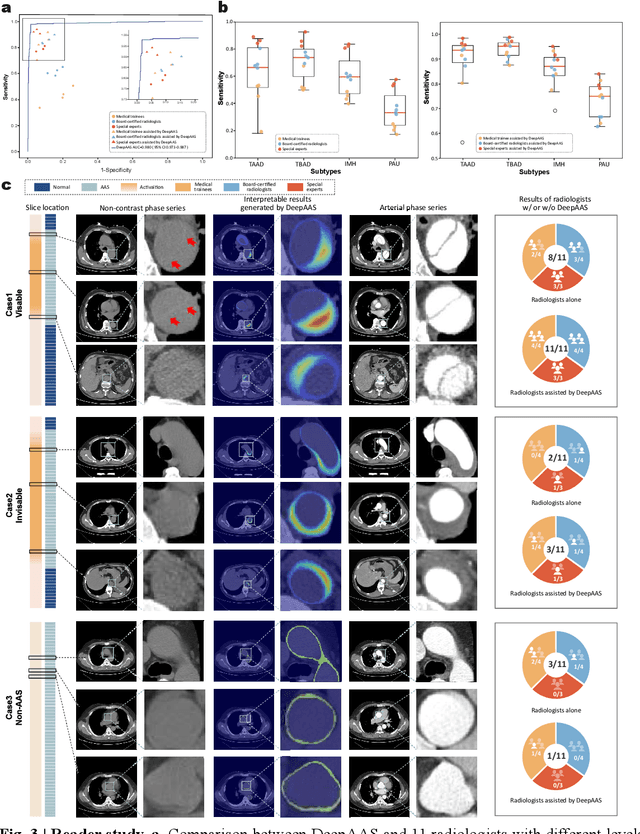
Chest pain symptoms are highly prevalent in emergency departments (EDs), where acute aortic syndrome (AAS) is a catastrophic cardiovascular emergency with a high fatality rate, especially when timely and accurate treatment is not administered. However, current triage practices in the ED can cause up to approximately half of patients with AAS to have an initially missed diagnosis or be misdiagnosed as having other acute chest pain conditions. Subsequently, these AAS patients will undergo clinically inaccurate or suboptimal differential diagnosis. Fortunately, even under these suboptimal protocols, nearly all these patients underwent non-contrast CT covering the aorta anatomy at the early stage of differential diagnosis. In this study, we developed an artificial intelligence model (DeepAAS) using non-contrast CT, which is highly accurate for identifying AAS and provides interpretable results to assist in clinical decision-making. Performance was assessed in two major phases: a multi-center retrospective study (n = 20,750) and an exploration in real-world emergency scenarios (n = 137,525). In the multi-center cohort, DeepAAS achieved a mean area under the receiver operating characteristic curve of 0.958 (95% CI 0.950-0.967). In the real-world cohort, DeepAAS detected 109 AAS patients with misguided initial suspicion, achieving 92.6% (95% CI 76.2%-97.5%) in mean sensitivity and 99.2% (95% CI 99.1%-99.3%) in mean specificity. Our AI model performed well on non-contrast CT at all applicable early stages of differential diagnosis workflows, effectively reduced the overall missed diagnosis and misdiagnosis rate from 48.8% to 4.8% and shortened the diagnosis time for patients with misguided initial suspicion from an average of 681.8 (74-11,820) mins to 68.5 (23-195) mins. DeepAAS could effectively fill the gap in the current clinical workflow without requiring additional tests.
BeautifulPrompt: Towards Automatic Prompt Engineering for Text-to-Image Synthesis
Nov 12, 2023Recently, diffusion-based deep generative models (e.g., Stable Diffusion) have shown impressive results in text-to-image synthesis. However, current text-to-image models often require multiple passes of prompt engineering by humans in order to produce satisfactory results for real-world applications. We propose BeautifulPrompt, a deep generative model to produce high-quality prompts from very simple raw descriptions, which enables diffusion-based models to generate more beautiful images. In our work, we first fine-tuned the BeautifulPrompt model over low-quality and high-quality collecting prompt pairs. Then, to ensure that our generated prompts can generate more beautiful images, we further propose a Reinforcement Learning with Visual AI Feedback technique to fine-tune our model to maximize the reward values of the generated prompts, where the reward values are calculated based on the PickScore and the Aesthetic Scores. Our results demonstrate that learning from visual AI feedback promises the potential to improve the quality of generated prompts and images significantly. We further showcase the integration of BeautifulPrompt to a cloud-native AI platform to provide better text-to-image generation service in the cloud.
Hierarchical Side-Tuning for Vision Transformers
Oct 10, 2023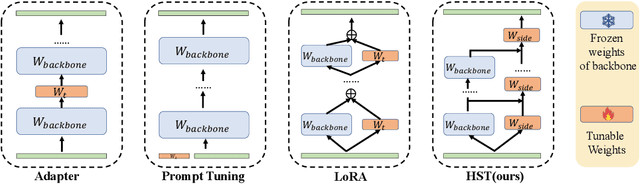
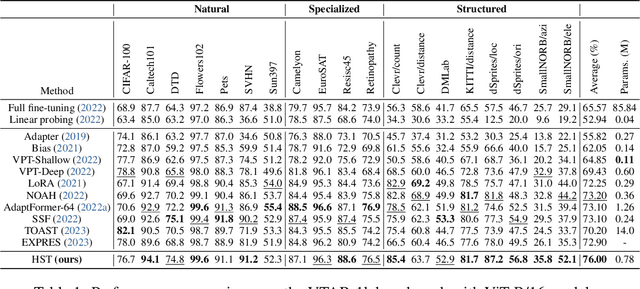
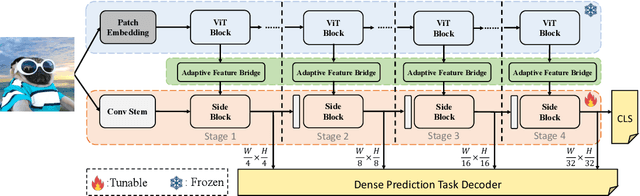
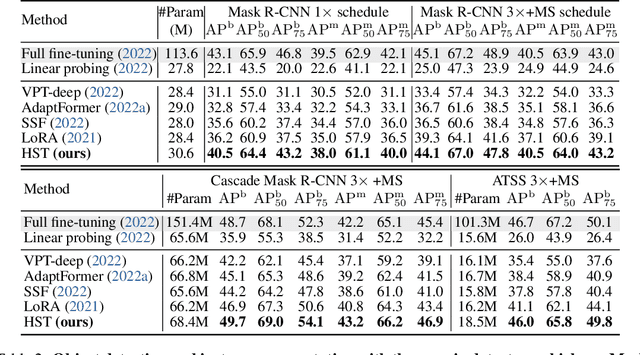
Fine-tuning pre-trained Vision Transformers (ViT) has consistently demonstrated promising performance in the realm of visual recognition. However, adapting large pre-trained models to various tasks poses a significant challenge. This challenge arises from the need for each model to undergo an independent and comprehensive fine-tuning process, leading to substantial computational and memory demands. While recent advancements in Parameter-efficient Transfer Learning (PETL) have demonstrated their ability to achieve superior performance compared to full fine-tuning with a smaller subset of parameter updates, they tend to overlook dense prediction tasks such as object detection and segmentation. In this paper, we introduce Hierarchical Side-Tuning (HST), a novel PETL approach that enables ViT transfer to various downstream tasks effectively. Diverging from existing methods that exclusively fine-tune parameters within input spaces or certain modules connected to the backbone, we tune a lightweight and hierarchical side network (HSN) that leverages intermediate activations extracted from the backbone and generates multi-scale features to make predictions. To validate HST, we conducted extensive experiments encompassing diverse visual tasks, including classification, object detection, instance segmentation, and semantic segmentation. Notably, our method achieves state-of-the-art average Top-1 accuracy of 76.0% on VTAB-1k, all while fine-tuning a mere 0.78M parameters. When applied to object detection tasks on COCO testdev benchmark, HST even surpasses full fine-tuning and obtains better performance with 49.7 box AP and 43.2 mask AP using Cascade Mask R-CNN.
EasyPhoto: Your Smart AI Photo Generator
Oct 07, 2023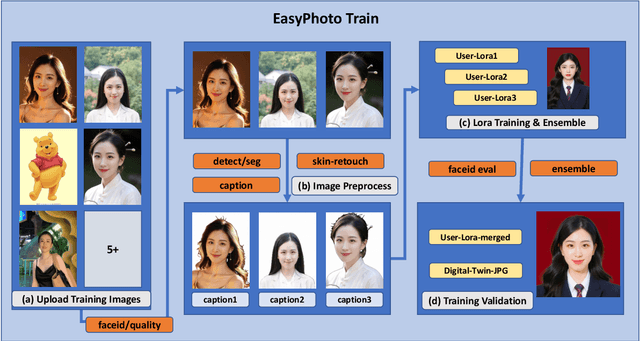
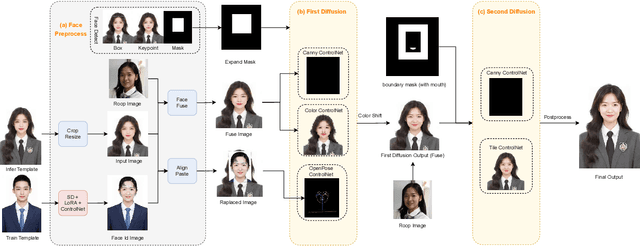
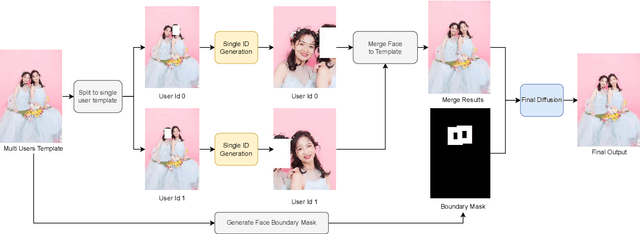

Stable Diffusion web UI (SD-WebUI) is a comprehensive project that provides a browser interface based on Gradio library for Stable Diffusion models. In this paper, We propose a novel WebUI plugin called EasyPhoto, which enables the generation of AI portraits. By training a digital doppelganger of a specific user ID using 5 to 20 relevant images, the finetuned model (according to the trained LoRA model) allows for the generation of AI photos using arbitrary templates. Our current implementation supports the modification of multiple persons and different photo styles. Furthermore, we allow users to generate fantastic template image with the strong SDXL model, enhancing EasyPhoto's capabilities to deliver more diverse and satisfactory results. The source code for EasyPhoto is available at: https://github.com/aigc-apps/sd-webui-EasyPhoto. We also support a webui-free version by using diffusers: https://github.com/aigc-apps/EasyPhoto. We are continuously enhancing our efforts to expand the EasyPhoto pipeline, making it suitable for any identification (not limited to just the face), and we enthusiastically welcome any intriguing ideas or suggestions.
DualToken-ViT: Position-aware Efficient Vision Transformer with Dual Token Fusion
Sep 21, 2023


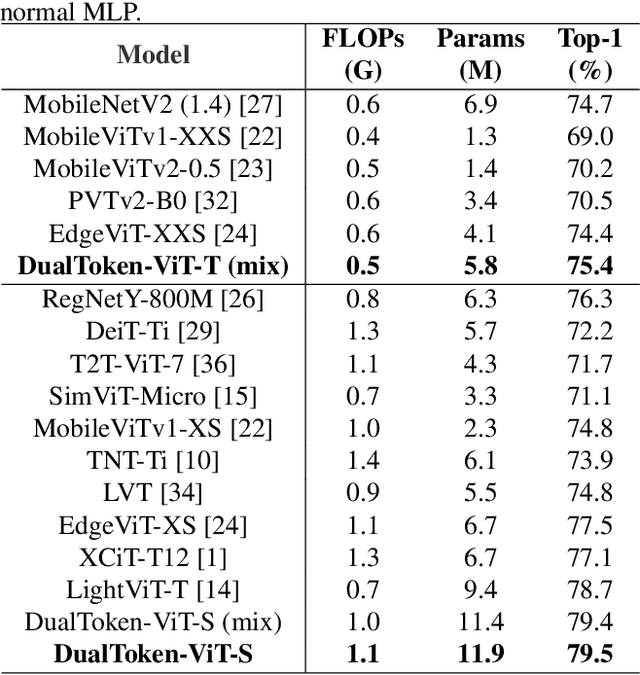
Self-attention-based vision transformers (ViTs) have emerged as a highly competitive architecture in computer vision. Unlike convolutional neural networks (CNNs), ViTs are capable of global information sharing. With the development of various structures of ViTs, ViTs are increasingly advantageous for many vision tasks. However, the quadratic complexity of self-attention renders ViTs computationally intensive, and their lack of inductive biases of locality and translation equivariance demands larger model sizes compared to CNNs to effectively learn visual features. In this paper, we propose a light-weight and efficient vision transformer model called DualToken-ViT that leverages the advantages of CNNs and ViTs. DualToken-ViT effectively fuses the token with local information obtained by convolution-based structure and the token with global information obtained by self-attention-based structure to achieve an efficient attention structure. In addition, we use position-aware global tokens throughout all stages to enrich the global information, which further strengthening the effect of DualToken-ViT. Position-aware global tokens also contain the position information of the image, which makes our model better for vision tasks. We conducted extensive experiments on image classification, object detection and semantic segmentation tasks to demonstrate the effectiveness of DualToken-ViT. On the ImageNet-1K dataset, our models of different scales achieve accuracies of 75.4% and 79.4% with only 0.5G and 1.0G FLOPs, respectively, and our model with 1.0G FLOPs outperforms LightViT-T using global tokens by 0.7%.
FaceChain: A Playground for Identity-Preserving Portrait Generation
Aug 28, 2023



Recent advancement in personalized image generation have unveiled the intriguing capability of pre-trained text-to-image models on learning identity information from a collection of portrait images. However, existing solutions can be vulnerable in producing truthful details, and usually suffer from several defects such as (i) The generated face exhibit its own unique characteristics, \ie facial shape and facial feature positioning may not resemble key characteristics of the input, and (ii) The synthesized face may contain warped, blurred or corrupted regions. In this paper, we present FaceChain, a personalized portrait generation framework that combines a series of customized image-generation model and a rich set of face-related perceptual understanding models (\eg, face detection, deep face embedding extraction, and facial attribute recognition), to tackle aforementioned challenges and to generate truthful personalized portraits, with only a handful of portrait images as input. Concretely, we inject several SOTA face models into the generation procedure, achieving a more efficient label-tagging, data-processing, and model post-processing compared to previous solutions, such as DreamBooth ~\cite{ruiz2023dreambooth} , InstantBooth ~\cite{shi2023instantbooth} , or other LoRA-only approaches ~\cite{hu2021lora} . Through the development of FaceChain, we have identified several potential directions to accelerate development of Face/Human-Centric AIGC research and application. We have designed FaceChain as a framework comprised of pluggable components that can be easily adjusted to accommodate different styles and personalized needs. We hope it can grow to serve the burgeoning needs from the communities. FaceChain is open-sourced under Apache-2.0 license at \url{https://github.com/modelscope/facechain}.
DiffSynth: Latent In-Iteration Deflickering for Realistic Video Synthesis
Aug 10, 2023In recent years, diffusion models have emerged as the most powerful approach in image synthesis. However, applying these models directly to video synthesis presents challenges, as it often leads to noticeable flickering contents. Although recently proposed zero-shot methods can alleviate flicker to some extent, we still struggle to generate coherent videos. In this paper, we propose DiffSynth, a novel approach that aims to convert image synthesis pipelines to video synthesis pipelines. DiffSynth consists of two key components: a latent in-iteration deflickering framework and a video deflickering algorithm. The latent in-iteration deflickering framework applies video deflickering to the latent space of diffusion models, effectively preventing flicker accumulation in intermediate steps. Additionally, we propose a video deflickering algorithm, named patch blending algorithm, that remaps objects in different frames and blends them together to enhance video consistency. One of the notable advantages of DiffSynth is its general applicability to various video synthesis tasks, including text-guided video stylization, fashion video synthesis, image-guided video stylization, video restoring, and 3D rendering. In the task of text-guided video stylization, we make it possible to synthesize high-quality videos without cherry-picking. The experimental results demonstrate the effectiveness of DiffSynth. All videos can be viewed on our project page. Source codes will also be released.
Scale-Aware Modulation Meet Transformer
Jul 26, 2023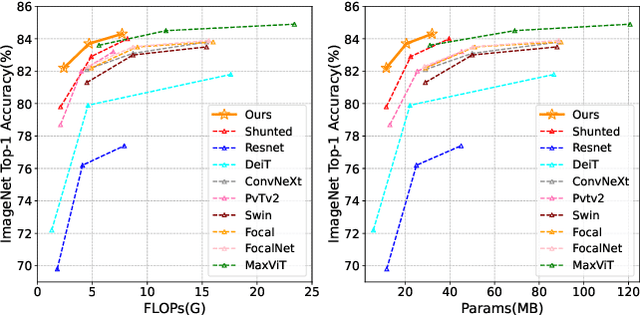
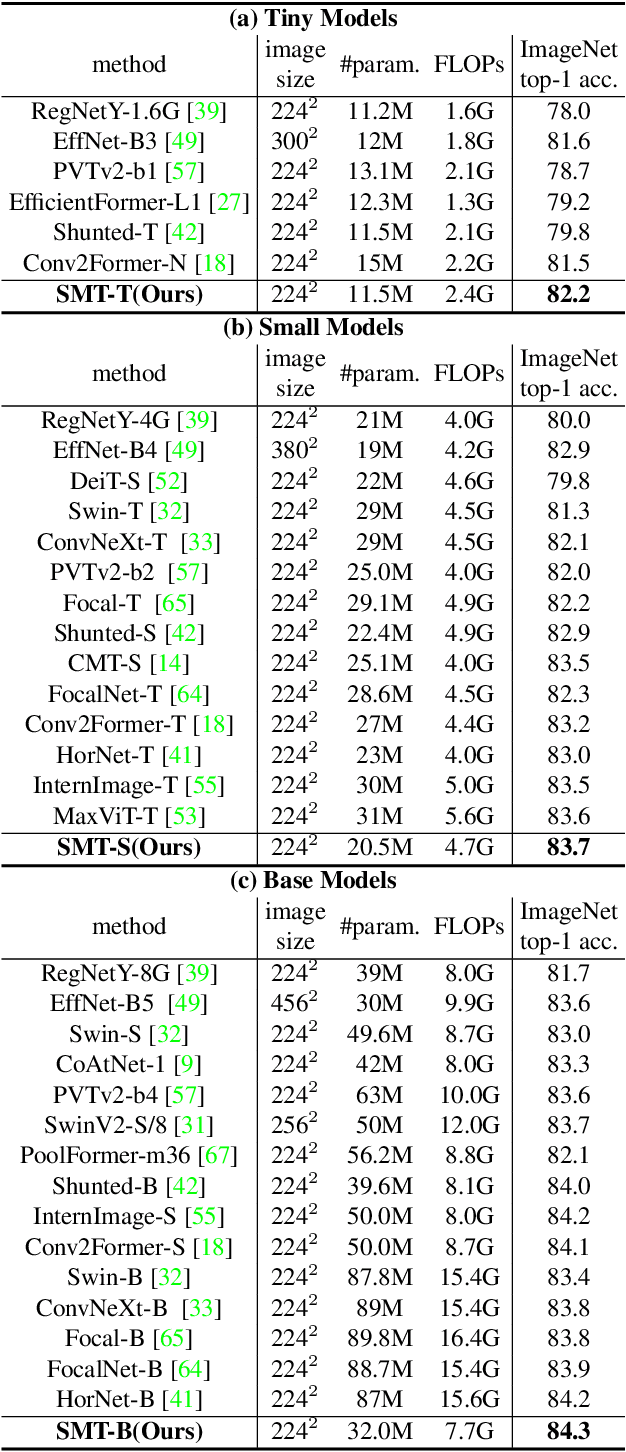
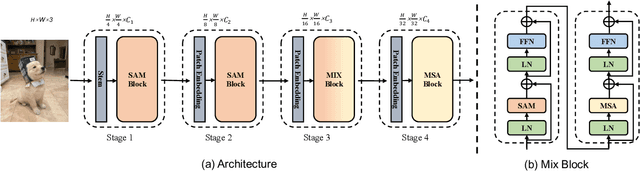
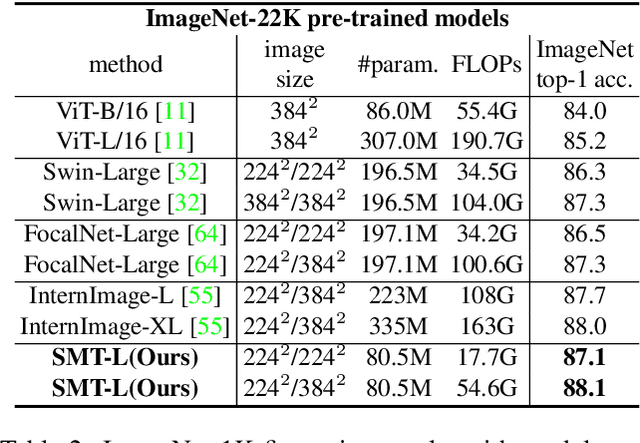
This paper presents a new vision Transformer, Scale-Aware Modulation Transformer (SMT), that can handle various downstream tasks efficiently by combining the convolutional network and vision Transformer. The proposed Scale-Aware Modulation (SAM) in the SMT includes two primary novel designs. Firstly, we introduce the Multi-Head Mixed Convolution (MHMC) module, which can capture multi-scale features and expand the receptive field. Secondly, we propose the Scale-Aware Aggregation (SAA) module, which is lightweight but effective, enabling information fusion across different heads. By leveraging these two modules, convolutional modulation is further enhanced. Furthermore, in contrast to prior works that utilized modulations throughout all stages to build an attention-free network, we propose an Evolutionary Hybrid Network (EHN), which can effectively simulate the shift from capturing local to global dependencies as the network becomes deeper, resulting in superior performance. Extensive experiments demonstrate that SMT significantly outperforms existing state-of-the-art models across a wide range of visual tasks. Specifically, SMT with 11.5M / 2.4GFLOPs and 32M / 7.7GFLOPs can achieve 82.2% and 84.3% top-1 accuracy on ImageNet-1K, respectively. After pretrained on ImageNet-22K in 224^2 resolution, it attains 87.1% and 88.1% top-1 accuracy when finetuned with resolution 224^2 and 384^2, respectively. For object detection with Mask R-CNN, the SMT base trained with 1x and 3x schedule outperforms the Swin Transformer counterpart by 4.2 and 1.3 mAP on COCO, respectively. For semantic segmentation with UPerNet, the SMT base test at single- and multi-scale surpasses Swin by 2.0 and 1.1 mIoU respectively on the ADE20K.